

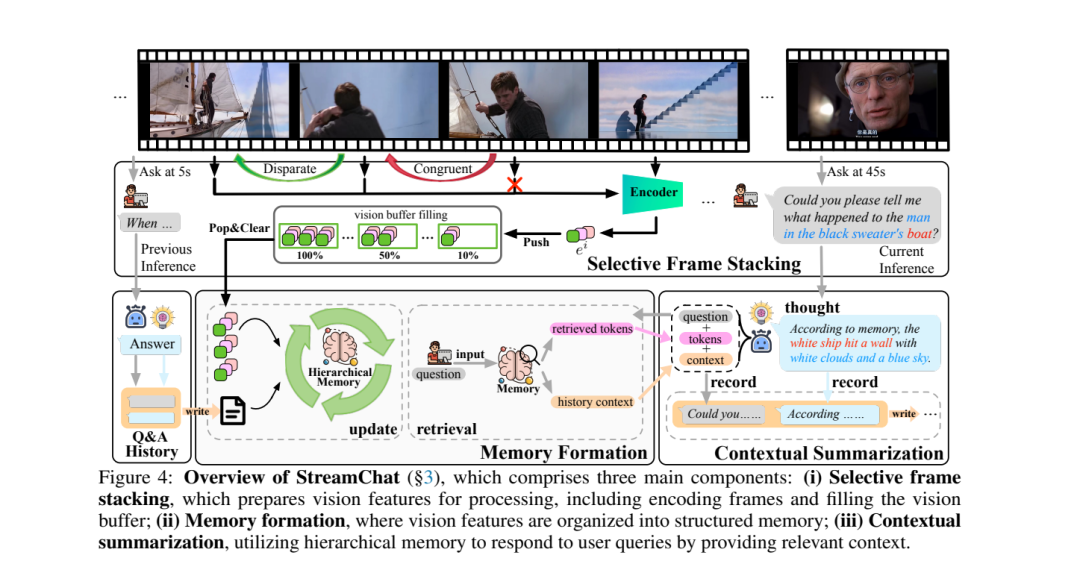
最近在大型语言模型(LLMs)方面的进展使得视频语言模型(Video-LLMs)的发展成为可能,通过将视频数据与语言任务结合,推动了多模态学习的进步。然而,当前的视频理解模型在处理长视频序列、支持多轮对话以及适应现实世界的动态场景方面存在困难。为了解决这些问题,我们提出了STREAMCHAT,一个无需训练的框架,用于流媒体视频推理和对话互动。STREAMCHAT利用一种新颖的分层记忆系统,能够高效地处理和压缩长序列中的视频特征,从而实现实时的多轮对话。我们的框架结合了并行系统调度策略,提高了处理速度并降低了延迟,确保在现实应用中的强大性能。此外,我们还推出了STREAMBENCH,一个多功能的基准测试,能够评估流媒体视频理解在多种媒体类型和互动场景下的表现,包括多轮互动和复杂推理任务。在STREAMBENCH和其他公开基准上的广泛评估表明,STREAMCHAT在准确性和响应时间方面显著超越了现有的最先进模型,验证了其在流媒体视频理解中的有效性。代码可在StreamChat获取。
成为VIP会员查看完整内容
相关内容
Arxiv
36+阅读 · 2023年4月19日
Arxiv
190+阅读 · 2023年4月7日
Arxiv
132+阅读 · 2023年3月29日
Arxiv
77+阅读 · 2023年3月21日
相关VIP内容
相关资讯
相关论文
Arxiv
36+阅读 · 2023年4月19日
Arxiv
190+阅读 · 2023年4月7日
Arxiv
132+阅读 · 2023年3月29日
Arxiv
77+阅读 · 2023年3月21日