摘要——埃德加·爱伦·坡曾言:“真理常潜藏于错误的阴影之中。”这句话揭示了真与假之间在认知与信息不对称条件下复杂而微妙的相互作用。这一动态在大语言模型(LLMs)中尤为显著。尽管LLM在语言生成方面表现出色,但它们有时会生成看似真实却实则虚构的信息,这一问题通常被称为“幻觉”(hallucinations)。幻觉的普遍存在可能误导用户,影响其判断与决策。在金融、法律和医疗等关键领域,这类错误信息可能引发重大经济损失、法律纠纷甚至健康风险,带来广泛影响。在本研究中,我们系统地对LLM幻觉问题进行了分类、成因分析、检测方法与应对策略的综述,重点探讨了幻觉的根源以及当前策略在揭示其内在逻辑方面的有效性,从而为开发新颖且更强大的解决方案奠定基础。通过剖析某些方法在缓解幻觉方面奏效的原因,本研究旨在推动一种更全面的应对思路,以有效应对LLM中的幻觉问题。 关键词——LLM幻觉综述
一、引言
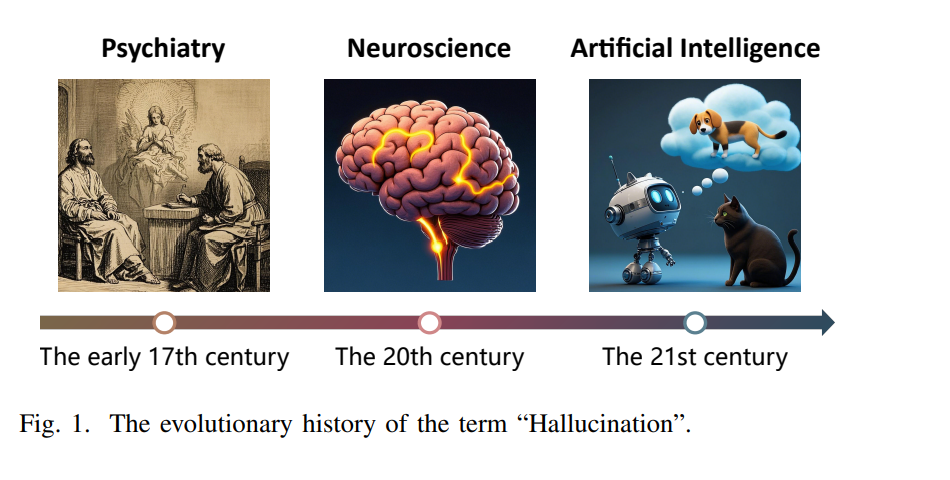
大语言模型(LLMs)的出现极大地推动了自然语言处理(NLP)领域的发展,使得语言技术的应用范围远远超出了传统的文本理解与生成任务【1】。LLM以其超大规模的参数和基于海量语料的预训练为特征,展现出了卓越的能力,能够捕捉复杂的语言模式、上下文依赖关系,甚至具备一定的推理能力【2】【3】。LLM前所未有的规模与适应性预示着人工智能研究范式的变革,引发了关于其知识泛化能力、涌现式推理特性,以及从狭窄的任务智能迈向更通用、类人认知能力等问题的深刻讨论【4】。 尽管LLM取得了显著成功,但它们仍然面临一个关键挑战——幻觉问题,这如同达摩克利斯之剑般悬挂在其可靠性之上。如图1所示,“hallucination”(幻觉)一词源自拉丁文 hallucinari,意为“在意识中游荡”【5】。18至19世纪,精神病学家让-埃蒂安·多米尼克·埃斯基罗尔(Jean-Étienne Dominique Esquirol)将其医学定义精炼为“在无外部刺激下产生的虚假感知”【6】。到了20世纪,神经科学的发展将幻觉与精神疾病(如精神分裂症和帕金森病)联系起来【7】。 近年来,“幻觉”一词在人工智能研究中日益受到关注【8】【9】。然而,在LLM语境下准确界定幻觉仍具挑战性,因为其表现形式多样,且依赖于人的主观解读。以往研究通常先对幻觉进行子类型划分,然后在较窄的概念框架中提出定义。Ji 等人【10】将幻觉分为两类:内在幻觉(Intrinsic Hallucinations),即输出内容与源内容矛盾;外在幻觉(Extrinsic Hallucinations),即输出内容无法从源信息中验证。Banerjee 等人【11】进一步细化为三类:输入冲突型幻觉(Input-conflicting)(偏离用户输入)、上下文冲突型幻觉(Context-conflicting)(与模型先前输出矛盾)、事实冲突型幻觉(Fact-conflicting)(与常识或事实知识冲突)。本综述综合了上述代表性文献的核心观点【10】【11】,并借鉴医学现象学传统【6】,提出对LLM幻觉的工作定义: 幻觉是指LLM生成表面上看似合理、但在事实或上下文上不准确或不连贯的内容。
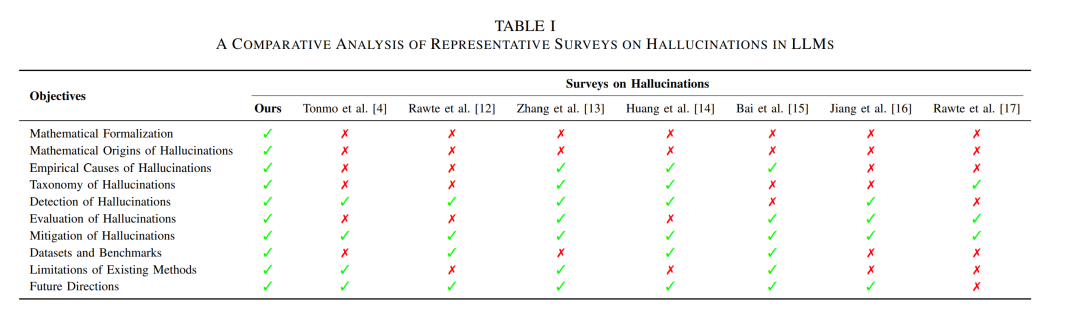
该定义强调了三个关键维度:(1)表面合理性;(2)事实或逻辑上的不一致;(3)上下文一致性的缺失。这为系统分析幻觉模式奠定了理论基础。 随着LLM日益嵌入社会基础设施,其幻觉问题在各类应用中愈加突出,成为亟需解决的重要研究挑战,尤其是在高风险场景中表现尤为严重【18】。例如,在法律领域,LLM输出可能包含重大的事实性错误,或对法条和判例的误导性解释【19】;在医疗系统中,模型幻觉生成的诊断建议可能背离循证指南,从而危及患者安全【20】;在金融领域,LLM可能生成不合规的投资策略,或错误解释监管政策【21】;在教育场景中,幻觉可能扭曲知识结构,破坏学术严谨性【22】。因此,幻觉的普遍性及其严重后果呼唤一项系统性的综述,以全面梳理现有研究进展与应对策略。 目前已有多个综述系统汇总了LLM幻觉的研究成果(见表1),但仍存在三大关键局限: 1. 缺乏理论视角。现有综述多采用经验性分析方法,聚焦于现象学定义和成因的描述性总结。然而,近年来一种新兴的研究范式正逐步兴起——通过学习理论方法【23–25】对幻觉的机制展开严谨的数学建模。这一分析转向有助于揭示幻觉生成的底层原理,但在现有综述中仍被严重忽视。 1. 分类体系过于泛化,缺乏领域特异性。大多数综述使用通用分类法将幻觉进行统一处理,默认其在各领域中具有一致性【26】。但实际上,幻觉的表现往往具有显著的领域特征【27】:在医疗中,幻觉常表现为错误的临床参考或误诊断【28】;而在教育领域,幻觉则可能表现为对知识层级结构的扭曲或教学逻辑的混乱【29】。这种对不同应用场景缺乏细致区分的分类方式,会导致对幻觉的系统性误判,并限制精细化机制理解的建立。 1. 对幻觉缓解方法的局限性探讨不足。现有综述虽然总结了大量缓解技术,但普遍忽视了这些方法所面临的结构性瓶颈。例如:未触及缓解框架中的深层结构缺陷【30】、对任务先验的高度依赖【26】、以及对动态或不可预测数据环境的适应能力不足【4】。这种基础性分析的缺失,导致研究者在开发下一代缓解机制时缺乏理论指导。
本综述针对上述缺口做出三方面的核心贡献: 1. 提出首个LLM幻觉统一理论框架,系统整合分散的研究成果,从理论上弥合当前研究碎片化的问题。 1. 揭示当前缓解方法的根本局限性,通过分析幻觉的不可避免性,指出当前缓解策略难以从根本上彻底解决该问题。 1. 构建新型任务感知评估分类体系,将语义偏差度量与模型结构属性系统性关联,实现在不同NLP任务中的精细诊断。
综上所述,本综述旨在深入分析LLM幻觉的形成机制,系统梳理其检测、评估与缓解策略的最新进展,进而构建一套完整的研究框架,推动该领域的理论发展与工程应用。全文结构如下:第一部分探讨幻觉的数学起源,阐明其理论基础;第二部分分析幻觉的经验成因;第三部分评估现有方法的优劣;第四部分综述检测技术;第五部分总结缓解策略。 本文在LLM幻觉研究中的主要贡献包括: 1. 幻觉类型的机制解析:深入剖析事实错误、语义不忠、逻辑不一致等不同类型幻觉的生成机制,通过对模型内部结构与生成过程的研究,揭示幻觉的根本诱因,为理解该问题提供理论依据。 1. 评估、检测与缓解方法的系统综述:系统回顾了当前主流的评估与检测方法,包括自动评价指标、人工评估机制及专用检测框架,并总结了诸如检索增强生成(RAG)、知识图谱辅助、提示工程等缓解策略,提出切实可行的解决思路以提升LLM的可靠性与实用性。 1. 未来研究方向探讨:通过对幻觉成因与当前技术瓶颈的分析,识别现有研究的空白点,并提出后续研究路径,如探索幻觉与“真实信息子空间”的关系、研究置信度校准对幻觉发生的影响等,激发该领域的持续探索。