

近年来,多模态大语言模型(MLLMs)的进展强调了可扩展模型和数据在提升性能方面的重要性,但这通常会带来巨大的计算成本。尽管专家混合模型(MoE)架构已被用于有效扩展大型语言和图文模型,但这些尝试通常涉及的专家数量较少,且模态有限。为了解决这一问题,我们的工作首次尝试开发一个使用MoE架构的统一MLLM,名为Uni-MoE,该模型可以处理多种模态。具体而言,它具有带有连接器的模态特定编码器,以实现统一的多模态表示。我们还在LLM中实现了稀疏的MoE架构,通过模态级数据并行和专家级模型并行来实现高效的训练和推理。为了增强多专家的协作和泛化能力,我们提出了一种渐进的训练策略:1)使用不同的跨模态数据通过各种连接器进行跨模态对齐,2)使用跨模态指令数据训练模态特定的专家,以激活专家的偏好,3)使用低秩适应(LoRA)在混合多模态指令数据上调整Uni-MoE框架。我们在一套全面的多模态数据集上评估了指令微调的Uni-MoE。广泛的实验结果表明,Uni-MoE在处理混合多模态数据集时显著减少了性能偏差,并改进了多专家协作和泛化能力。我们的研究结果突显了MoE框架在推进MLLMs方面的巨大潜力,代码可在https://github.com/HITsz-TMG/UMOE-Scaling-Unified-Multimodal-LLMs上获取。
近期开源多模态大语言模型(MLLMs)的进展,例如InstructBLIP和LLaVA,在图文理解任务上取得了显著成功。此外,越来越多的趋势开始构建能够理解更多模态(如视频、音频和语音)的统一MLLM,超越传统的图文范式。为了赶上像GPT-4V和Gemini这样的高性能闭源MLLM,开源社区的主要努力包括扩大模型规模,例如将视觉基础模型扩展到60亿参数,以及与70B大语言模型(LLMs)的整合,并通过多样化的多模态数据集来增强指令微调。这些发展表明了MLLMs在处理和推理多个模态方面的能力不断增强,显示了模型可扩展性和多模态指令数据扩展的重要性。然而,扩大模型规模通常会在训练和推理阶段带来巨大的计算开销。 为了解决这个问题,出现了将专家混合模型(MoE)架构集成到大模型中的趋势,以提高训练和推理效率。与传统的MLLMs或LLMs不同,后者需要对每个输入处理所有模型参数,导致密集的计算方式,而MoE架构只需要为每个输入激活一部分专家参数,这些参数由专家选择器或路由器决定。因此,MoE方法成为提高大模型效率、减少广泛参数激活需求的有前途策略。例如,Jiang等人引入了一种基于稀疏MoE的语言模型,名为Mixtral-MoE 8x7B,每层由8个专家组成。在数学、代码生成和多语言基准测试中,它优于Llama2-70B,同时需要更少的激活参数。Lin等人开发了一个增强图文MLLM的MoE模型,MoE-LLaVA,该模型激活了大约30亿参数,但在各种图文理解基准测试中达到了与密集7B模型相当的结果。
虽然先前的工作已成功将MoE应用于构建纯文本和图文大型模型,但开发MoE架构以构建强大的统一MLLMs仍然 largely uncharted,例如将MLLMs扩展到包含超过四个专家,并将其应用扩展到除图像和文本之外的模态。在这项工作中,我们率先探索使用MoE架构扩展统一MLLMs,并提出一个高效的MLLM,名为Uni-MoE,该模型可以利用稀疏MoE来熟练管理和解释多种模态。具体来说,如图1所示,我们首先使用模态特定的编码器来获取不同模态的编码,并通过设计的各种连接器将其映射到LLMs的语言表示空间。这些连接器包含一个可训练的Transformer模型及随后的线性投影层,分别对冻结编码器的输出表示进行提炼和投影。然后,我们在密集LLM的内部块中引入稀疏MoE层。因此,每个基于MoE的块具有适用于所有模态的共享自注意力层、基于前馈网络(FFN)的多样化专家和用于分配标记级别专业知识的稀疏路由器。通过这种方式,Uni-MoE可以理解音频、语音、图像、视频和文本等多种模态,并且在推理过程中只需要激活部分参数。
此外,为了增强Uni-MoE的多专家协作和泛化能力,我们开发了一个三阶段渐进训练方法:首先,我们使用广泛的图像/语音/音频到语言对分别训练相应的连接器,实现LLMs语言空间的统一模态表示。其次,我们使用跨模态数据集分别训练模态特定的专家,以精炼每个专家在其各自领域的能力。第三,我们将这些训练好的专家集成到LLM的MoE层中,并使用混合多模态指令数据训练整个Uni-MoE框架。为了进一步减少训练成本,我们采用LoRA技术微调这些预调好的专家和自注意力层。通过上述三阶段训练方法,我们获得了一个高效且稳定的Uni-MoE,能够熟练管理和解释多种模态。
为了验证Uni-MoE的有效性,我们在广泛的基准测试(如图文、视频和音频/语音理解数据集)中与各种密集MLLMs进行了比较。此外,我们还引入了一个新的基准测试,名为英语高中听力测试,以评估模型在复杂长语音理解场景中的表现。实验结果表明,在构建多模态模型时,利用MoE架构不仅在视频和长语音等苛刻的多模态环境中优于传统的密集模型设置,还增强了不同模态间的稳定性和鲁棒性。此外,我们还发现,将更多的模态信息集成到Uni-MoE中可以提高单模态任务的性能。例如,整合更多的图文数据可以改善视频QA任务的输出。我们的贡献如下:
- 框架。我们提出了Uni-MoE(第3.2节和表1),这是第一个基于稀疏MoE的统一MLLM,集成了视频、图像、文本、音频和语音等多种模态。它通过模态特定的编码器、其他模态到语言的连接器以及配备稀疏MoE架构的LLM构建。在训练和推理过程中,我们通过专家级模型并行和模态级数据并行,提高了MoE架构训练的可扩展性,增加了专家数量和多样化的多模态数据。
- 训练策略。我们介绍了一种渐进的训练范式(第3.3节和算法1):一个用于不同模态到语言对齐的阶段,训练模态特定的专家,并在混合多模态数据上使用LoRA进行统一MoE训练。我们详细的实验(表8)表明,在单个模态上预训练专家显著增强了多专家系统的协作和泛化能力,超过了每个专家具有相同初始参数的标准MoE微调结果。
- 实践。Uni-MoE在几乎所有评估基准测试上均优于密集MLLMs,显示了其在处理复杂域外任务中的卓越能力。我们研究了广泛使用的辅助平衡损失在使用混合模态数据训练稀疏MoE基础的MLLM中的作用(表8和9),发现即使没有这种辅助损失,Uni-MoE仍然表现出优越的多专家协作和泛化能力。我们的结果进一步揭示,随着专家数量和路由搜索空间的扩展,辅助损失的好处变得显著。
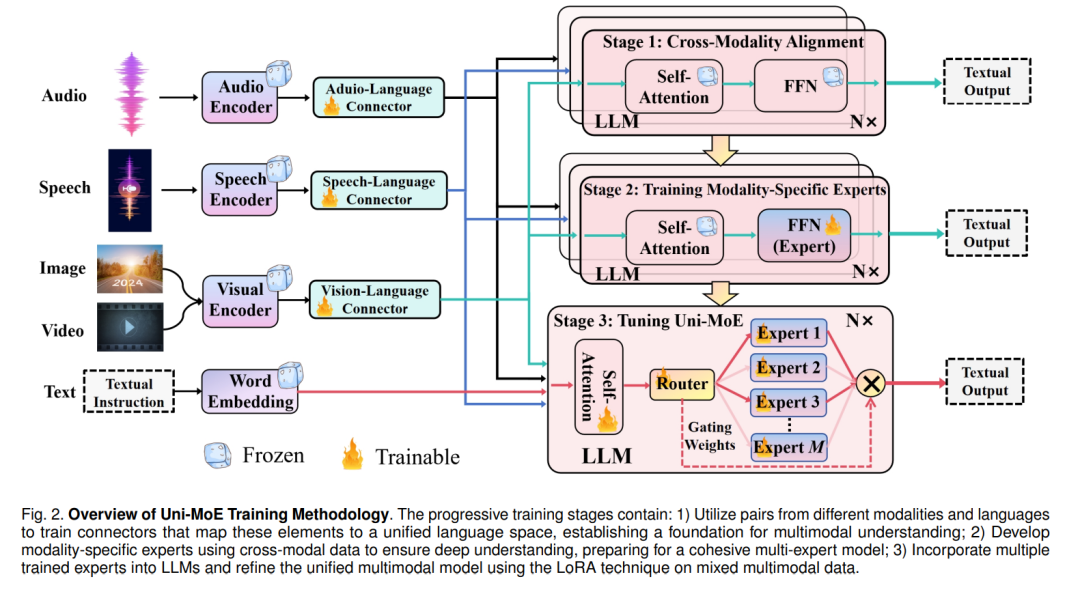
由于在向GPT-4V和Gemini扩展多模态大型模型时带来的高昂训练和推理成本,以及MoE结构的高效性,我们在此探索利用MoE架构实现一个高效且强大的统一MLLM。图2展示了设计的Uni-MoE的示意图,展示了其全面的设计,包括音频、语音和视觉的编码器,以及相应的模态连接器。这些连接器用于将各种模态输入转换为统一的语言空间。然后,我们在核心LLM块中集成了MoE架构,这对于提高训练和推理过程的效率至关重要,因为它只激活部分参数。这是通过实施一个稀疏路由机制来实现的,如图2底部所示。整个Uni-MoE的训练过程分为三个不同的阶段:跨模态对齐、训练模态特定的专家和使用多样化的多模态指令数据集微调Uni-MoE。在接下来的小节中,我们将详细探讨Uni-MoE的复杂架构和渐进的训练方法。
