
题目: Towards Reinforcement Learning of Human Readable Policies
摘要:
强化学习(RL)已经证明了它通过利用非线性函数逼近器来解决高维任务的能力。然而,这种成功主要局限于模拟领域在将RL部署到现实世界时,可能会引起对使用“黑盒”策略的几个关注。为了使RL更易于解释,我们在本文中提出了一种策略迭代方案,该方案保留了一个复杂的函数逼近器来进行内部值预测,但限制了策略具有简单的、人类可读的结构。我们证明了我们提出的算法可以解决连续动作的深度RL基准和返回策略,这些都可以被一个非专业人员完全可视化和解释。
邀请嘉宾:
Riad Akrour是智能自主系统组的研究科学家,致力于分层强化和反向强化学习。Riad Akrour于2015年4月加入智能自主系统组实验室,2014年10月在巴黎第11大学(法国奥赛)获得计算机科学博士学位。在获得博士学位之前,他获得了阿尔及利亚阿尔及尔高等信息学院(Ecole Nationale Superieure d'Informatique)的计算机工程学位,以及法国巴黎居里大学(Universite Pierre et Marie Curie)的人工智能与决策硕士学位。研究兴趣是强化学习和逆强化学习,持续优化,基于偏好的强化学习,机器人。
Davide Tateo是研究机器人和强化学习的智能自主系统小组的博士后研究员。Davide在2019年2月从米兰理工大学获得信息技术博士学位后,于2019年4月加入实验室。他目前正在SKILLS4ROBOTS项目中工作,该项目的目标是开发能够获得和提高一系列丰富的运动技能的类人机器人。
成为VIP会员查看完整内容
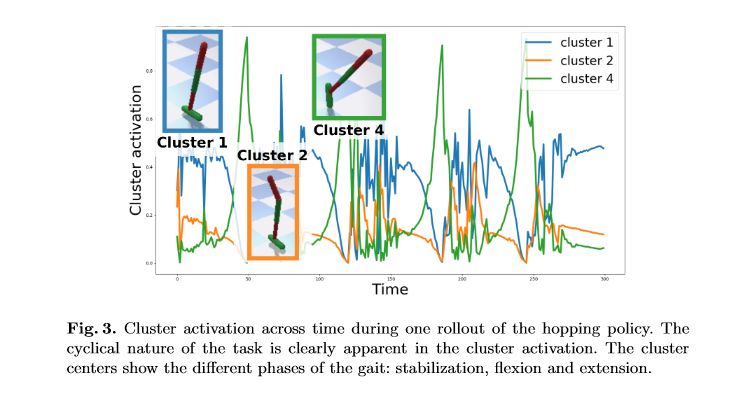



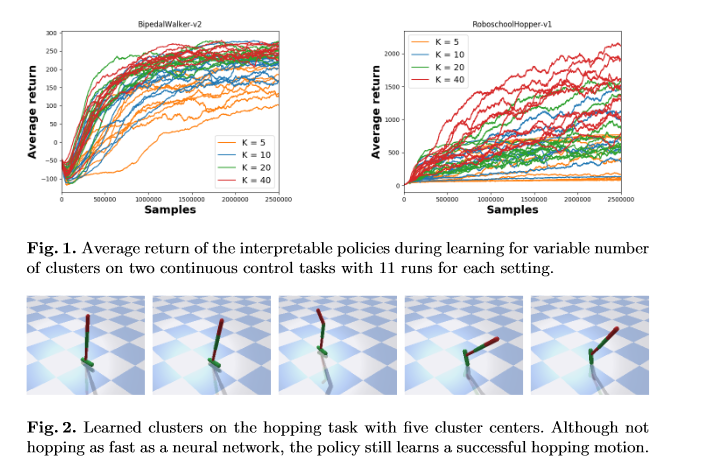
相关内容

达姆施塔特工业大学(德语:Technische Universität Darmstadt),是德国历史悠久的理工科技大学,位于黑森州达姆施塔特,以工程学,自然科学及建筑学等而闻名。是各邦联州自德意志联邦共和国诞生以来,第一个自主办学的公立大学。自己实行财政预算和不动产管理,并独立自由的聘请教授。德国九所卓越理工大学联盟TU9成员之一,两次入选德国大学卓越计划(Exzellenzinitiative)。世界第一个电子工程系于1882年在达姆施塔特工业大学成立。
计算机科学,电气工程,人工智能,机电一体化,商业信息学以及更多课程被德国达姆施塔特工业大学的德国科学学科引入。[5][6][7] 在密码学,IT安全和软件工程领域,达姆施塔特大学是欧洲领先的大学。 [8] 在人工智能,机器人技术,机器学习,计算机视觉和自然语言处理领域,它在欧洲大学中排名第二,在德国排名第一。[8]
达姆施塔特工业大学拥有德国技术大学中最多的高管。
专知会员服务
13+阅读 · 2019年11月17日
专知会员服务
34+阅读 · 2019年3月21日
Arxiv
5+阅读 · 2018年2月16日
相关主题



相关VIP内容
专知会员服务
13+阅读 · 2019年11月17日
专知会员服务
34+阅读 · 2019年3月21日
相关资讯
相关论文
Arxiv
5+阅读 · 2018年2月16日