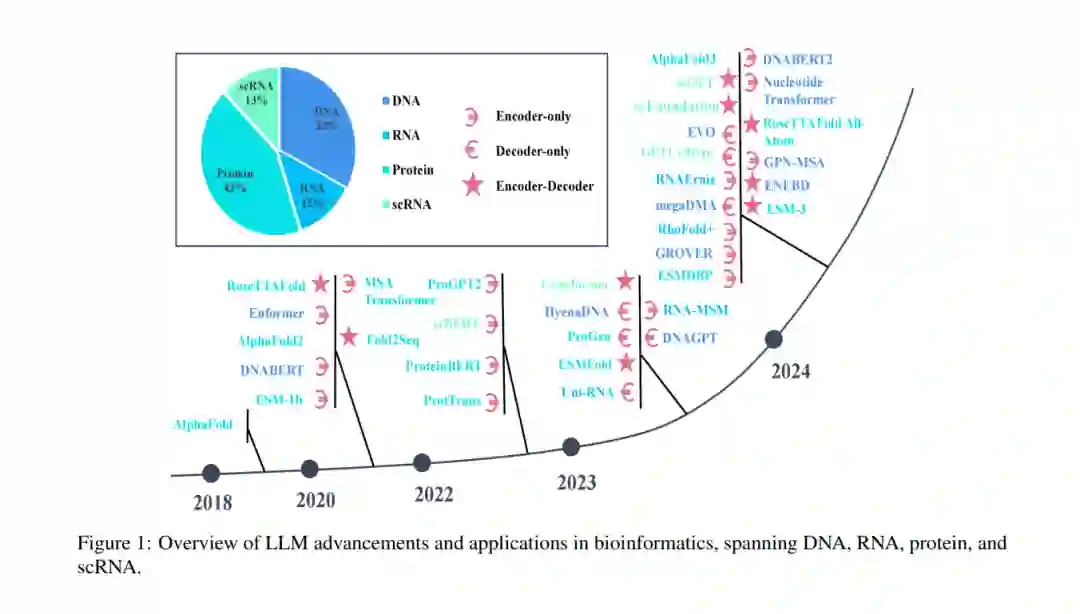
![]() 大型语言模型(LLMs)正在彻底改变生物信息学领域,为 DNA、RNA、蛋白质和单细胞数据的高级分析提供了强大支持。本综述系统回顾了最新进展,重点关注基因组序列建模、RNA 结构预测、蛋白质功能推断和单细胞转录组学。同时,我们还讨论了数据稀缺性、计算复杂性和跨组学整合等关键挑战,并探索了未来方向,如多模态学习、混合人工智能模型和临床应用。通过提供全面的视角,本文强调了大型语言模型在推动生物信息学和精准医学创新方面的变革潜力。1 引言生物信息学是一个跨学科领域,结合了生物学、计算机科学和信息技术,用于分析和解释复杂的生物数据(Abdi 等,2024)。近年来,大型语言模型(LLMs)在自然语言处理(NLP)领域取得了显著进展,其应用涵盖了广泛的任务(Min 等,2023;Raiaan 等,2024)。然而,生物数据的性质及相关任务与文本数据存在显著差异,带来了独特的挑战。如何准确且精确地处理生物医学数据,以有效构建适合 LLMs 的特征和嵌入,是一个持续存在的挑战,需要创新的解决方案。在生物学领域,任务具有高度的多样性和特异性。这些任务包括 DNA 序列的功能预测与生成、RNA 结构与功能的预测、蛋白质结构的预测与设计,以及单细胞数据的分析(涵盖降维、聚类、细胞注释和发育轨迹分析等)。研究人员对利用 LLMs 推动生物信息学和计算生物学的发展越来越感兴趣,并取得了显著成果。如图 1 所示,生物信息学中大型模型的开发、训练和应用正在快速增长。尽管如此,针对这些多样化任务的不同方法尚未得到系统总结和分析,这为全面回顾和综合提供了机会。本综述的组织结构:本文回顾了 LLMs 在生物信息学中的最新进展。我们首先介绍基本概念(§2),涵盖关键架构及其与生物数据的相关性。接下来,表 1 展示了生物信息学中具有代表性的 LLMs。随后,我们探讨了 LLMs 在 DNA 与基因组学(§3)、RNA(§4)、蛋白质(§5)和单细胞分析(§6)中的创新应用。最后,我们讨论了关键挑战(§7.1)并提出了未来方向(§7.2),强调多模态学习、混合人工智能模型和临床应用。总结部分,我们分析了本综述的局限性,指出了需要进一步探索的领域,以全面把握 LLMs 在生物信息学中的发展动态。
大型语言模型(LLMs)正在彻底改变生物信息学领域,为 DNA、RNA、蛋白质和单细胞数据的高级分析提供了强大支持。本综述系统回顾了最新进展,重点关注基因组序列建模、RNA 结构预测、蛋白质功能推断和单细胞转录组学。同时,我们还讨论了数据稀缺性、计算复杂性和跨组学整合等关键挑战,并探索了未来方向,如多模态学习、混合人工智能模型和临床应用。通过提供全面的视角,本文强调了大型语言模型在推动生物信息学和精准医学创新方面的变革潜力。1 引言生物信息学是一个跨学科领域,结合了生物学、计算机科学和信息技术,用于分析和解释复杂的生物数据(Abdi 等,2024)。近年来,大型语言模型(LLMs)在自然语言处理(NLP)领域取得了显著进展,其应用涵盖了广泛的任务(Min 等,2023;Raiaan 等,2024)。然而,生物数据的性质及相关任务与文本数据存在显著差异,带来了独特的挑战。如何准确且精确地处理生物医学数据,以有效构建适合 LLMs 的特征和嵌入,是一个持续存在的挑战,需要创新的解决方案。在生物学领域,任务具有高度的多样性和特异性。这些任务包括 DNA 序列的功能预测与生成、RNA 结构与功能的预测、蛋白质结构的预测与设计,以及单细胞数据的分析(涵盖降维、聚类、细胞注释和发育轨迹分析等)。研究人员对利用 LLMs 推动生物信息学和计算生物学的发展越来越感兴趣,并取得了显著成果。如图 1 所示,生物信息学中大型模型的开发、训练和应用正在快速增长。尽管如此,针对这些多样化任务的不同方法尚未得到系统总结和分析,这为全面回顾和综合提供了机会。本综述的组织结构:本文回顾了 LLMs 在生物信息学中的最新进展。我们首先介绍基本概念(§2),涵盖关键架构及其与生物数据的相关性。接下来,表 1 展示了生物信息学中具有代表性的 LLMs。随后,我们探讨了 LLMs 在 DNA 与基因组学(§3)、RNA(§4)、蛋白质(§5)和单细胞分析(§6)中的创新应用。最后,我们讨论了关键挑战(§7.1)并提出了未来方向(§7.2),强调多模态学习、混合人工智能模型和临床应用。总结部分,我们分析了本综述的局限性,指出了需要进一步探索的领域,以全面把握 LLMs 在生物信息学中的发展动态。
![]()