本文介绍了我们在具身人工智能(Embodied AI)智能体方面的研究,这些智能体以视觉、虚拟或物理形式体现,从而能够更自然地与用户及其环境交互。这类智能体包括虚拟化身、可穿戴设备以及机器人,旨在具备感知、学习与行动的能力,使其在学习与交互方式上更接近人类,相比于非具身智能体更具自然性与适应性。 我们提出,世界模型(World Models)的构建是具身智能体实现推理与规划的核心,能够帮助智能体理解并预测其环境、把握用户意图与社会语境,从而提升其自主完成复杂任务的能力。世界建模涵盖了多模态感知的整合、基于推理的规划与控制、以及记忆机制,共同构建对物理世界的全面理解。除物理世界外,我们还提出应学习用户的心理世界模型(Mental World Model),以实现更优的人机协作。 虚拟具身智能体正在变革治疗与娱乐等领域,通过提供具情感理解能力的交互体验。可穿戴智能体(如集成于 AI 眼镜中)有望实现实时辅助与个性化体验,而机器人智能体则可应对劳动力短缺,在非结构化环境中执行任务。本文不仅探讨了具身智能体面临的技术挑战及我们的解决策略,还强调了在这些智能体逐步融入日常生活过程中对伦理问题的重视,尤其是关于隐私保护与拟人化的议题。 未来的研究方向包括:具身智能体的学习能力、多智能体协作与人机互动的提升、社会智能的增强,以及在设计过程中确保伦理实践。通过应对上述挑战,具身智能体有望革新人机交互方式,使其更直观、更能响应人类需求。本文综述了我们在具身智能体研究方面的现状与未来方向,旨在推动其潜力的全面释放,为人类生活带来深远影响。


1 引言
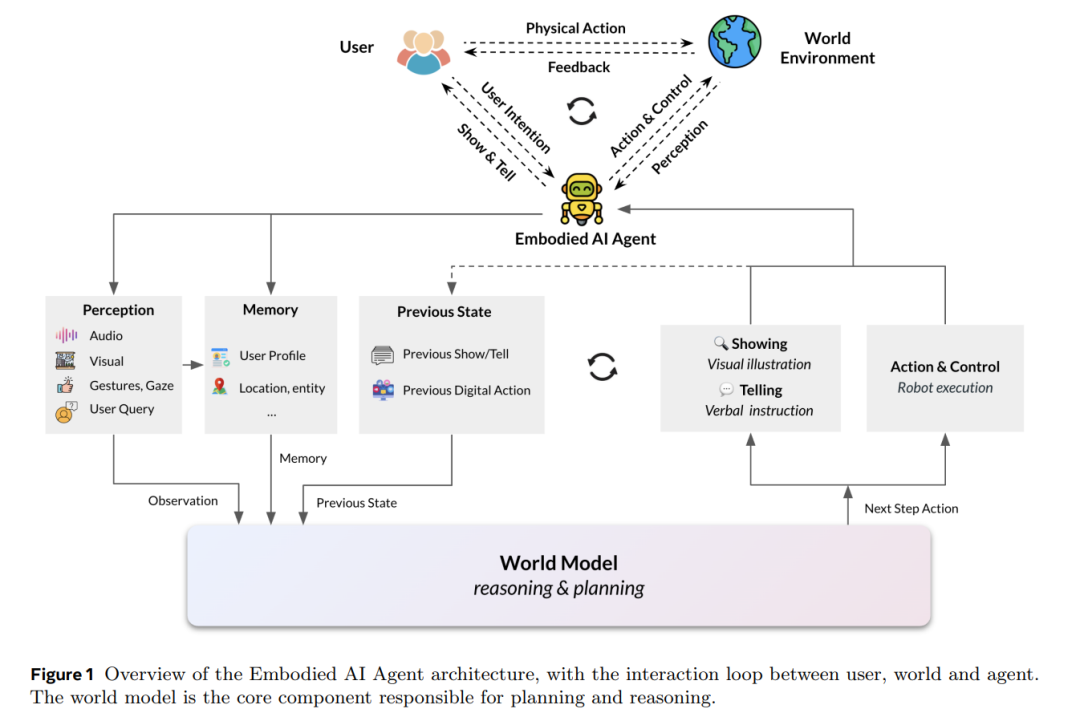
具身人工智能(Embodied AI)智能体是一类具备视觉、虚拟或物理形式的人工智能系统,使其能够与用户及其物理或数字环境进行学习与交互。这些具身 AI 系统必须具备在环境中进行有意义感知与行动的能力,因此也就要求它们对所处物理世界有深入理解。相比之下,仅存在于网络中的无形智能体并不具备具身性,而那些依靠遥控或预编程指令运行的机器人或无人机,也缺乏真正智能体所需的自主性与适应性。 可穿戴设备的独特之处在于:它们集成了能够感知物理世界并执行动作的 AI 系统,这种“感知—行动”的协同机制使得从用户视角出发,可穿戴智能体也具备具身性,模糊了人机边界。正如哲学家梅洛-庞蒂(Maurice Merleau-Ponty, 1945)所言:“我不是在我的身体里,我就是我的身体”,这强调了身体并非仅是思想的容器,而是存在本身不可分割的一部分。这一观点与具身智能体的理念密切相关,即智能体的身体与其环境共同构成其认知过程的重要组成。基于此,我们提出一个具身智能体框架,核心在于世界建模(World Modeling),使智能体能够以更复杂、更类人的方式推理与交互。 具身性在当前 AI 与机器人研究中主要有两个作用:(1)物理交互:使 AI 系统能够通过直接动作(如机器人智能体)或感知环境(如可穿戴智能体)与物理世界互动;(2)增强人机交互:研究表明,具身智能体能够提升用户的信任感(Winata et al., 2017; Fung et al., 2018; Shridhar et al., 2024)。此外,具身智能体还有一个日益受到关注的潜力方向:(3)类人的学习与发展方式——通过模拟人类的丰富感官体验,从而实现更直觉、类人的学习过程(Dupoux, 2018; Radosavovic et al., 2023)。 构建一个能自主学习、能够与人类和现实世界互动,并在个人与职业生活中提供帮助的 AI 系统,始终是人工智能发展的目标。从最初基于规则的聊天机器人,到 AI 客服,再到虚拟助手,每一代 AI 助手都具备更强的能力。线上 AI 智能体的出现是这一演化的最新阶段。与此同时,AI 的具身化也展现出多样形态,从具身对话代理(Cassell, 2001),到可穿戴设备(Alsuradi et al., 2024)、机器人(Mon-Williams et al., 2025),再到类人机器人(Cao, 2024)。每种具身形式面向不同的任务与应用场景,具备各自独特的能力需求,同时也共享一些核心能力。 不同于以往的 AI 助手,现代 AI 智能体更具自主性,能自主规划多步骤任务,决定所需的外部资源,并判断需协作的其他智能体,能够根据用户显式的请求或上下文隐含的信息理解用户需求。具身智能体还需为用户执行或协助用户执行实际动作,这对其推理与规划能力提出了更高要求。这种“感知世界并据此规划行动”的能力,正是世界建模的核心(LeCun, 2022)。 此外,智能体应能够与用户进行对话,以便在需求不明确或情境发生变化时澄清意图或确认信息。未来,智能体还需能与多个用户及其他智能体进行协作交互。这要求人机互动具备表达性、社会敏感性与情境适应性——换言之,智能体需要理解用户的“心理世界模型(mental world model)”。为支撑物理与心理世界的建模、推理与规划,具身智能体还需具备短期与长期记忆能力。 AI 助手演化为 AI 智能体,很大程度上得益于大语言模型(LLM)与视觉语言模型(VLM)的进展。开发者通过对 LLM 和 VLM 进行提示调控(prompting),构建了具身化的虚拟智能体,如虚拟化身(Cherakara et al., 2023)、智能眼镜、虚拟现实设备(Pan et al., 2024)以及机器人平台(Brohan et al., 2023;Tong et al., 2024)。这些 LLM 不仅在自然语言理解与生成方面表现优异,经过 RLHF 微调后,还具备了更强的指令遵循能力,甚至展现出零样本完成多任务的能力,无需专门为某一任务设计训练。伴随全球数百万用户的广泛使用,从最初的新奇感迅速转向对“能够辅助完成任何任务”的现实期待。 智能眼镜(如 Meta Glasses)使用户可以通过设备摄像头获取视觉输入、通过麦克风提供语音输入,并接入 AI 智能体(如 Meta Multimodal AI),尽管目前尚未能充分获取环境中的听觉线索。LLMs 与 VLMs 被用于实现感知、推理与规划功能,推动了情境感知 AI(Contextual AI)的发展(Erdogan et al., 2025)。VLMs 可通过指令调优实现逐步规划(Kim et al., 2024),而机器人也可在 LLM 提示下执行任务(Ahn et al., 2022)。 然而,生成式模型也存在一个核心缺陷,即其模型规模效率低下。它们擅长生成下一个 token 或像素,适用于创意任务,但往往包含大量冗余细节而缺失对推理与规划而言至关重要的信息。而推理与规划能力正是 AI 智能体的根本。因此,为提高具身 AI 的准确性与效率,我们提出采用一种基于多模态感知进行推理与行动预测的世界建模方法。 本文首先综述不同类型智能体及其应用场景,接着介绍我们为具身智能体提出的世界建模框架,其中包括感知机制、物理与心理世界建模、记忆系统、以及行动与控制策略。我们讨论了基于生成式模型的世界建模方法,同时也探讨了更高效且更可信的预测式世界模型(predictive world models)替代方案。接下来,我们将分别介绍三类具身智能体:(1)虚拟具身智能体;(2)可穿戴智能体;(3)机器人智能体,并在每一部分中列举现有评测基准与未来研究方向。最后,我们描绘了具身学习的未来愿景,以及由多个智能体协同合作的“智能体家族(Family of Agents)”。文章最后还探讨了两个关键伦理问题:隐私与安全,以及拟人化(Anthropomorphism)。