

用于生成式人工智能的大型语言模型(LLMs)取得了显著进展,逐步演化为复杂且多功能的工具,广泛应用于各类领域与场景。然而,由于其庞大的参数规模带来的高内存开销,以及注意力机制所需的高计算资源,使得在实现低延迟与高吞吐量的LLM推理服务过程中面临诸多挑战。得益于一系列突破性研究的推动,近年来该领域取得了飞跃性进展。本文对相关方法进行了全面综述,涵盖了基础的实例级优化方法、深入的集群级策略、新兴的场景导向方案,以及其他一些虽较边缘但同样重要的方面。
在实例级方面,我们回顾了模型部署、请求调度、解码长度预测、存储管理,以及计算资源解耦(Disaggregation)等技术。在集群级方面,我们探讨了GPU集群部署、多实例负载均衡和云服务解决方案。针对新兴应用场景,我们围绕具体任务、模块及辅助方法进行组织与讨论。为确保综述的全面性,我们还特别指出了若干细分但关键的研究方向。最后,本文提出了若干可能的未来研究路径,以进一步推动LLM推理服务的发展。
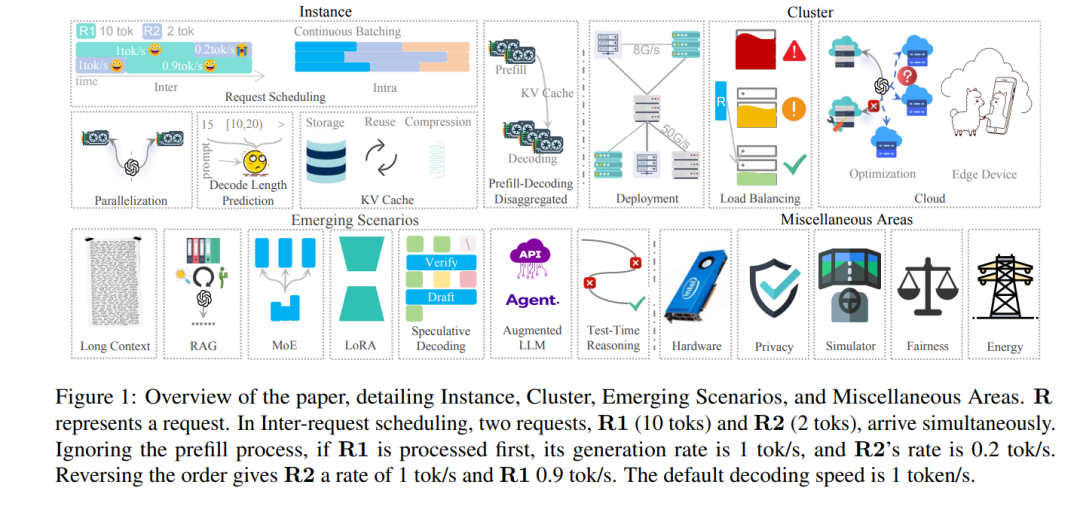
1 引言
随着开源大型语言模型(LLMs)的快速发展,近年来模型架构与功能的每周更新已成为常态。从 Huggingface 的下载数据中可明显看出这些模型的旺盛需求——诸如 Mistral-Small-24B-Instruct-2501(Mistral, 2025)、phi-4(Abdin 等, 2024)、Llama 3.3-70B-Instruct(Grattafiori 等, 2024)等模型的下载量达到数十万次,而 DeepSeek-V3(DeepSeek-AI 等, 2024)和 DeepSeek-R1(DeepSeek-AI 等, 2025)等模型的下载量在近几个月已达到数百万次。 然而,在部署这些模型时,其大规模参数和注意力机制对内存和计算资源提出了极高要求,这对实现低延迟和高吞吐量的请求处理带来了重大挑战。为了满足服务级别目标(SLOs),这些挑战推动了推理服务优化领域在多个方向上的深入研究。
本文系统性地综述了LLM推理服务的方法,并依照层次结构进行组织,涵盖了从实例级优化、集群级策略,到新兴场景与其他重要方向的研究,如图1所示。 实例级优化(§3) 从模型部署(§3.1)开始,主要解决单个GPU内存不足时的跨设备参数分布问题。随后是请求调度(§3.2),通过解码长度预测(§3.3)优先处理较短请求,以降低整体延迟。动态批次管理机制用于在迭代推理过程中进行请求插入与剔除。键值缓存(KV Cache)(§3.4)可减少重复计算,但在存储效率、复用策略与压缩技术方面仍面临挑战。鉴于预填阶段与解码阶段的特性差异,近年来提出了解耦式架构(§3.5),以优化这两个阶段的处理效率。 集群级优化 主要聚焦于部署策略(§4),包括异构硬件下的成本效益型GPU集群配置,以及面向服务的集群调度方案(§4.1)。可扩展性带来了负载均衡(§4.2)方面的挑战,旨在避免分布式实例间的资源浪费或过载问题。当本地硬件资源无法满足部署需求时,基于云的解决方案(§4.3)则成为满足动态LLM服务需求的关键手段。 新兴场景(§5) 涉及诸多先进任务与方法,包括长上下文处理(§5.1)、检索增强生成(RAG, §5.2)、专家混合机制(MoE, §5.3)、低秩适配(LoRA, §5.4)、预测解码(§5.5)、增强型LLM(§5.6),以及测试时推理(Test-Time Reasoning, §5.7),这些技术都需要模型具备高度的适应性以满足不断变化的需求。 最后,本文还详细探讨了其他重要方向(§6),涵盖硬件(§6.1)、隐私(§6.2)、模拟器(§6.3)、公平性(§6.4)和能效(§6.5)等较为边缘但关键的领域,旨在推动LLM推理服务的全面发展。 尽管已有多项综述工作(Miao 等, 2023;Yuan 等, 2024;Zhou 等, 2024;Li 等, 2024a)为该领域打下了基础,但在深度、广度或时效性方面仍存在不足,难以覆盖快速演进的研究动态。为此,本文构建了一个系统化、细粒度的前沿方法分类体系,并提出若干具有前瞻性的研究方向,力图弥补现有文献的空白。


