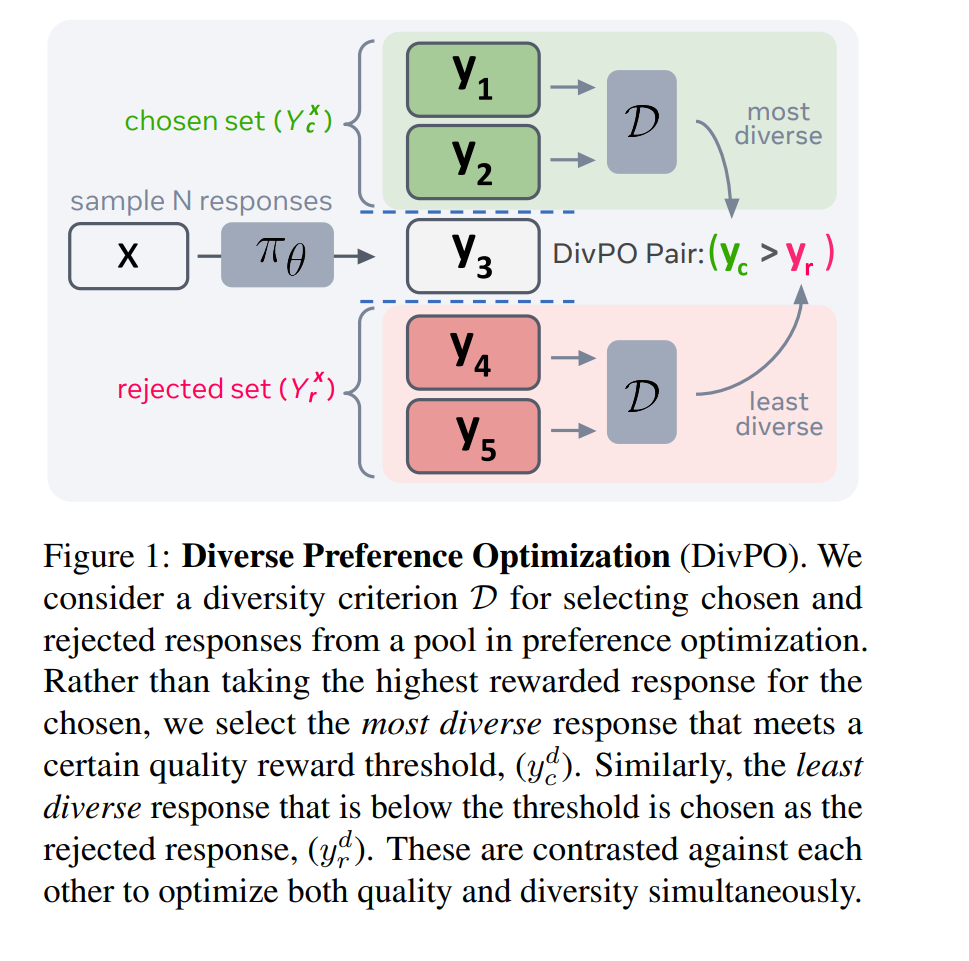
在语言模型的后训练阶段,无论是通过强化学习、偏好优化还是监督微调,都倾向于锐化输出概率分布,并减少生成响应的多样性。这对于创意生成任务尤为成问题,因为此类任务需要多样化的响应。在本研究中,我们提出了多样化偏好优化(DivPO),这是一种在线优化方法,旨在生成比标准流程更具多样性的响应,同时保持生成内容的质量。在DivPO中,通过首先考虑一组响应及其多样性度量,选择偏好对。所选例子通常是较为稀有且高质量的,而被拒绝的例子则是更常见但质量较低的。DivPO能够生成45.6%更具多样性的个性特征,并使故事多样性增加81%,同时保持与标准基线相似的获胜率。1 引言大型语言模型(LLMs)擅长在给定特定提示时生成高质量的“人类对齐”输出。然而,这种对齐不幸地导致了生成多样化输出的困难。例如,反复要求当前最先进的模型编写具有特定标题的故事,最终会生成具有非常相似人物、事件和风格的故事。除了如前所述的用户查询问题外,这还影响了生成高质量合成数据的能力——合成数据已成为通过AI反馈进行模型训练的关键组成部分,其中生成的数据被反馈到训练循环中(Yuan et al., 2024)。响应趋向于一个有限支持分布似乎源于模型对齐阶段,在此阶段,基础语言模型通过微调与人类输出和偏好对齐(Kirk et al., 2024;Bronnec et al., 2024)。模型权重被调优以优化奖励(通常是人类偏好的代理)。这导致模型将高奖励响应的概率设为高,而对其他响应的概率设为低。然而,可能存在其他奖励相同的响应,但由于训练损失,它们被忽视。理想情况下,我们希望奖励相同的响应具有相同的生成概率。此外,当两个响应之间的奖励差距很小时,我们也希望它们的生成概率接近。为了解决这个限制,我们提出了一种新的训练方法,称为多样化偏好优化(DivPO),旨在平衡给定提示的高质量响应分布。其关键直觉是,与偏好优化中通常对比最高和最低奖励的响应不同,我们选择满足奖励(质量)阈值的最具多样性的响应,并将其与低于奖励阈值的最不多样化响应进行对比。我们的方法旨在不仅实现高质量的生成输出,而且提高多样性。