
今天给大家介绍一篇来自兰州大学胡斌教授课题组发表在2021年IEEE BIBM会议上的Construction of Depression Knowledge Graph Based on Biomedical Literature,本文的主要工作是从生物医学文献中抽取抑郁症有关的实体、关系和属性,与结构化数据中提取的实体、关系和属性进行融合,最终构建抑郁症相关的知识图谱。

摘要抑郁症是一种常见的情绪障碍,具有高患病率、高复发率、高致残率和高死亡率的特点。有关抑郁症的医学文献数量众多,但杂乱无章,这无疑会增加生物医学研究人员和医务工作者获取知识的负担,不利于抑郁症发病机制与治疗的研究。因此,我们构建了基于生物医学文献的抑郁症知识图谱,以辅助抑郁症的研究。我们以医学摘要为主要数据源,利用生物医学信息抽取系统SemRep进行知识抽取。其次,使用另一种信息提取工具OpenIE对SemRep提取的数据进行校正。然后,通过将提取的知识与SemMedDB中提取的结构化数据进行融合,最终得到8840个三元组,其中包括3055个实体和30种关系。我们将它们存储到图形库Neo4j中,以可视化知识图谱。 1**.****介绍**抑郁症是一种常见的精神疾病,因其高患病率、高致残性、高死亡率和高复发率而在全球范围内构成严重的健康问题。截至2019年2月,中国抑郁症患者多达9500万。抑郁症已成为生命科学研究的热点,迫切需要利用开放领域的医学知识来促进抑郁症的研究。目前,生物医学信息的主要来源是生物医学数据库,这些数据库大多存在以下问题:首先,大多数生物医学数据库是由人类专家从医学文献中手动提取的,这是一个耗时、费力且效率低下的过程。其次,随着生物医学文献量的快速增长,生物医学数据库中的信息无法及时更新。此外,生物医学数据库中的生物医学知识系统太大,对医生和研究人员来说不直观。与生物医学数据库相比,知识图谱中的知识更新更快,并可以以自动化的方式进行。构建生物医学领域的知识图谱对于生命科学研究至关重要,越来越多的研究者已经将目光投向了这一领域。本文专注于使用生物医学论文来构建抑郁症的知识图谱。首先,很难从如此多不同的数据源中获取数据。其次,生物医学论文包含了大量没有充分利用的知识。PubMed中有很多关于抑郁症的文章,因此,许多文章使得医学研究人员和医疗人员难以充分利用现有的知识,这对抑郁症的研究不利。因此,有必要整合抑郁症的知识,使用知识图谱将是一个不错的选择。在本文中,通过自下而上的方法构建了抑郁症的知识图谱。本文工作的主要贡献可以总结如下: (1)通过SemRep从不同的数据源中提取结构化和非结构化数据,这是一个生物医学信息提取系统。然后,作者将提取的数据存储为事实三元组,以构建知识图谱。 (2)SemRep直接提取的数据存在缺陷。为了进一步提高数据质量,在数据细化过程中引入OpenIE对SemRep提取的数据进行校正,数据合格率达到72.8%。 (3) 然后把这些数据融合起来,存储到图形数据库Neo4j中,本文的知识图谱中有8840个三元组,可以作为抑郁症的辅助治疗工具和研究工具。 **2.**构建方法
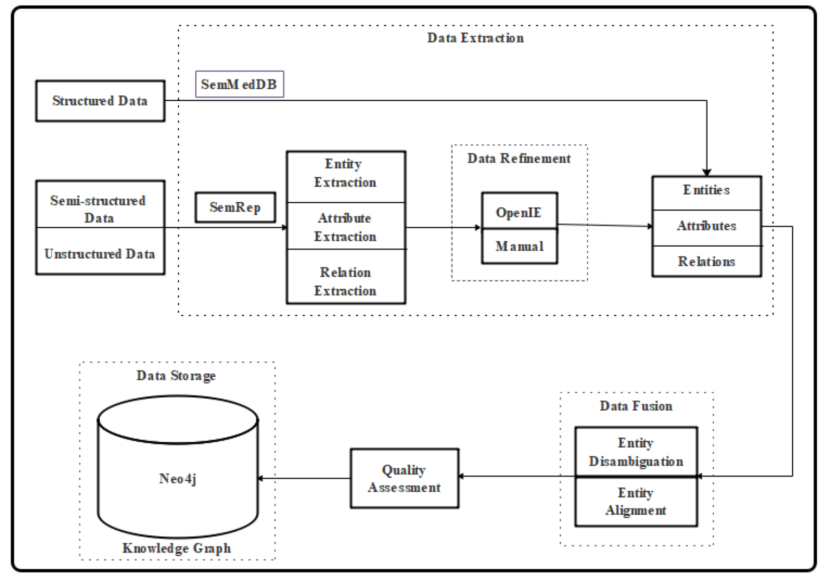
图1. 知识图谱的构建处理流程****首先,作者们通过UMLS获取知识图谱的模式和关系。其次,使用SemRep从结构化和非结构化数据中提取关于抑郁症的实体、关系和属性。第三,使用OpenIE对SemRep提取的数据进行校正。第四,这一步的主要任务是实体对齐和实体消歧,并过滤掉有噪声的数据。完成这些步骤后,将得到大量组成知识图谱的事实三元组。这些三元组的质量决定了知识图谱的质量,因此还需要评估这些三元组的质量。最后,将这些高质量的事实三元组存储在Neo4j图数据库中,以可视化知识图谱。
**A.获取模式和关系
由于本文使用自下而上的方法来构建知识图谱,作者需要确定这个知识图谱中的具体概念和内容(称为模式)。这些模式来自统一医学语言系统(UMLS)。作者只选择了UMLS中与抑郁症相关的部分。最后,总结了UMLS的10个模式,包括病因、检查、疾病、DNA、药物、基因、组、蛋白质、症状、治疗。根据这些已确认的医学模式,从UMLS语义网络中筛选出30个关系。 B.数据抽取首先,使用SemRep从非结构化文本数据中提取实体、属性和关系来获得原始三元组。然后,通过基于规则的方法过滤提取的数据,以确保知识图谱的质量。对于结构化数据,使用基于规则的方法从SemMedDB中提取事实三元组。(1)从非结构化数据中提取数据:为了使知识图谱保持最新,作者决定使用生物医学文献和医学指南作为非结构化数据的来源。首先,从PubMed 下载与抑郁症相关的医学文献摘要。以“抑郁症”为主要关键词,辅以“症状”“脱氧核糖核酸”“治疗”“原因”“基因”“检查”等词搜索PubMed,最终从PubMed下载了94735篇相关摘要。获得这些非结构化数据后,接下来的工作是从这些文本中提取事实三元组。作者使用的提取工具是SemRep,一个从非结构化数据中提取三元组的信息提取系统。SemRep是一个基于UMLS的程序。 表1**.KG中的实体属性**
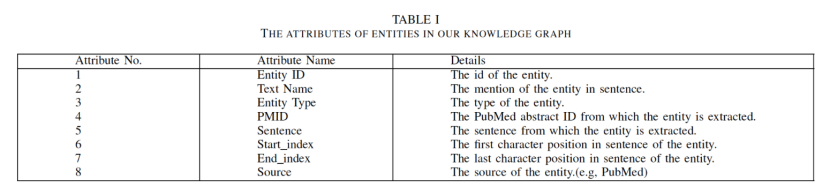

图2.SemRep的输入

图3.SemRep的输出本文使用SemRep从文本中提取实体、关系和属性,包括实体ID、文本名称、实体类型、PMID、开始索引、结束索引、句子和源。表1显示了实体的属性。图2和图3显示了SemRep的示例,图2显示了SemRep的输入,图3显示了SemRep的输出。(2)从结构化数据中提取数据:从SemMedDB数据库中获得了大量与抑郁症相关的结构化数据。然后根据之前设置的模式从结构化数据中过滤所需要的三元组。在数据提取过程中,作者发现从SemMedDB中提取的一些信息出现在非结论句(例如疑问句)中。如果从疑问句中提取三元组可能不准确。因此,使用基于规则的方法来消除疑问句中的三元组。 C.数据细化在使用SemRep提取三元组的过程中有几个挑战,这使得到的三元组的质量不高。第一个挑战是SemRep提取的三元组中有一些可能是不完整的。第二个挑战是SemRep会提取一个句子中所有可能的三元组,其中一些与本文研究的主题无关。第三个挑战是SemRep提取的三元组可能不准确,因为有些句子包含不确定的单词,例如:可能,也许,大概,似乎等。第四个挑战是有些句子不是结论性的,如果从一个疑问句中提取一些三元组,那么三元组很可能不是事实三元组,上述挑战会影响知识图谱的质量,作者提出以下方法来面对这些挑战。作者发现第一个挑战的主要原因是SemRep在提取实体时会丢失一些重要的信息,文章引入了Stanford OpenIE来解决这个问题。具体来说,定义以下规则:对于SemRep提取的实体,如果该实体只包含一个单词,将使用OpenIE从原始句子中重新提取该实体。为了验证规则的有效性,作者手动注释修改后的数据并计算校正率。最后,计算了81.4%的正确率。为了解决第二个挑战,只需要把与主题相关的内容拿出来。对于第三个挑战和最后一个挑战,将删除这些有问题的句子以及从这些句子中提取的三元组。 D.数据融合由于数据源不同,提取的数据两部分之间可能存在冗余,甚至在某些值上发生冲突,因此三元组的两部分不能直接进行融合。为了保证知识图谱的质量,分两步对这些数据进行融合:实体消歧和实体对齐。对于实体消歧,作者发现同一个实体有不同的实体名称,或者同一个实体名称代表不同的实体,比如抑郁症和抑郁障碍都表示精神疾病抑郁障碍,这会对数据融合造成巨大障碍。SemRep从文本中提取实体的标准名称和文本名称(文本名称是句子中实体的名称,实体的标准名称是实体的首选名称),使用实体的文本名称作为实体的属性,使用实体的标准名称作为实体名称。对于相同的实体名称,在SemRep和SemMedDB中可能代表不同的实体。本文提出了一种基于规则的实体对齐方法。对于SemRep和SemMedDB中名称相同的实体,将按顺序比较它们的属性,如果对应的属性值一致,则认为它们代表相同的实体。如果它们的属性值不一致,则将单独保存,手动检查它们。 表2**.识图谱不同实体类别的分布情况**
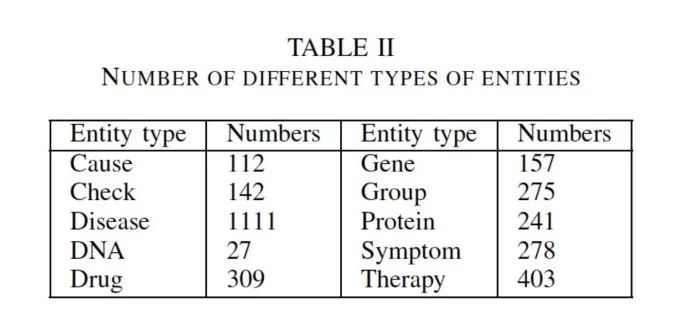
表3.知识图谱不同关系的分布情况
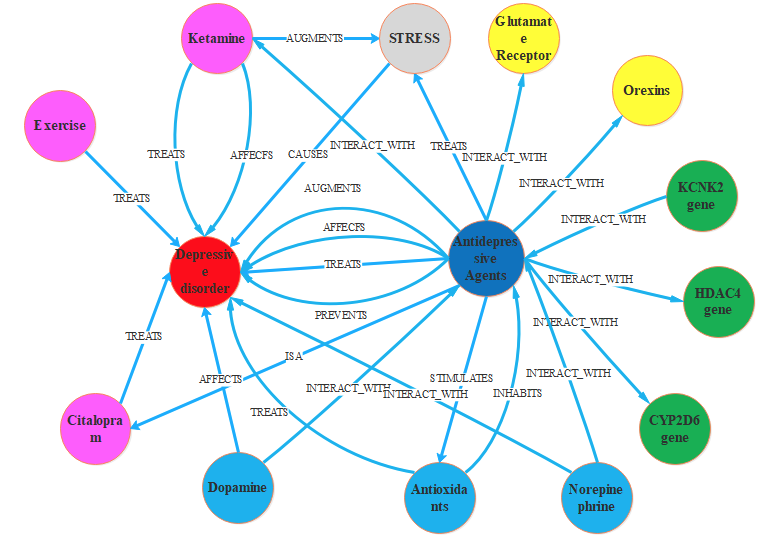
图4.知识图谱的部分显示如图4所示,neo4j将知识图谱表示为一个巨大的网络,其中节点表示实体,边表示实体之间的关系,生物医学研究人员可以使用neo4j提供的cypher语句来搜索实体和关系。例如,抑郁症与抗抑郁药有关系,从与抗抑郁药相关的结构数据和非结构化数据中提取数据,发现CYP2D6基因与抗抑郁药有关系,因此CYP2D6基因可能与抑郁症有关,这一结果可能有助于生物医学研究人员发现与抑郁症有关的物质。 3**.****结果**本文构建了一个包含大量抑郁症知识的知识图谱,一开始从结构化和非结构化数据中得到12276个事实三元组,但这些数据的合格率较差,然后通过使用OpenIE对数据进行修正,删除冗余数据,过滤有问题的数据,将数据的合格率提高到72.8%,最终的知识图谱包含3055个实体,30个关系,8840个三元组。此外,本文提出的知识图谱还包含大量属性。当生物医学研究人员提出研究假设时,他以通过相应三元组提供的PMID获得相关研究文章。作者认为知识图谱可以支持抑郁症网络的分析,并可能有助于发现抑郁症的潜在机制。 4.****结论在本文中,作者展示了构建关于抑郁症的知识图谱的整个过程。由于SemRep提取的实体和关系不够准确,整体的数据质量仍然不高,需要进一步提高。所以下一步的工作将主要集中在数据提取和数据融合上。此外,可以将基于本文的知识图谱开发一些应用程序,如问答系统、推荐系统等。 参考资料
Li Z, Zhang Y, Huang R, et al. Construction of Depression Knowledge Graph Based on Biomedical Literature[C].2021 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). IEEE, 2021: 1849-1855. https://doi.org/10.1109/BIBM52615.2021.9669447


