

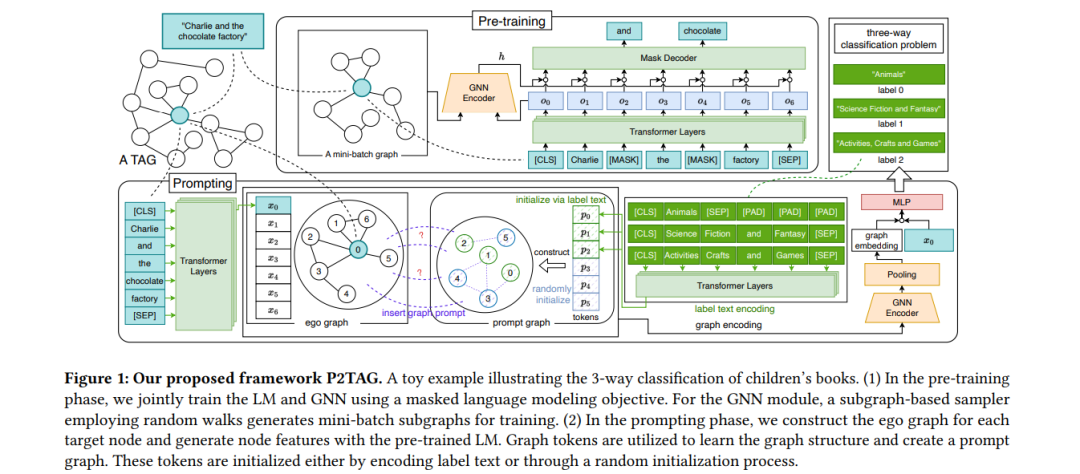
文本属性图(TAG)是一种重要的现实世界图结构数据,每个节点都与原始文本相关联。对于TAG,传统的少样本节点分类方法直接在预处理后的节点特征上进行训练,而不考虑原始文本。其性能高度依赖于特征预处理方法的选择。在本文中,我们提出了P2TAG,一种针对TAG的少样本节点分类框架,通过图预训练和提示进行实现。P2TAG首先在TAG上对语言模型(LM)和图神经网络(GNN)进行自监督损失的预训练。为了充分利用语言模型的能力,我们在框架中适配了掩码语言建模目标。预训练模型随后使用混合提示方法进行少样本节点分类,同时考虑文本和图信息。我们在六个现实世界的TAG上进行了实验,包括论文引用网络和产品共同购买网络。实验结果表明,我们提出的框架在这些数据集上比现有的图少样本学习方法表现更好,改进幅度为+18.98% ∼ +35.98%。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
152+阅读 · 2023年3月29日
Arxiv
20+阅读 · 2023年3月21日

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
152+阅读 · 2023年3月29日
Arxiv
20+阅读 · 2023年3月21日