

计算机视觉中的一项挑战性任务是寻找技术来提高用于处理移动空中平台所获图像的机器学习(ML)模型的目标检测和分类能力。目标的检测和分类通常是通过应用有监督的ML技术完成的,这需要标记的训练数据集。为这些训练数据集收集图像是昂贵而低效的。由于一般不可能从所有可能的仰角、太阳角、距离等方面收集图像,这就导致了具有最小图像多样性的小型训练数据集。为了提高在这些数据集上训练的监督性ML模型的准确性,可以采用各种数据增强技术来增加其规模和多样性。传统的数据增强技术,如图像的旋转和变暗,在修改后的数据集中没有提供新的实例或多样性。生成对抗网络(GAN)是一种ML数据增强技术,它可以从数据集中学习样本的分布,并产生合成的复制,被称为 "深度伪造"。这项研究探讨了GAN增强的无人驾驶飞行器(UAV)训练集是否能提高在所述数据上训练的检测模型的可推广性。为了回答这个问题,我们用描述农村环境的航空图像训练集来训练"你只看一次"(YOLOv4-Tiny)目标检测模型。使用各种GAN架构重新创建帧中的突出目标,并将其放回原始帧中,然后将增强的帧附加到原始训练集上。对航空图像训练集的GAN增强导致YOLOv4-微小目标检测模型的平均平均精度(mAP)平均增加6.75%,最佳情况下增加15.76%。同样,在交叉联合(IoU)率方面,平均增加了4.13%,最佳情况下增加了9.60%。最后,产生了100.00%的真阳性(TP)、4.70%的假阳性(FP)和零的假阴性(FN)检测率,为支持目标检测模型训练集的GAN增强提供了进一步证据。



引言
对从移动平台上获得的数据进行图像和视频分类技术的调查,目前是计算机视觉领域中一个越来越受关注的领域。由空中飞行器收集的图像对于收集信息和获得对环境的洞察力非常重要,否则在地面上的评估是无法实现的。对于训练目标检测模型来说,用于创建这些模型的训练集的一个重要特征是这些训练集必须在其图像中包含广泛的细节多样性。过去的数据增强技术,例如旋转、添加噪音和翻转图像,被用来增加训练集的多样性,但由于它们无法向数据集添加任何新的图像,所以是弱的方法。研究新的图像增强和分类方法,其中包括机器学习(ML)技术,有助于提高用于航空图像分类的模型的性能。
1.1 背景与问题陈述
1.1.1 背景
最近,使用ML算法对图像进行分类或预测的情况越来越多。虽然ML已经被使用了几十年,但在图像上,我们看到合理的进展是在过去的20年里。随着信息收集和存储的技术进步及其可及性的扩大,可用于分析的数据量正以指数级的速度增长。计算机的随机存取存储器(RAM)和硬件存储的增加迎合了拥有巨大的数据集来训练、测试和验证ML模型以实现较低的偏差和变异的需要。技术上的其他进步来自于计算机图形处理单元(GPU)的改进,它允许以更快的速度处理大量的数据,这是实时图像处理的两个重要能力[2]。
人工神经网络(ANNs)是ML的一个子集,其灵感来自于大脑中神经元的生物结构,旨在解决复杂的分类和回归问题[3]。深度学习是ANNs的一个子集,它创建了多个相互连接的层,以努力提供更多的计算优势[3]。卷积神经网络(CNN)是ANN的一个子集,它允许自动提取特征并进行统一分类。一般来说,CNN和ANN需要有代表性的数据,以满足操作上的需要,因此,由于现实世界中的变化,它们往往需要大量的数据。虽然在过去的十年中收集了大量的数据,但微不足道和不平衡的训练数据集的问题仍然阻碍着ML模型的训练,导致糟糕的、有偏见的分类和分析。相对较小的数据集导致了ML模型训练中的过拟合或欠拟合。过度拟合的模型在训练数据上显示出良好的性能,但在模型训练完成后,却无法推广到相关的真实世界数据。通过提供更大、更多样化的训练数据集,以及降低模型的复杂性和引入正则化,可以避免模型过拟合[4]。
过度拟合的模型不能学习训练集的特征和模式,并对类似的真实世界数据做出不准确的预测。增加模型的复杂性可以减少欠拟合的影响。另一个克服模型欠拟合的方法是减少施加在模型上的约束数量[4]。有很多原因可以说明为什么大型、多样的图像集对训练模型以检测视频帧中捕获的目标很有用。当视频取自移动平台,如无人机或汽车时,存在Bang等人[5]所描述的进一步问题。首先,一天中拍摄图像的时间以及天气状况都会影响亮度和阴影。其次,移动平台收集的图像有时会模糊和失真,这是因为所使用的相机类型以及它如何被移动平台的推进系统投射的物理振动所影响。移动平台的高度、太阳角度、观察角度、云层和距离,以及目标的颜色/形状等,都会进一步导致相机采集的样本出现扭曲的影响。研究人员忽视这些参数的倾向性会导致模型在面对不同的操作数据时容易崩溃。这些因素使得我们有必要收集大量包含各种特征、图像不规则性和扭曲的视频帧,以复制在真实世界的图像收集中发现的那些特征,从而训练一个强大的目标检测和分类模型。
为了增加图像的多样性,希望提高在数据上训练的分类模型的结果准确性,可以使用数据增强技术来扭曲由无人驾驶飞行器(UAV)收集的图像。目前的一些数据增强技术包括翻转、旋转或扭曲图像的颜色。虽然这些增强技术可以在数据集中引入更多的多样性,但它们无法为模型的训练提供全新的框架实例。
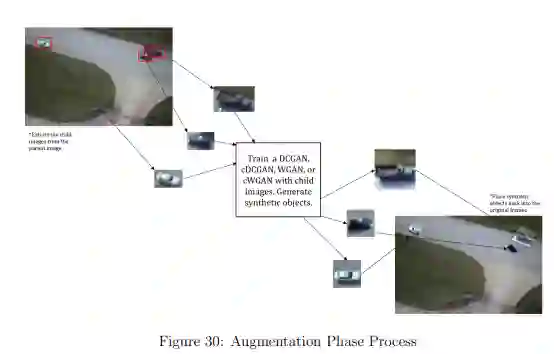
生成性对抗网络(GAN)是一种ML技术,它从数据集的概率分布和特征中学习,以生成数据集的新的合成实例,称为 "深度假象"。GAN的实现是一种更强大的数据增强技术,因为它为训练集增加了新的、从未见过的实例,这些实例仍然是可信的,并能代表原生群体。为ML模型提供这种新的训练实例,可以使模型在实际操作环境中用于检测时更加强大。
1.1.2 问题说明
图像采集面临的一个普遍问题是没有收集足够大和多样化的训练和测试数据集来产生高效的ML模型。这些微不足道的训练集所显示的多样性的缺乏,使模型在用于实时检测时表现很差。找到增加这些数据集的方法,无论是通过额外的数据收集还是其他方法,对于创建一个强大的、可归纳的模型都很重要。
计算机视觉中的第二个问题是传统的数据增强技术所产生的图像多样性增加不足。通过旋转、翻转或调暗每一个收集到的视频帧来增强数据集,不能为训练集增加任何额外的实例,这与上面提到的第一个问题相矛盾。需要找到一种新的数据增强技术,在不需要收集更多数据的情况下提供新的实例,这对于快速训练检测模型以便在快速变化的操作环境中部署非常重要。
1.2 研究问题
本研究试图回答以下问题:
1.由移动平台获取的包含GAN生成的合成图像的增强图像训练数据集是否会提高卷积神经网络(CNN)目标检测模型的分类精度和可推广性?
2.由移动平台获取的包含GAN生成的合成图像的增强图像训练数据集是否会提高CNN目标检测模型的定位和通用性?
3.从未增强的数据集和增强的数据集中可以得出什么推论,显示它们的相似性和不相似性?
提供支持第一和第二个问题的证据可以改变数据科学家进行数据收集的方式,并将他们的努力转向使用GAN的增强技术来创建用于ML研究的数据集。该模型不仅要能够对目标进行分类,而且要训练一个强大的目标检测模型,使其能够在图像中找到感兴趣的目标,并具有较高的交叉联合(IoU)值,这就验证了该模型能够找到移动的目标,这些目标在捕获的帧中的位置各不相同。一个模型的泛化是指该模型对网络从未见过的输入进行准确预测和分类的能力[6]。增强的数据集必须在质量和数量上与原始数据集相似,以证明模型泛化能力增强的断言。
对最后一个问题的回答提供了理由,即来自GAN的增强对象在性质上是否与原始样本相似,并且是对现实世界环境中发现的东西的合理复制。同类目标之间的高相似率可能会使GAN增强变得脆弱,需要进一步研究以用于实际应用。
1.3 研究的局限性
本研究的最大限制之一是能否获得适当的硬件和软件来实现不同的ML算法。虽然ML模型可以在中央处理器(CPU)上执行,但本论文中的模型在单个CPU上运行需要几天,甚至几周的时间。在运行深度学习模型时,GPU的效率要高得多,尤其是那些为图像探索设计的模型。在整个研究过程中,GPU的使用非常有限,这给CNN和GAN模型的复杂性增加了限制,也增加了每个模型完成训练迭代的时间。模型不可能同时运行,大大增加了本论文的完成时间。
另一个限制是本研究过程中可用的内存和硬盘内存的数量。内存不足进一步导致了模型复杂性的下降,以及模型在研究的训练和测试过程中某一时刻可以利用的数据量的下降。这两个模型组成部分的减少会导致次优模型。在这项研究中,我们采取了一些措施来减轻这些影响,包括选择参数较少但性能与较复杂的模型相同的高水平的模型。此外,在训练和测试过程中,将数据集划分为多个批次,有助于缓解RAM和硬盘内存问题。
1.4 论文组织
本章讨论了本论文将集中研究的ML的一般领域,以及概述了ML研究中出现的好处和限制。第2章提供了一个文献回顾,研究了CNNs和GANs的理论。此外,它还提供了使用CNNs、GANs和从无人机收集的图像帧进行的相关研究。第3章详细介绍了数据集增强前后的CNN检测模型的训练过程。第4章提供了用于增强训练集的合成目标的细节。第5章介绍了在原始和增强的训练集上训练的最佳模型的评估结果。第6章概述了在原始测试集训练结束后进行的三个不同实验的方法。第7章回顾了这三个不同实验的结果。最后,第8章讨论了从结果中得出的结论,以及对使用生成性对抗网络(GANs)对移动平台获取的图像进行数据增强领域的未来研究建议。





