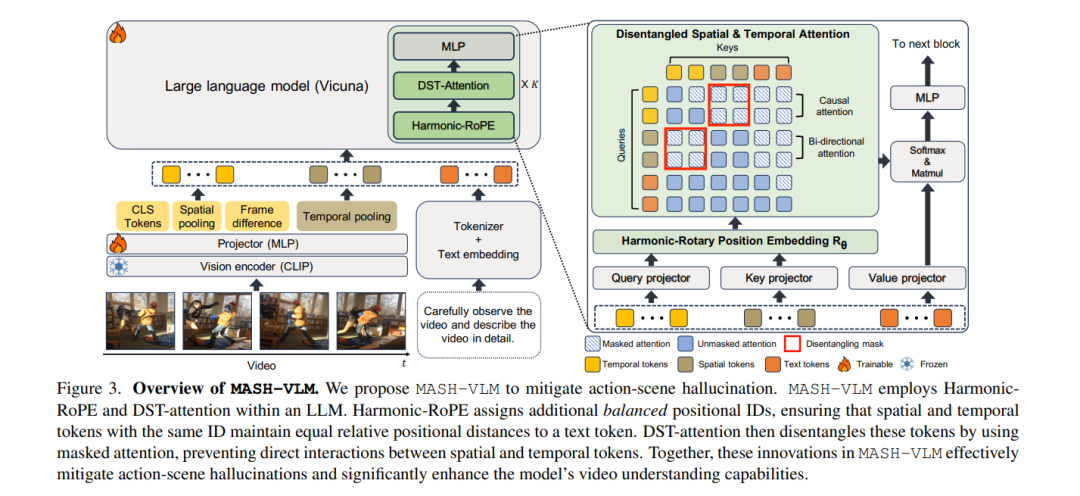
![]() 在本研究中,我们致力于解决视频大语言模型(Video-LLMs)中的动作-场景幻觉问题,即模型基于场景上下文错误预测动作,或基于观察到的动作错误预测场景。我们发现,现有的视频大语言模型通常因以下两个主要原因而出现动作-场景幻觉:首先,现有模型通过对所有标记(tokens)应用注意力操作,将空间和时间特征混为一谈;其次,它们使用标准的旋转位置嵌入(RoPE),导致文本标记过度依赖其序列顺序而强调某些类型的标记。为了解决这些问题,我们提出了MASH-VLM,即通过解耦时空表征来缓解视频大语言模型中的动作-场景幻觉。我们的方法包括两项关键创新:(1)DST-attention,一种新颖的注意力机制,通过使用掩码注意力限制空间和时间标记之间的直接交互,从而在语言模型内解耦空间和时间标记;(2)Harmonic-RoPE,通过扩展位置ID的维度,使空间和时间标记能够相对于文本标记保持平衡的位置。为了评估视频大语言模型中的动作-场景幻觉,我们引入了UNSCENE基准测试,包含1,320个视频和4,078个问答对。MASH-VLM在UNSCENE基准测试以及现有的视频理解基准测试中均取得了最先进的性能。
在本研究中,我们致力于解决视频大语言模型(Video-LLMs)中的动作-场景幻觉问题,即模型基于场景上下文错误预测动作,或基于观察到的动作错误预测场景。我们发现,现有的视频大语言模型通常因以下两个主要原因而出现动作-场景幻觉:首先,现有模型通过对所有标记(tokens)应用注意力操作,将空间和时间特征混为一谈;其次,它们使用标准的旋转位置嵌入(RoPE),导致文本标记过度依赖其序列顺序而强调某些类型的标记。为了解决这些问题,我们提出了MASH-VLM,即通过解耦时空表征来缓解视频大语言模型中的动作-场景幻觉。我们的方法包括两项关键创新:(1)DST-attention,一种新颖的注意力机制,通过使用掩码注意力限制空间和时间标记之间的直接交互,从而在语言模型内解耦空间和时间标记;(2)Harmonic-RoPE,通过扩展位置ID的维度,使空间和时间标记能够相对于文本标记保持平衡的位置。为了评估视频大语言模型中的动作-场景幻觉,我们引入了UNSCENE基准测试,包含1,320个视频和4,078个问答对。MASH-VLM在UNSCENE基准测试以及现有的视频理解基准测试中均取得了最先进的性能。
![]()