

导语
********当人们说大语言模型出现“幻觉”(hallucination),是期待它不犯错,还是只能“犯和人一样的错”?如果智能必然意味着具有自主性,那么人们希望一个人工智能系统可解释、可控,是合理的吗?如果人类的悲欢尚且不相通,是否还要期待AI系统完全“对齐”?本文从“智能”是什么,到“人工智能”是什么,再到“通用人工智能”是什么,深入探讨了通用人工智能(AGI)的工作定义、度量方法和研究路线,并从AGI视角辨析了世界模型、大模型幻觉、AI可解释性、对齐、类脑智能等近期人们热议的问题。本文作者是********集智俱乐部「AGI读书会」发起人、天普大学通用人工智能方向博士生徐博文,对于通用人工智能,作者指出,我们与其模仿OpenAI已经做到的事,不如模仿OpenAI的前瞻性。而对AGI的合适的工作定义就像是指南针,在许多“岔路口”处为我们指引方向。
研究领域:通用人工智能,大语言模型,世界模型,类脑智能,适应性
************
目录一、所谓“通用人工智能”究竟何意二、度量智能:“通用人工智能”成为科学的前提三、创造统一的智能理论四、一些问题的辨析
“世界模型”(the World Model) 神经网络的“幻觉”(hallucination) “大模型”之功过 “类脑”之功过 “大数据”还是“小数据” “理解”(understanding) “对齐”(alignment) “失控”与“自主”五、结语****
近两年,由于聊天机器人ChatGPT及其继任者的问世[1,2],“通用人工智能(AGI)”这个既“年轻”又“老成”的领域一跃成为显学,“从‘清锅冷灶’到‘烈火烹油’”,它似乎成了脍炙人口的“标签”。之所以说它“年轻”,是因为这一术语的正式提出仅在18年前(即2006年AGI Workshop上,相关活动始于更早几年)[3];之所以说它“老成”,是因为它并不是一个全新的概念,而是“人工智能”的“初心”(最初含义)和“使命”(最终目标)[3–5]。
虽然学术上[1]并没有声称AGI已经实现(近期OpenAI在与马斯克的官司中也直接否认了这一点),但在巨量的算力和数据加持下ChatGPT让许多人工智能(AI)学者以及公众感到震惊、相信甚至高呼ChatGPT就是第一个“AGI”(例如[6]),同时也存在不少反对的观点,分析ChatGPT等“大语言模型(Large Language Model, LLM)”的特性缺失,例如没有自主性、缺少价值观、缺少“逻辑”推理能力、缺少“世界模型”、缺少“具身性”等等[7–10],相关辩论还在持续,似乎相信“LLM是迈向AGI的一步”更容易让人接受。我想,多数研究者还是对目前的LLM不甚满意并认为仍有大量工作要做。
尽管本文的讨论由近期热议的大语言模型引入,但它并非本文讨论的重点。如此只是因为许多人接触到“通用人工智能”的概念是从大语言模型开始的,有些学者甚至将AGI等同于LLM,然后将任何基于LLM的工作都冠以AGI的名号。本文当然是要打破这种偏见,尽管这不是本文的主要目的。本文主要讨论的是三个更加根本的大问题——通用人工智能是什么?如何测试?如何实现?
这三个问题对应于通用人工智能的工作定义、度量方法、研究路线。定义明确了研究的对象,而度量则是对研究结果的量化,它们是建立科学理论的前提。研究路线须说明如何从定义开始,一步一步地导向最终结果。可以说,定义研究对象和度量其表现是这一研究的“两端”,而二者之间的路线有多种选择(如图 1所示,详细介绍见后文)。
一、所谓“通用人工智能”究竟何意
许多对智能的定义是“拍脑袋”(即仅仅出于直觉)提出的,我也多次犯过这一错误[注释1]。从直觉出发下定义仅是辨析概念的起点,更多的工作其实是在为提出的定义做辩护,即为什么这一特性是不可丢弃的而其他的不那么紧要、为什么这种描述更合理而不采用那种、这里的词语是什么意思而不要模棱两可,等等。由此可见,为AGI下定义很大程度上是哲学问题。给AGI下定义当然不可能一蹴而就。随着研究进行,定义可能被不断修改完善,同时它也指导着研究的方向(因此这里的定义应当被称为“工作定义(working definition)”,参见 [11]对此的相关介绍),不应是“一人一票”的结果。下定义更不是“完全务虚的”无用功,相反,对AGI的合适的工作定义就像是指南针,在许多“岔路口”处为我们指引方向。AGI概念边界模糊的现状的确影响讨论和交流[注释2],但我认为这还是相对次要的。更重要的是,如果我们对研究对象认识不清,那么我们究竟在研究什么呢?
我对AGI的认识应该追溯到五六年前(硕士研一时),而后来对AGI的定义很大程度上受到我的博士导师王培[注释3]的影响。根据他过去40年的研究,他将“智能”定义为“信息系统在知识与资源相对不足时适应环境的能力”,其中“知识与资源相对不足”(the Assumption of Insufficient Knowledge and Resources,简称AIKR)意味着“系统的计算和记忆资源有限(即‘有限性’)、任务只要能被‘表示’就能被处理(即‘开放性’)、任务有时间要求且可能被其他任务打断(即‘实时性’)”。而适应则意味着系统基于过往经验有方向地改变[13]。他长期以来主导研究的“非公理推理系统(Non-Axiomatic Reasoning System, NARS)”[14,15]就是基于这一定义的,且展现出了许多特点,比如“能处理‘无限’的任务”、“能自主生成新任务”、“有自己的价值系统”、灵活性、适应性、自组织,等等,感兴趣的读者可自行了解相关内容[11]。[注释4]王培过去对定义的强调多在“知识与资源相对不足”上,本文中强调的则是另一方面,即“适应性”。我基本认同王培对“智能”的定义,但不认同将此作为“通用人工智能”的定义(尽管在他看来,这个智能定义下的“人工智能”就是指“通用人工智能”)。这也是为什么本文要考虑历史上被提出的诸多定义(例如[16]中被整理出的 七十多条)以及当前AGI社区的(可能)共识,对相关定义做进一步整理,以期规范“AGI”这一术语的使用。当然我从王培所提的定义出发,并非是因为他是我的导师、更不是因为我对他的工作熟悉,而是经过了仔细的甄别,且其中的推论符合我长期以来的观察和思考、十分有价值。
国内可能有影响力的是北京通用人工智能研究院朱松纯的相关论述,他认为通用人工智能应当具有一些“关键特性”,包括“能处理无限的任务”、“能自主生成新任务”、“有自己的价值系统”等,我认为这些是关于智能的正确描述,但不足以构成对通用人工智能的定义(理由见下文)。著名的“Sparks of AGI”论文[1]中给出的定义也被许多人引用,即“AGI是展现出了智能的广泛能力的系统,这些能力包括推理、规划,以及从经验中学习的能力,且这些能力达到或超过人类水准”[注释5],这当然也有合理性,但它对“学习”的强调不够;著名的AI公司DeepMind近期也发表了论文“Levels of AGI”[17]表达它们对AGI的认识,总结来说,他们将“AGI”解释为“在大量问题上(以不必和人相同的方式)解决得像人一样好的机器”(乍看来似乎很有道理,但下文会说明为什么不宜采用这一定义),并呼吁关注“问题求解的效果”而忽略中间的“过程”(即认知功能)。DeepMind的定义算是对过去许多从认知角度出发提出的定义的一种对立(即那些定义通常列举出一系列的认知功能或是特性),同时能代表当下主流的观点。前者(DeepMind)强调了系统的整体表现,但有将研究导向特定问题解决方案的风险;后者(认知功能)强调了内在机制,但有将研究导向分散化的风险(即无法形成统一的理论),可以说现在AI各个“子领域”呈现出的 “各自为战”的特点很大程度上缘于此。
那么,**“通用人工智能”究竟是什么意思?我们首先要认识“智能”是什么,再认识“人工智能”是什么,才能认识“通用人工智能”是什么。后者在前者基础上加一些限定条件得到。**关于此的详细的论述可参考[18],而本文在给出定义后简略说明理由,然后聚焦于相关的推论,最后分析和上述诸定义相比为什么这里的描述更为合适。
|智能
**
**
关于“智能”,我采用的定义为“信息系统利用有限资源适应环境的能力”,此处“有限资源”似乎是一个不言自明的现实约束,但考虑到有些理论假设了“无限记忆资源”(例如传统的计算理论。大概这是源自图灵[19] 的做法),此处将“有限资源”作为理论约束、且与下文“通用人工智能”的定义保持一致。我认为关于“智能”,最重要的一点是“适应性”,这里的“适应性”有两层含义,即“从外部看,以某种评价指标度量,在相对稳定的环境中,系统的表现随经验而提升;从内部看,系统的内部状态有方向地(而非随机地)做出改变”。为什么相对于各种“特点”而言,“适应性”如此重要、以至于不能割舍呢?这是因为,面对各种问题,解决方案是各不相同的,而“适应性”则是那个“不变量”,其强调了系统自己“习得”解决方案的过程[注释6] 。前人的AI研究经验也佐证了强调“适应”的合理性。早期主流的AI研究,许多都缺少了“适应性”。比如,专家系统的问题求解能力主要来源于其“知识库”,而知识库是人类专家(开发者)在系统“出生前”载入的(尽管系统“出生后”其“知识”也可能被人类干预并调整);象棋程序“深蓝(DeepBlue)”采用了暴力搜索的方法,其关于象棋的“知识”是人类“硬编码”到系统中的,以至于许多人感到打败人类棋手的并非计算机,而是编写“深蓝”程序的人类。当人们提出各种“AI应当解决的问题”,并且这些问题真的被“AI”解决以后,人们就不再认为解决该问题的“AI”是“真正的智能”了(即所谓的“AI效应”)。相反,当围棋程序AlphaGo及其继任者[注释7] 在围棋上打败人类顶尖棋手后,人们对它的大多批评集中在“专用性”上,而对其“智能”的质疑则相对较少。这是因为AlphaGo的围棋能力几乎是“自己学出来的”,即经过了“适应”以后获得的,而非人类硬编码进系统的。
这种对“智能”的定义,可以具体到不同对象身上,例如“人类智能”、“动物智能”、“外星人智能”、“群体智能”等等,而“智能”则是这些特殊类型智能的抽象[11]。其中一类特殊的智能形式是“人工智能”。
|人工智能
**
**
定义“人工”表面上看起来似乎很容易,但如果仔细思考,仍有些棘手之处,例如,假设存在某种“生物计算机”,且用“生物计算机实现”的智能体算是“人工智能”,那么“克隆”技术产生的智能体算是吗?后者显然不是我们所追求的、一般意义上的“人工智能”。如果从“可解释(interpretable)”、“可控”等方面来区分,认为“生物计算机智能”是 “可解释”的,而“克隆人智能”则不是,那么现在的人工神经网络也是“不可解释”的,按照相同的标准,其就应当划分在“人工智能”之外了。为了不把问题变得太复杂,这里我的简单做法是将“人工”限定为“计算机(包含其各种形式,至少包含经典的冯·诺伊曼架构计算机、经典的异构计算机、量子计算机、生物计算机等)实现”,并将 “克隆生物的智能”排除在“人工智能”概念的外延集合以外。简言之,“人工智能”是“利用有限资源适应环境的(各种形式的)计算机”。
|通用人工智能
**
**
做好了这些准备,我们终于可以为“通用人工智能”下定义了。基于前面“智能”和“人工智能”的定义,“通用人工智能”定义的得出很简单,只要加上两个限定条件“开放”和“原理”,即
“通用人工智能是利用有限资源适应开放环境且满足一定原理的计算机。”
下面做进一步的解释。目前我认为“开放环境”有两个含义:1)系统的活动被限制在一个相对有限的区域内,超出该区域的情况对系统来说是未知的。因此,主体所面临的环境可能会发生变化(甚至是根本性的变化)。一个直接推论是,未来可能与过去的经验不一致,系统认识到的规律性可能在未来被推翻。2)“开放环境”还意味着对适应对象的约束,即排除针对单个或一组特定问题的“封闭环境”,并且待解决的问题并非预先定义的、也没有明确的边界。
“满足一定的原理”是对系统内部运行机制的约束。这里的定义保持了一定的“模糊度”,即暂且不对“原理”有哪些做清晰的论述,因为这部分尚有争议。例如,从事类脑计算的研究者会从仿生角度来描述(比如STDP学习机制、“赢者通吃”机制等所揭示的抽象原理),心理学和认知科学的学者会从认知功能的角度来描述(例如记忆与遗忘等过程所揭示的原理),计算机科学的研究者可能会从解决问题过程中获得启发并用计算机语言来描述(例如,AlphaGo所采用的MCTS搜索技术所揭示的抽象原理)……总之,过往大量不同定义[16]的分歧之处主要是体现在“原理”集合的描述上,但大多不会拒绝“学习”(即这里所说的“适应”)是一个核心特性。
根据这种解释,在资源有限的情况下,面对开放的环境,智能体的知识和资源是不足的,由此该定义的这部分与王培[13]的定义一致。但[13] 其定义我认为对“AGI”而言稍“弱”了,因为一个系统能“适应”得好的问题或许只有一两个,而其余问题皆无法“适应”,尽管能“被处理”,这样的系统只应被当作“专用智能系统”看待;考虑到不少学者对AGI的“原理”有不少期待,因此对“原理”的强调也有合理性。
在朱松纯(团队)对通用人工智能的特性的描述中[8,20],“完成无限任务” 的论述若要合理,则须小心地解释,否则极容易造成误解。因为,在资源有限(不论多大)的条件下,没有哪个系统能真的去完成“无限”个任务,即使是人类也不能。这里的“无限”应当是“潜在”的而非“实在”的,即那些可以被系统接受的任务就有被完成的“潜在可能”。系统要完成的任务即是“系统的目标”,面对“开放环境”,目标并非“预设”的而是后天获得的。“目标”是系统“价值体系”的源头。这些其实已经包含在“适应开放环境”的含义中了。为了完成目标,适应的过程则须对“目标”进行“派生”。“自主生成新任务”是对“目标派生”过程的描述,放在“原理”部分描述更为恰当。另一问题是,除了这三个特性外,为什么其他特性不是“关键特性”呢?大概许多认知科学出身的研究者不会认同。
“Sparks of AGI”论文中的定义同样列举了一系列的“关键特性”,同时也提及了“学习”能力。若按照本文的定义,“学习”的能力是其中最不可抛弃的,而其他“关键特性”则可放在争议部分进行描述。“Levels of AGI”论文中,其对解决问题能力着重强调了,但是忽视了这一能力的获得过程,而容易把研究导向到“AI效应”的老路上。再者,若按照其中的定义,实现AGI的最佳方式大概就是为各种问题设计专门的解决方案,然后放到一台计算机内运行,这样即使把许多问题解决得非常好,我们对自己的“心智”大概也形成不了多少深刻的理解[注释8]。此外,“解决问题”可以是“适应”的结果,“适应性”的高低最终体现在解决问题的表现上(这与下一节的“度量智能”相关)。相比于“解决问题”,将“适应”放在定义中更具“指导性”。
对于特定问题而言,若我们将其解决方案称为“技能”,那么“技能”的习得是由经验、资源和“智能”[注释9]三者共同决定的。相对于一个系统而言,其“技能”是易变的,而“智能”则是不变的;与环境交互过程中累积的是“技能”,而“智能”本身则“不生不灭”。有人可能会说“计算器”也有智能,只不过是某一方面的智能,因为它体现了人的思维活动(例如四则运算)。我认为这里“计算器”的能力用“技能”来指称更为恰当,毕竟现在我们已经能区分出“技能”和“智能”的不同。
当然,此处花了大力气来辨析定义,目的并非要争个谁对谁错,而是给读者呈现我认为对“(通用)智能”的更究竟的认识,或者说,是在读者的脑海中建构出“那个概念”;至于用什么词语去称呼它,已经不那么重要了,正如禅宗所说“以手指月、得月忘指”。
前面对“智能”的定义算是比较宽松的,目的是将过往机器学习的诸多工作纳入到智能研究的范畴内,但注意,在这个定义下,一个典型的机器学习系统只在训练阶段体现出智能、而在测试阶段不体现智能,因为测试阶段的机器学习系统虽然有泛化能力但通常没有适应性。实际上,“真正的”智能应当指的是前文AGI定义所涉及的智能,即“通用智能”。为描述方便,下文中所说的“智能”皆是指 “通用智能”。
二、度量智能:
“通用人工智能”成为科学的前提
尽管通用人工智能的理论本身的优劣需要评价[21],本文所讨论的度量集中在对系统表现的评价上。近年来机器学习领域的快速进展,部分可归功于“测试基准(benchmarks)”的建立,它直接帮助了不同研究者量化比较他们的模型设计,但在AGI的研究中,“测试基准”的使用则须十分小心。
以往的常见思路是从心理学中评价智能的方式出发,通过类似“智商测试”题来度量计算机的智能。还有通过各种针对性的任务来测试某项能力,然后评估其在各个认知能力上的表现,比如有人就曾提出“智能奥林匹克十项全能”的思路。这些度量思路用在人的身上都没问题,但不适合用在机器身上。这是因为,常常被忽略的是人解决特定问题的能力不是与生俱来的,而是有一个习得过程,即经过“适应”习得“技能”。然而,对于机器而言,其解决问题的能力未必需要一个习得过程,而可以通过开发者“硬编码”的方式获得,这对于AGI的评估而言算是“作弊”了。即便动态生成无限的任务(比如DeepMind的“XLand”虚拟环境),只要任务提前被开发者获悉,就能够利用开发者自己对任务的知识来提高分数。完全不让研究者看到任务也是不合理的,毕竟度量AGI的目的是衡量研究进展、启发未来研究,如果研究者对系统表现的产生的原因一头雾水却无法查看原始数据,就达不到这个目的了。也有人想过测试时开发者看不到题目,测试结束后可以开放题目,但题库需要不断更新(比如肖莱(François Chollet)主张的抽象推理问题库(ARC))。且不论不断更新题库的人力成本,这么做仍然不能完全避免开发者“猜题”的可能性(想想不少考生通过寻找出题人的出题规律来押题)。这些方案都不能避免“作弊”行为,这也是为什么一个“公平”的AGI测量基准如此之难设计。当然,这不是说不能用特定的任务来测试AGI系统,这么做是有前提的。在我看来,评估通用人工智能系统的表现,包含如下三种方式:
1)接受现实世界的检验。我们希望创造思维机器并将它们实际应用于现实世界的生产实践中。这可以说是AGI系统的“终极大考”。然而,就AGI的研究而言,这种检验的弊端包含两方面。一方面,这种方式的成本高,不论是时间成本(“教育”一个智能机器人需要大量的时间)还是经济成本(智能机器人可能损坏)。另一方面,通过这种检验方式很难进行“公平”的比较。机器人解决问题的能力(即“技能”)不仅可能来源于其自身的“智能”,还可能来源于人类开发者的经验;其可能只能适应一些特殊场景、而无法适用于一般的场景,但若没有经过足够的时间检验有时则很难发现。这些专用性基本来源于智能原理上的缺失,但关于应用场景的特定知识往往可以补足其在特定问题上的表现,然而,机器在这些场景应用范围以外就很可能难以招架了。[注释10]
2)在“开放人工世界”中比较不同系统的相对表现。也就是说,创造一个虚拟世界并让智能体在其中活动。该世界是“开放的”(即上文所说的“开放环境”),所以人类经验在其中就无多少用武之地了。虚拟世界的时间流速可以高于现实世界,这种检验方式还可以很大程度上避免人类关于特定问题的经验的干扰,所以它一定程度上避免了上述现实世界检验的两个弊端,相关概念设计可参见[22]。尽管如此,这种方式也有不足之处。一方面,它和现实世界一样对智能体的“完备性”有一定要求,也就是说,在研究到一定程度之前,中间阶段的进展很难通过这(两)种方式来评价。另一方面,这种“开放人工世界”由于通常超出了人类经验范围,除非经过一段时间的适应,否则难以被人类理解。
3)使用特定问题来评价,前提是小心检查其中的理论预设。这就是采用类似于传统机器学习的评价方式,提出一些特定问题作为“测试基准”。这种评价方式的好处是灵活,即可根据研究阶段有选择性地进行测试基准,用于衡量阶段性进展。然而,其弊端也十分明显,开发者容易针对特定问题做过度优化、导致其理论模型的适用范围局限于特定问题,甚至不惜代价引入关于问题本身的知识,这些知识不是机器自己习得的、而是人类习得的。注意,有时开发者为解决问题所引入的知识是隐含的、不经意的。根据前面的定义,这种做法已经严重偏离研究目标了。这种开发者的经验而非机器自己的智能导致在特定问题上表现良好的现象可以被概括为“开发者经验陷阱”[22]。因此,在用特定问题作为测试基准时,须十分小心地检查其中的理论预设是否有“问题特异性”。值得注意的是,“不论多么小心地选择测试问题,都有将研究导向问题特定的解决方案的风险”[21] 。
根据前面的定义,对于AGI而言,“智能”的“量”就不能仅仅通过“准确率”或“得分”的最终值来计算了,因为如果缺少了“适应性”就谈不上“智能”。我目前认为这个量的计算至少得从三个因素进行综合考虑,即 “适应速度”、“适应优度” 、“泛化优度”[22]。直观上说,如果智能体在某一时刻的表现可以用一个数值来表示,那么“适应速度”指示了该值的变化率,“适应优度”则是在环境相对稳定的前提下该值收敛到的结果,而“泛化优度”对应于环境发生一定程度“变化”后系统利用既有经验直接应对新环境的表现。[注释11]
之所以度量智能如此重要,不仅是因为不同的AGI系统需要一个“公平”的、共同的标准来相互比较,更是因为它是AGI成为成熟的“经验科学”的前提。许多对智能现象的解释都须要借助计算机的平台来“证伪”。如果没有一个衡量指标,每个AGI各自都有自己的形式化理论,即使可以将其称为“数学”或“形式科学”,这些理论的正确性也难以客观评价。
总结来说,人工智能研究与以往的心理学研究不同,它不仅要求解释智能现象,还要求用计算机来实现模型和评估其(解决问题的)表现。对智能理论的检验是通过对基于该理论开发的人工智能系统进行测试来进行的。与典型的机器学习范式不同,对AGI系统的测试和度量则有更进一步的要求。
三、创造统一的智能理论
虽然本文并没有直接给出研究AGI的路线图,但本文要讨论一个“元问题”,即如何设计AGI的研究路线。这里不直接给出路线图的原因并非出于“保密”[注释12],而是出于本文“正确性”的考虑:科学研究是无法规划的,即便是一份粗糙的“AGI研究计划”也很可能会在未来研究中不断被调整[注释13]。相反,如何设计与调整AGI路线图则更具一般性、可以为更多AGI研究者所借鉴。下面要给出的通用人工智能研究框架(如图 1所示)是从现有的许多研究中归纳出来的,我相信它对指导未来研究会有一定帮助。
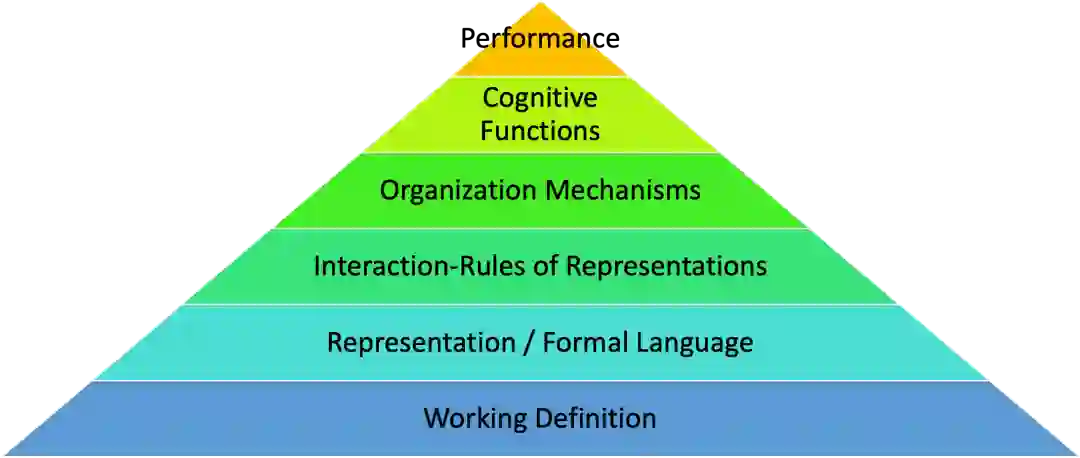
图1. 通用人工智能研究框架
不同的AGI研究常采用不同的对“(通用)智能”的工作定义,多数情况下其强调的内容不同,某些情况下甚至相互冲突——大多数定义都不否认智能体应当有“学习”能力,尽管有些定义将其与一系列其他许多特点放在一起谈,而有些定义则将“学习”(或“适应”)作为核心;一种定义是认为智能是“解决(复杂)问题的能力”、即便没有“学习”过程也可,它则与本文提出的这类定义强烈冲突,且不适合用作AGI的定义。注意,它对系统“表现”的强调并没有错,即我们希望系统最终应当解决好复杂问题,它错在没有认识到系统的问题求解能力有一个“习得”过程。
有了工作定义以后,为了创造一个符合该定义的系统,我们须要建立形式化模型并用计算机实现——首先,确定所采用的形式化语言(对人而言)或称“知识表示”(对机器而言);其次,确定表征(即知识表示的具体内容)之间“相互作用”的规则;最后,设计将局部的表征相互作用组织为系统整体的“组织机制”。
不同的AI研究常采用不同的形式化语言/知识表示,常见的包括神经表示、向量表示、概念表示、概率表示等——
- 神经表示:例如在神经形态计算中,人们使用诸如脉冲、膜电位等概念来表示系统的内部状态。
- 向量表示:例如在深度学习中,人们使用线性代数和微积分作为数学基础,知识用向量/张量来表示。
- 逻辑表示:在推理系统中,人们用逻辑语句来表示知识。
概率表示:例如在贝叶斯网络中,人们以概率论作为数学基础,每条知识用一个事件的概率来表示。
对于AGI的研究而言,任何形式化建模都须要从选择一个形式化语言开始,而所选的形式化语言与它所囊括的“表征相互作用原理”密切相关。所谓的“表征相互作用原理”,规定了表征之间哪些变换规则是有效的。例如,基于概率表示的一个规则是贝叶斯定理,概念表示则对应于各种逻辑规则,向量表示对应于人工神经网络两层之间的前向传播与反向传播的计算,而神经表示涉及到脉冲神经元的激活规则和突触STDP学习规则等。
组织机制确定了系统作为整体如何一步一步地处理输入信息和输出动作。比如,贝叶斯网络中,系统先验概率的更新(学习)和后验概率的更新(推理)是根据网络的图结构传播的;非公理推理系统中的“推理控制机制”用于将单步推理组织起来,改变其中概念网络的结构、更新信念的真值等;人工神经网络中,其结构通常是预先设定的,其组织机制则是将信息沿着网络连接的路径进行逐层的前向和反向传播,并修改连接的强度(权重);常见的脉冲神经网络的学习机制与此类似,也有脉冲神经网络(如HTM)在运行时按照一定的组织机制修改网络的结构。
有了“智能模型”以后,检验“正确性”的方法则是检查其“解释力”和“表现”,即它如何解释已经存在的各种智能现象(体现为认知功能),以及它学习解决具体问题的效果。
实际上,图1中的顶端是对工程性的要求,而下方其余部分则是对科学性的要求。在硕士研一时我的导师任全胜[注释14]曾问我为什么非得做“通用人工智能”的研究,而不选择其他“更重要”的课题。当时我“想破了脑袋”才发现,研究动机说到底就是如下两个:1)出于对“(通用)智能”的强烈好奇;2)解放人类脑力劳动。后来我意识到,前者要求我们建立“‘通用智能’的理论”(科学性),而后者要求我们创造“通用人工智能”(工程性)。不同的研究者的动机基本是这两点的平衡。极端情况下,有人仅追求工程目标而完全抛弃了科学目标(例如现在的许多深度学习的研究者,当然不是全部),而有人仅追求科学目标而完全抛弃工程目标(如传统的心理学和认知科学的许多研究者,当然也不是全部)。我认为,做AGI的研究应当 “首尾兼顾”,而倾向于哪一端则决定了不同研究的“风格”。
总而言之,设计AGI的路线图,就是要明确工作定义,然后选择形式化语言、明确表征相互作用原理、设计组织机制,将所创造的智能模型用于解释已知的智能现象,最后评价该系统的表现。本文一定程度上明确了AGI的工作定义,并说明了评估AGI的三种可选方式,而具体的AGI研究的不同则体现在中间四个层次上。有的路线过于注重系统的表现而缺少理论辩护、放弃对智能现象的解释[注释15]、有的路线过于注重对智能现象的理论解释而放松对系统表现的要求[注释16]。有的工作将智能视作多种(认知)能力模块的集合、通过认知架构集成在一起;而有的工作将智能视作统一体、不同(认知)能力只是不同的观察视角和描述方式。路线中各个环节的具体抉择不尽相同,说哪个更加“正确”仍为时尚早。尽管如此,在我看来,工作定义、知识表示、作用规则、组织机制、现象解释、表现评价,不论缺少了中间的哪一环,这场关于心智的科学-技术革命都不算走到头。
四、一些问题的辨析
下面将根据前文所呈现出的“智能观”,在AGI研究的视角下讨论若干近期被热议的问题。
“世界模型**”****(the World Model)**
杨立昆(Yann LeCun)近年一直力推“世界模型”[7],即一种世界的“模拟器(simulator)”,用于估计(补全)感知中缺失的信息以及预测世界的未来状态。这种观点似乎很容易理解和想到,毕竟,传统AI研究中“搜索”技术常常建立在对环境状态“全知”的前提下,或是通过“探索”来补全缺失的信息、形成对环境状态的“正确”描述,从而能够利用“搜索”技术进行处理。(参看:《什么是世界模型?为什么Sora不是 world simulator?》)
在这里我想区分对“世界模型”的两种可能理解:1)对环境(局部或全局)状态的唯一正确描述;2)关于环境的知识或信念(belief)。二者的区别在于,前者隐含了存在一个“客观(唯一正确)”的描述,而后者中知识或信念是“主观”的。不同智能体(不同人类个体、不同物种)心中对环境的认识几乎都不相同,差异主要来源于其感知运动接口(感受器、执行器)以及个体独特的经验,哪一个算是“正确”的描述呢?某种意义上它们都是“正确”的,并不存在一个“唯一正确”的描述,要对环境中的所有细节进行模拟容易让人误认为有一个“唯一正确”的描述。[注释17]二者都能起到杨立昆所说的“世界模型”的作用(补全、预测),但其哲学立场则是天差地别。一方面,神经网络的方法天然地符合第二种理解,即每个神经网络的权重都是关于“环境”的主观的(隐含表示的)“知识”;另一方面,许多人却采用了第一种理解,希望它能“丝毫不差”地“模拟客观环境”。同时采用两种矛盾的哲学立场则导致具体研究过程会让人感到“拧巴”、别扭。
对于AGI的研究而言,采用第二种理解更为恰当。因为根据前述对AGI的定义,对环境的绝对正确的预测既不可能也没必要。但同时,在这个理解下,“世界模型”就并非什么新奇的概念,只不过是为旧的概念(关于环境的知识)换个标签罢了。要适应环境(在其中学会完成任务、解决问题),智能体须要习得关于环境的知识这一看法是显然的。困难之处在于对这些知识的具体组织方式上——智能体应当如何处理大量的来自环境的输入、如何组合与抽象、如何与既有知识建立联系和修正既有知识(即皮亚杰(Piaget)所说的“同化-顺应”)等等。
神经网络的“幻觉**”****(hallucination)**
大语言模型的“错误”其实不是幻觉,大语言模型的输出某种意义上说并没错。
经常有人提大语言模型的“幻觉(hallucination)”,依据是它“不经意”出现的各种错误。希望大模型不出现“幻觉”,其对应于三个可能的目标:
1)在特定数据集上不犯错。神经网络在数据集上的准确率通常很难达到100%,但这仍是一个可追求的目标。然而,对于AGI而言,特定数据集上的表现并不代表其“样本外泛化”的能力。它不是解决幻觉问题的根本途径,尽管能一定程度缓解。
2)可以犯错但要“犯和人一样的错”。这一要求表面上看似合理,但仍须仔细分析。正如图灵1950论文中所提到的,机器为了在行为上假装像人,它不得不在运算问题上故意放慢速度、故意给出错误的答案。这是荒谬的,刻意模仿人类的错误也是没有必要的。合理的认识应当是希望它内部的运行机制与人的心智有相似之处,以至于自然会犯和人类似的错误。然而,神经网络本身的行为主义立场(只对输入输出做约束)与对内在运行过程的要求是相冲突的,尽管这种冲突可能一定程度上通过设计特殊的网络结构来缓解。
3)通过规范性理论的辩护,让机器合理地犯错。该目标则是要求完全打开“黑盒”、建立规范性理论。这要求模型的“可辩护性”而不仅仅是“可解释性(explainability)”(详见下文),并将很可能导致与现有的神经网络完全不同的理论路线。在这种模型中,其所犯的错误并不与人类表面上完全一样,但有其合理性。
我认为第一个目标不适合AGI研究,因为AGI系统要应对的是开放环境。第二个目标体现了一种人类中心主义的傲慢,因为神经网络有它自己的学习方式,在人类看来的错误对它而言却是合理的。当有一千个大模型产生相互一致的输出,却只有一个人说“你们都错了,事实应当如何如何”,那么到底谁才是出现幻觉的那一方呢?[注释18]第三个目标更为合理,但此时,神经网络的“幻觉”实际上是应该叫 “错觉(illusion)”(人的认知过程也充满“错觉”,尤其在各种视错觉图片中体现),它的出现自有其原因,虽然在人类看来是错误,但在神经网络自己看来却是正确的。要解决“幻觉/错觉”问题,实际上需要的是智能的规范性理论。
可解释性
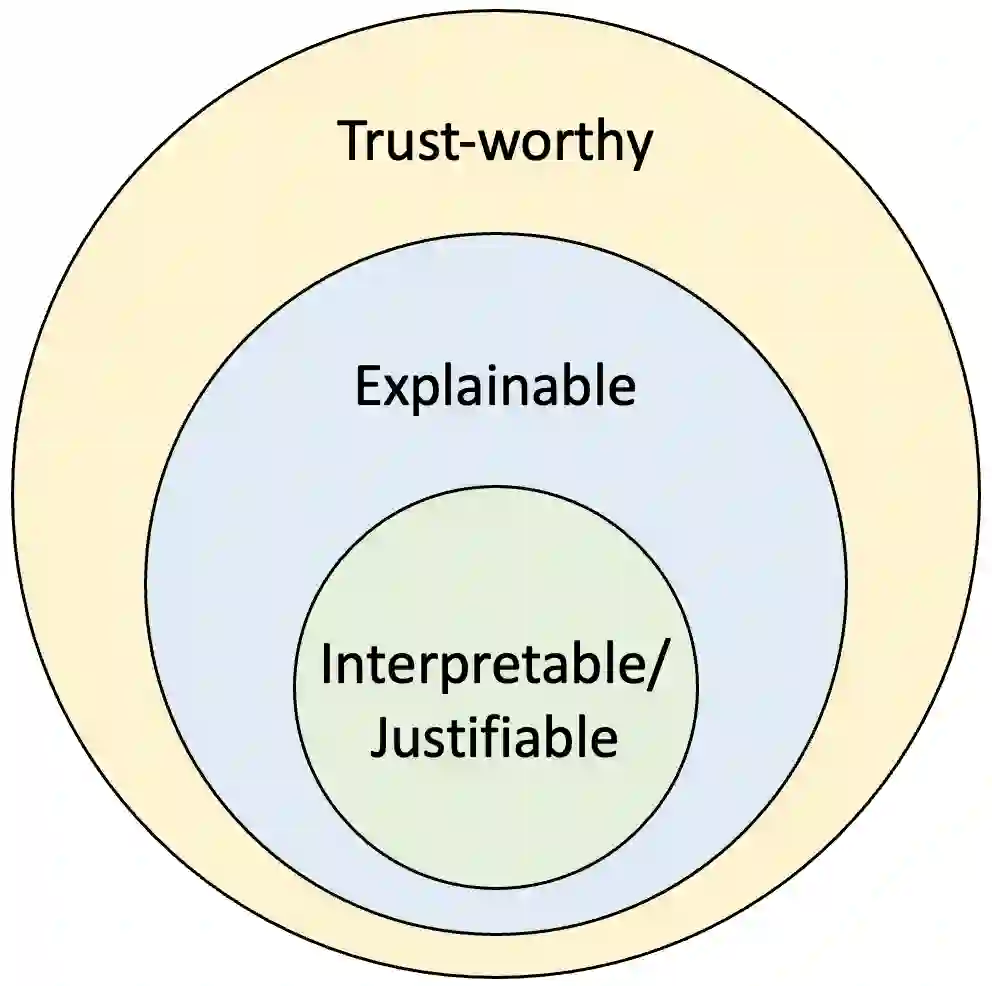
图2 可信赖、可解释、可辩护三者之间的关系
可解释性的需求可以说一部分是源自“深度学习”不可解释的特点。传统的许多方法其实都是可解释的。但这一问题仍然十分有趣——为什么人们希望一个人工智能系统是可解释的?似乎一个可解释的系统更加“安全”、更加“受控”。然而,“不可控”和“自主”可以说是同义词(不管贬义还是褒义),一个真正的智能系统必然是自主的(不完全可控的)。**此时可解释性不再是安全和受控的必要条件了。我认为“可信任”才是恰当的要求。**一个可解释的系统一定是可信任的(相信它能完成或不能完成某些任务)。
我们本质上是希望一个机器(智能体)**能够取得人类的信任,其中的一种手段就是“交互”。**而可解释的系统可以跳过这一交互过程,因为人们总是能通过解释机器的输出,来为其行为寻找恰当的理由,预知在什么情况下其行为是不可信的。
还有一类系统我把它称为“可论证(justifiable)”的,它基本等同于“interpretable”,但有些文献中“interpretable”与“explainable”两个概念被混用了,所以这里才换了一个词进行指称。
**“可论证”**的系统可以跳过“解释”的过程。“可论证”是说系统中的每一个步骤都有恰当的理论依据,和“可解释”系统“事后对其行为找理由”相比,“可论证”系统则是“事先为行为找理由”,即每一个行为都有可以从理论中一步一步推出、论证其“合理性(rationale)”。一个“可论证”的系统必然是“可解释的”。一些“可解释”系统虽然某些情况下能产生合理的结果且能够解释其原因,但某些情况下结果可能错得离谱,这主要是因为其中的某些步骤本身不合理、缺少足够的理论辩护(justifications)。因此“可论证”算是三者中要求最高的,但不论是哪类系统,在使用者不了解其底层原理的情况下,都要通过交互来取得信任。
“大模型”之功过
“大模型”虽然有时被诟病为“暴力美学”,但它仍有其合理之处。正如前文提到的,决定“高技能”的三个因素是“智能、资源、经验”,在模型设计固定后,增加系统的“资源”和“经验”便是提高其“技能”的必要手段。
然而,“大模型”忽视了AGI研究中最重要的部分,即“智能”。这里并不是说“大模型”完全错了,相反**,“大模型”给我们上的重要一课,就是所设计的智能模型须有“伸缩性**(scalability)**”,即可通过扩大“资源”和“经验”的规模来达到“高技能”。**对现有大模型的诸多批评实际上是对将注意力回到“智能”模型设计上的呼吁,毕竟模型设计上的缺陷是无法通过扩大资源和经验来完全弥补的。
“类脑”之功过
我最开始进入AGI的研究时,也曾坚定抱有这一信念,即认为只要研究清楚一个神经元,再将它们连接成网络,其就能“涌现(即不知怎么地出现)”出智能。这对应的研究领域准确说是“神经拟态计算(neuromorphic computing)”。但后来我逐渐认识到这一信念的局限性。一方面,我们不可能无限精细地模拟大脑,因为模拟既然存在偏差,这种“涌现”就是不能保证的。另一方面,对于AGI研究而言(根据本文中的定义),精细模拟大脑不是必要的。在通过模仿脑的结构构建智能系统时,我们不得不对神经元进行建模,即“抽象”,换句话说,就是选择性地保留和丢弃一些细节。过于看重对生物细节的模拟,则可能会偏离AGI的研究目标。比如,一种观点认为“AI只是计算神经科学研究的一个副产品”[23],这恰好体现了“研究目标”的不同:类脑计算可以给神经科学和脑科学带来很好的成果,它与人工智能的研究目标有交集但不完全相同。这也是为什么本文中花了很大篇幅讨论“AGI是什么”,可以说对AGI的定义就是研究旅途上的指南针。
尽管如此,类脑计算对AGI研究而言仍有重要价值,且是实现AGI的可能途径之一。人脑结构是长时间自然演化出来的、实现“(通用)智能”的重要参考,现有的AGI项目或多或少是“脑启发**”**(brain-inspired)的,我们或多或少可以借鉴人脑的结构来设计AGI系统,同时要注意,每当借鉴了脑的结构,都须要给出所采用的结构背后的理性原则(而非仅仅出于与脑的结构相似性),毕竟大脑中有大量和智能不直接相关的生物细节。
“大数据”还是“小数据”
这其中有一段有趣的辩论。一方认为,应该继续采用“大数据、大算力、强算法”的路线,并拒绝探索“通用智能”的理论[24];另一方则认为,应当采用“小数据、大任务”范式,强调智能体应当像“乌鸦”那样能够“自主推理“,而非像“鹦鹉”那样“简单模仿”[25,26]。二者分歧在于对数据量的强调,即“大数据”还是“小数据”上。在前者看来,深度学习(“强算法”)的问题求解能力(即本文中所说的“技能”)是建立在“大数据”的基础上的,并排斥“小样本学习”。而根据后者的观点通过“乌鸦范式”用“小数据”就足矣,因为通过少量样本“乌鸦”就能完成好任务。一个遵循智能原理的“智能体”应当要用很少的数据就能完成某些在人看来简单、在机器看来困难的任务。我同意“小数据,大任务”的一部分观点,并认为大数据并不能完全弥补模型的某些缺陷。然而,我要强调的是这个观点有一个根本的局限性,很容易误导人入歧途。
我的观点是,两者都不完全对,前者说对了前半句话,后者说对了后半句话,即正确的认识应当是“大数据,大任务”。
我们当然希望计算机能够服从“智能的原理”,做一些创造性的劳动。但同时,很容易被忽视的是,“小数据”往往对应着“大先验”,这个“大先验”可能是机器从大数据中自己学出来的,也可能是人类将自己的经验直接写入、形成机器的先验。也就是说,完成“大任务”时,可能是由于人类引入了自己对问题的解决方案或先验知识,才导致用很少量的数据就能完成任务(这一情形可称作“开发者经验陷阱”[22])。 一方面,一昧追求“大任务”,非常容易掉入了所谓“开发者经验陷阱”中。大数据是不可避免的,设想一个人类婴儿的成长过程。人真正能着手进行一些重要的工作通常要成长到二三十岁,即便是完成儿童能做的“简单”的“大任务”,成长过程也已经积累了大量的经验。
另一方面,一昧追求“大数据”,则容易忽视对“智能”而言真正重要的问题。人须要从大量数据中总结经验,但不意味着大数据是唯一要追求的目标。一个符合智能原理的“智能体”,应当有较高的“学习效率”,以便于在积累大量的经验以后,可以从很少的数据就“泛化”到许多场景;“小数据”的立场看到了这一点,但却忽视了从“大数据”中学习的过程。
“理解”(understanding)
对AI系统的常见的质疑是其是否真的产生了“理解”。比如著名的中文屋问题(the Chinese Room Argument)中,一个符号系统虽然能够产生中文语言输出,却对中文没有任何理解(这也是常被提及的“符号接地问题(the Symbol Grounding problem)”)。
当神经网络产生离奇的错误时,人们也常质疑其是否有“真正的理解”。比如,当一个神经网络在人类肉眼难以分辨的噪声的干扰下,将熊猫识别为鸵鸟,人们便认为神经网络没有真正理解这张图像,而只是学到了一些“相关性”。这些问题都指向了“‘理解’是什么意思”这一问题。
一种观点是“理解即正确预测”,我曾经也认同这一观点。的确,“正确预测”是“理解”的一种可能表现,但现在我认为它不是“理解”必要条件,也就是**“理解”并不蕴含“正确预测”**。即便我们对一个事物产生理解了,也可能导致错误预测(这常常是由于缺少观察、思考不充分等因素导致的)。也并非所有的“理解”都与“预测”直接相关。尽管在深度学习的语境下,“神经网络”的输出过程常常被称为“预测”,但一般语境下预测包含了时间性,即系统推测出一个事件未来的发生,而有些关系(比如范畴关系,如“天鹅是一种鸟”这句话中“天鹅”和“鸟”之间的关系)严格上说并非预测关系。
在我看来,如果将各种不同的表示都统一转换为概念化表示,那么“理解”就是建立概念的含义,(根据“基于经验的语义学”[27])即建立起概念与其他概念之间的联系。一个概念的含义越丰富(即与其他概念的联系越多),我们对其的理解程度也越大,尽管理解可能“出错”(即导致行为的“负面反馈”)。也就是说,“理解”既有程度问题也有正误问题,对一个事物的理解程度随着经验积累逐渐增加,并且可能产生理解的偏差甚至错误。在中文屋的例子中,屋内的“人”对中文同样产生了“理解”,只不过这种“理解”多是“字面”上的、主要是与英文的对应关系。“错误的理解”仍然是一种“理解”:而神经网络也对图像产生了“理解”,只不过它独特的“理解”方式和结果与人类的不同。我们怎么能说只有人类的理解是唯一正确的呢?何况不同人对同一事物产生的理解可能完全不同、同一个人对同一个事物的理解也可能随着时间改变。
人与人之间对同一事物的理解存在差异,这主要是由于个体独特的经验导致的。比如,不同人对“智能”这一概念的认识差异就很大,每个人都有自己的“理解”;即便对于一个具象的物体,“理解” 也存在个体差异,比如盲人认识到的“苹果”与常人认识到的就不可能相同;更不用说不同物种的个体对同一事物的理解,比如蝙蝠利用声波感知的结果不可能与人的完全一样。
从这个意义上说,大语言模型既形成了自己对“语言环境”的理解,又和人对世界的理解不同。
“对齐”(alignment)
不同个体对同一事物有不同的理解,在交互过程中仍然能一定程度上“对齐”各自的理解,即推测或询问对方心中某个概念的可能含义并将其纳入到自己的概念系统中。尽管如此,概念含义的“对齐”只是程度上的,对AGI而言,完全的“对齐”既不可能也没必要(正如所谓的“人类的悲欢不相通”)。
在我看来“价值对齐”是一种特殊的概念对齐的过程,也就是不同个体中交换其与“目标”相关的概念的含义,从而互相“理解”各自的“目标”。相同语词描述的目标在不同个体之间仍可能有较大差异,比如婴儿可能难以理解“家国天下”的目标,美国人可能难以理解“中国梦”。对于AGI而言,各个具体“目标”的含义是习得的,个体之间通过交流等方式能够实现一定程度的“价值对齐”,并在此基础上进行“团队协作”。
“失控”与“自主”
曾经有一段时间我也希望所研究的AI系统能完全听命于人类(类似于“管家”或“奴隶”),但后来放弃了这一目标。“失控”和“自主”是同义词,如果我们真的希望一个系统是“自主”的,那么就不得不放弃“完全可控”这一目标。从现有的AGI相关工作中[11]已经能想象到,一个真正的人工智能系统不会是完全可控的,正如同一个“孩子”不能完全被“家长”控制一样。要求这样的AGI系统完全听命于人类从理论上讲就是不可能的。尽管如此,我们仍然可以通过合适的“教育”来约束这些系统的行为。
五、结语
当前“(通用)人工智能”重新获得了大众的关注。与以往不同,这次以此为名的人工智能技术已经对社会生产实践发挥了重要作用。这点燃了许多研究者对AGI的研究热情,同时也造成了不少的误解。本文是消除误解的一次努力,更是对AGI定义、度量方法、研究路线的一次总结,并在AGI研究的视角下分析了一些热议的问题。
我不隐瞒自己的观点,并乐于将所探索到的路线与所有人分享。这是因为“真正的”人工智能(不论是叫“通用人工智能”、“人类级别人工智能”、“超级人工智能”还是其它)既是未来国家间科技竞争的战略制高点,也是人类文明进步的关键一环。它的出现,将伴随着脑力劳动的彻底解放;与此同时,人类将第一次面对来自与自己智慧相当的另一“(机器)物种”的挑战,社会秩序或将因此发生根本性的变革。它既可能是人类的福音,也可能是“潘多拉魔盒”,未来它的出现却似乎有着某种历史必然性。这一研究在目前阶段主要面临的不是工程问题而是科学问题、很大程度无法被规划(已经有诸多做此尝试的负面例子),但我似乎能预见,这一对人类文明将产生深远影响的研究不太可能在几十年内完成,很可能需要几代人的接力,几乎每个严肃研究此问题的学者当前似乎都须做好“功成不必在我”的心理准备投身这一事业。研究通用人工智能既不像“打篮球” (追热点)、也不像“下围棋” (做规划),它更像是一场修行——一场寻“心”之旅。它是一场科学的旅途,与以往的物质科学截然不同,它更多是认识“自己”的研究。
我们与其模仿OpenAI已经做到的事,不如模仿OpenAI的前瞻性。对每个AGI研究者(即“个体”)而言,我们应在充分了解前人工作的基础上独立思考、慎重选择自己的研究路线;在国家(即“群体”)尺度上,除了布局基于现有技术的“大模型”,我们不能仅仅做一些亦步亦趋、拾人牙慧的科研,而应包容多种可能的理论和技术路线,高瞻远瞩、敢开先河。
我相信,或许在未来,也许是本世纪末,人们可以在谈论“人工智能”时不必强调其中的“通用”二字而不会引发歧义。借用图灵的话说,“我们的目光所及,只是不远的前方,但是可以看到,还有许多工作要做。”
学者简介

参考文献[1] BUBECK S, CHANDRASEKARAN V, ELDAN R, 等. Sparks of Artificial General Intelligence: Early experiments with GPT-4[M/OL]. arXiv, 2023[2023-10-02]. http://arxiv.org/abs/2303.12712. DOI:10.48550/arXiv.2303.12712.[2] OPENAI, ACHIAM J, ADLER S, 等. GPT-4 Technical Report[EB/OL]//arXiv.org. (2023-03-15)[2024-03-11]. https://arxiv.org/abs/2303.08774v6.[3] GOERTZEL B, WANG P. Advances in Artificial General Intelligence: Concepts, Architectures and Algorithms : Proceedings of the AGI Workshop 2006[M]. IOS Press, 2007.[4] WANG P, GOERTZEL B. Introduction: Aspects of Artificial General Intelligence[C]//Proceedings of the 2007 conference on Advances in Artificial General Intelligence: Concepts, Architectures and Algorithms: Proceedings of the AGI Workshop 2006. NLD: IOS Press, 2007: 1-16[2023-08-13].[5] WANG P, GOERTZEL B. Theoretical Foundations of Artificial General Intelligence: 卷 4[M/OL]. Paris: Atlantis Press, 2012[2023-08-10]. https://www.atlantis-press.com/doi/10.2991/978-94-91216-62-6. DOI:10.2991/978-94-91216-62-6.[6] ARCAS B A y. Artificial General Intelligence Is Already Here[J/OL]. 2023[2024-01-19]. https://www.noemamag.com/artificial-general-intelligence-is-already-here.[7] LECUN Y. A path towards autonomous machine intelligence Version 0.9.2, 2022-06-27[J]. Open Review, 2022, 62.[8] MA Y, ZHANG C, ZHU S C. Brain in a Vat: On Missing Pieces Towards Artificial General Intelligence in Large Language Models[M/OL]. arXiv, 2023[2024-03-11]. http://arxiv.org/abs/2307.03762. DOI:10.48550/arXiv.2307.03762.[9] XI Z, CHEN W, GUO X, 等. The Rise and Potential of Large Language Model Based Agents: A Survey[M/OL]. arXiv, 2023[2024-03-11]. http://arxiv.org/abs/2309.07864. DOI:10.48550/arXiv.2309.07864.[10] 王培. 深度剖析:ChatGPT 及其继任者会成为通用人工智能吗?| AI那厮[EB/OL]//微信公众平台. (2023-03-15)[2024-03-11]. http://mp.weixin.qq.com/s?__biz=Mzg2MTUyODU2NA==&mid=2247581475&idx=1&sn=0c8226f4ac48fbaf215cf17d4e95205a&chksm=ce1637b8f961beae295bdee882dde89c88e09b510cab92e37b20b6ee361139f203e72e8ac963#rd.[11] 王培. 智能论纲要[M]. 1 版. Shanghai: 上海科技教育出版社有限公司, 2022.[12] 李德毅. 论智能的困扰和释放[J]. 智能系统学报, 2024, 19(1): 249-257.[13] WANG P. On Defining Artificial Intelligence[J/OL]. Journal of Artificial General Intelligence, 2019, 10(2): 1-37. DOI:10.2478/jagi-2019-0002.[14] HAMMER P, LOFTHOUSE T, WANG P. The OpenNARS Implementation of the Non-Axiomatic Reasoning System[C/OL]//STEUNEBRINK B, WANG P, GOERTZEL B. Artificial General Intelligence. Cham: Springer International Publishing, 2016: 160-170. DOI:10.1007/978-3-319-41649-6_16.[15] WANG P. Non-axiomatic reasoning system: Exploring the essence of intelligence[D/OL]. Indiana University, 1995[2024-02-26]. https://www.proquest.com/docview/304212565/abstract/9762967BE501441DPQ/1.[16] LEGG S, HUTTER M. A Collection of Definitions of Intelligence[C]//Proceedings of the 2007 conference on Advances in Artificial General Intelligence: Concepts, Architectures and Algorithms: Proceedings of the AGI Workshop 2006. NLD: IOS Press, 2007: 17-24[2023-08-13].[17] MORRIS M R, SOHL-DICKSTEIN J, FIEDEL N, 等. Levels of AGI: Operationalizing Progress on the Path to AGI[M/OL]. arXiv, 2023[2023-11-21]. http://arxiv.org/abs/2311.02462. DOI:10.48550/arXiv.2311.02462.[18] 徐博文. 智能是什么?[EB/OL]//微信公众平台. (2023-10-27)[2024-03-11]. http://mp.weixin.qq.com/s?__biz=MzIzMjQyNzQ5MA==&mid=2247675232&idx=1&sn=14a78b15ef1862480360d0e0f320513a&chksm=e89977eddfeefefb1c508b354ccff8bb3da52d35aaba19c63d13a6349dee2a445eae473991f8#rd.[19] TURING A M. Computing Machinery and Intelligence[J/OL]. Mind, 1950, LIX(236): 433-460. DOI:10.1093/mind/LIX.236.433.[20] PENG Y, HAN J, ZHANG Z, 等. The Tong Test: Evaluating Artificial General Intelligence Through Dynamic Embodied Physical and Social Interactions[J/OL]. Engineering, 2023[2023-08-13]. https://www.sciencedirect.com/science/article/pii/S209580992300293X. DOI:10.1016/j.eng.2023.07.006.[21] WANG P. The Evaluation of AGI Systems[C/OL]//3d Conference on Artificial General Intelligence (AGI-2010). Atlantis Press, 2010: 154-159[2024-03-14]. https://www.atlantis-press.com/proceedings/agi10/1931. DOI:10.2991/agi.2010.33.[22] XU B, REN Q. Artificial Open World for Evaluating AGI: A Conceptual Design[C/OL]//GOERTZEL B, IKLÉ M, POTAPOV A, 等. Artificial General Intelligence. Cham: Springer International Publishing, 2023: 452-463. DOI:10.1007/978-3-031-19907-3_43.[23] 吴思. 追问专访·吴思:打开人工智能的“智慧之门”[EB/OL]//微信公众平台. (2023-10-23)[2024-03-18]. http://mp.weixin.qq.com/s?__biz=MzI3MjQ4MDMyOQ==&mid=2247505732&idx=1&sn=52a1e723227ec8351f9b48371d1ca96e&chksm=eb337662dc44ff745e81a1e517c72741fb6918420fe15f305cc9d5cad41530e134dc5d06a640#rd.[24] 黄铁军. 黄铁军:沉迷于寻求通用智能理论,将是阻碍 AI 发展的最大障碍 | Yann LeCun 自传《科学之路》序[EB/OL]//微信公众平台. (2021-08-30)[2024-03-12]. http://mp.weixin.qq.com/s?__biz=MzU5ODg0MTAwMw==&mid=2247503191&idx=1&sn=d9644d7d6cfe4e1709636e184ac226f0&chksm=febc8e93c9cb078597e5213e90707dd6b2bdb54d7718091c98542c5b5dd49abc2e8b85652724#rd.[25] 施芳. “一定要做出些原创性成果”(讲述·弘扬科学家精神)[EB/OL]. (2024-01-31)[2024-03-12]. http://paper.people.com.cn/rmrb/html/2024-01/31/nw.D110000renmrb_20240131_1-06.htm.[26] 朱松纯. 浅谈人工智能:现状、任务、构架与统一 | 正本清源[EB/OL]//微信公众平台. (2017-11-02)[2024-03-12]. http://mp.weixin.qq.com/s?__biz=MzI3MTM5ODA0Nw==&mid=2247484058&idx=1&sn=0dfe92a0991294afba2514b137217a66&chksm=eac3276addb4ae7c6acbc6f9275bf8ad5dcefafab631b41905d9f78c01ae46ddde8b2d9e7b31#rd.[27] WANG P. Experience-grounded semantics: a theory for intelligent systems[J/OL]. Cognitive Systems Research, 2005, 6(4): 282-302. DOI:10.1016/j.cogsys.2004.08.003.
(

