

在相互作用的个体或智能体之间出现协调行动是日常行为的一个共同特征。多智能体活动组织的关键在于智能体有效决定如何以及何时行动的能力,而强有力的决策往往是区分专家和非专家表现的关键。在本论文中,我们研究并模拟了人类和智能体在完成各种放牧任务时的行为协调和决策行为。放牧任务涉及两组自主智能体的互动--需要一个或多个放牧智能体来控制一组异质目标智能体。这类活动在日常生活中无处不在,是日常多智能体行为的典型范例。我们首先提出了一套简单的局部控制规则和目标选择策略,使放牧智能体能够收集和控制一群不合作、不锁定的目标智能体。然后,我们研究了所提出的控制过程对牛群规模变化和牧民对目标施加的排斥力强度变化的稳健性。我们还通过 ROS 仿真和使用真实机器人进行的实验证实了建议方法的有效性。然后,我们采用监督机器学习(SML)来预测人类牧民的目标选择决策。研究结果表明,无论是在短(< 1 秒)还是长(> 10 秒)时间尺度上,都可以使用 SML 有效地预测人类行为者的决策行为,而且可以使用由此产生的模型赋予人工牧民 “类人”决策能力。最后,我们利用可解释人工智能来了解人类牧民在做出目标选择决策时所使用的状态信息。研究结果揭示了专家牧民和新手牧民在决策时如何权衡状态信息的差异,这是第一项强调可解释人工智能技术在理解多智能体快节奏互动过程中人类决策标记行为的潜在效用的研究。
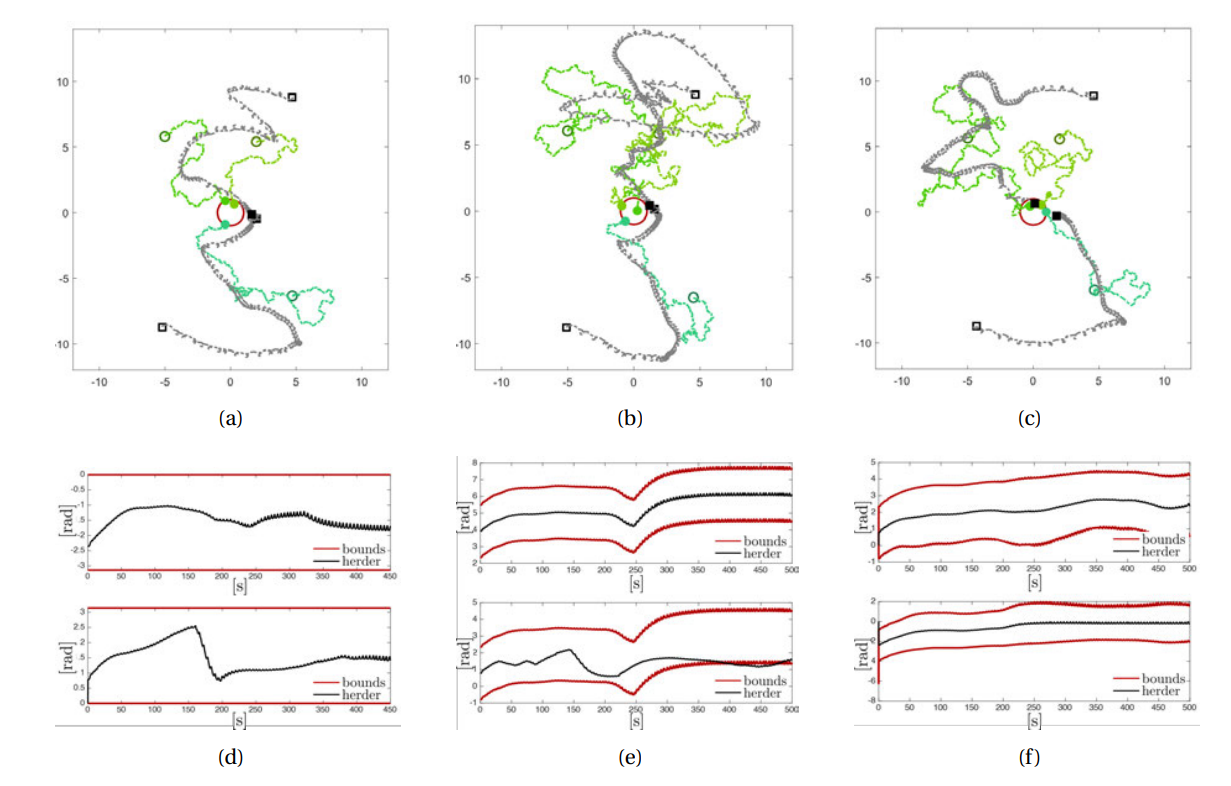
图 3.6: ROS 模拟。顶部面板显示了在 Gazebo 环境中模拟的目标智能体(绿线)和牧民(灰线)采用 (a) 静态竞技场分区、(b) 领导者-追随者和 (c) 点对点牧民策略的轨迹。封闭区域 G 用红圈表示。黑色方形标记表示牧民的初始位置和最终位置(实心色)。绿色圆圈标记表示目标智能体的初始和最终(纯色)位置。下图显示,所有牧民都能按照(d)静态竞技场分区、(e)领导者-追随者和(f)点对点牧民策略规定的角度边界(红线),在 500 秒内收集牧群。

