
今天介绍一篇由密歇根州立大学Mengying Sun等人于2022年8月在线发表在KDD上的文章。本文基于搜索的方法提出了一个简单而有效的框架,称为MolSearch,用于多目标生成和优化。作者声称,在适当的设计和足够的领域信息的情况下,基于搜索的方法可以实现与深度学习相当甚至更好的性能,同时具有计算效率。

1 介绍 寻找具有所需特性的新化合物是早期药物发现中的一项常规任务。然而,化学结构的微小变化可能会导致即使是经验丰富的化学家也无法预见的不必要的性质变化。此外,几乎无限的化学空间和需要考虑各种特性在实践中提出了重大的挑战。基于历史生物和药物化学数据的高级机器学习模型可以帮助设计具有多个目标的化合物。
作者团队根据优化模型对相关研究进行了分类。第一类方法基于贝叶斯优化优化分子,通过自动编码器等生成模型学习分子的潜在空间,通过潜在空间的导航来优化属性,这种方法严重依赖潜在空间的质量,给多目标优化带来了挑战;第二类方法不是操纵潜在表示,而是利用强化学习来优化分子特性;第三类方法利用遗传算法来生成所需特性的分子;最后一类使用搜索方法优化分子特性。
作者团队提出了一种基于蒙特卡洛树搜索驱动方法来生成分子。主要贡献如下: * MolSearch是最早在多目标分子生成和优化方面使基于搜索的方法与基于DL的方法相媲美的方法之一。 * MolSearch以一种新颖的方式结合了许多成熟的组件,例如树搜索、设计移动、多目标优化使得生成的分子不仅具有所需的特性,还实现了广泛的多样性。 * MolSearch的计算效率非常高,可以很容易的应用于任何真正药物发现项目,无需超出属性目标的额外知识。 * 除了分子生成,MolSearch更适合hit-to-lead优化,因为它的设计性质使它非常通用和适用。
2 方法
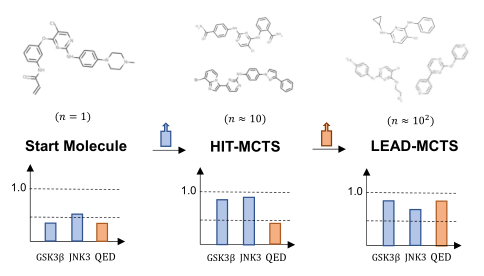
图1: MolSearch的总体框架
如图1所示,整个过程包括两个搜索阶段:HIT-MCTS阶段和LEAD-MCTS阶段。HIT-MCTS旨在修饰分子以获得更好的生物特性,LEAD-MCTS阶段寻找具有更好非生物特性的分子。每个阶段利用多目标蒙特卡罗搜索树来搜索期望的分子。
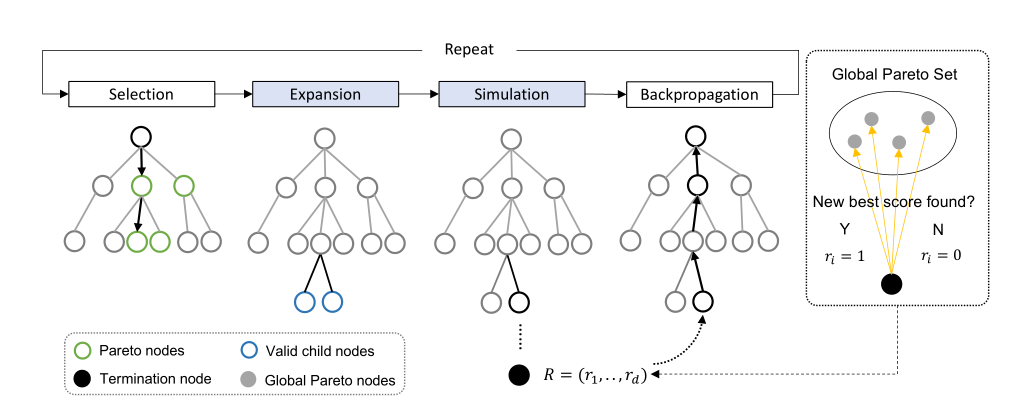
图2:多目标蒙特卡罗树搜索过程
如图2所示,基本的 MCTS 程序每次迭代包括四个步骤: * 选择。从根节点开始,递归地选择一个最佳子节点,直到到达叶节点,即尚未扩展或终止的节点。 * 扩展。选择的叶子节点根据策略展开,直到达到最大子节点数。 * 模拟。从每个子节点递归生成下一个状态直到终止并获得最终奖励。 * 反向传播。奖励沿着访问的节点反向传播,以更新它们的统计信息,直到根节点。
MCTS 最重要的步骤是选择步骤,需要确定一个标准来比较不同的子节点。最常用的标准是置信上限(UCB1),其中选择一个子节点来最大化。对于单目标的MCTS,UCB1 是一个标量,最大化选择具有最大值的节点。对于多目标MCTS,奖励变成了一个向量,比较不再简单,作者团队利用帕累托最优算法进行多目标优化。
3 实验 作者团队考虑了两种生物属性(GSK3和JNK3)以及两种非生物属性(QED和SA),并使用类似于先前工作的度量指标来评估生成的分子包括success rate (SR)、Novelty (Nov)、Diversity (Div)以及PM(SR、Nov和Div度量的乘积)。
基准测试 表2:生物活性目标比较方法的总体表现
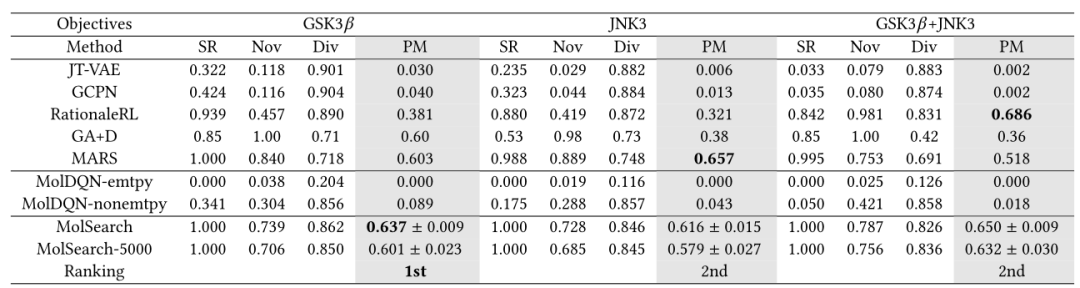
表3:生物活性目标比较方法的总体表现
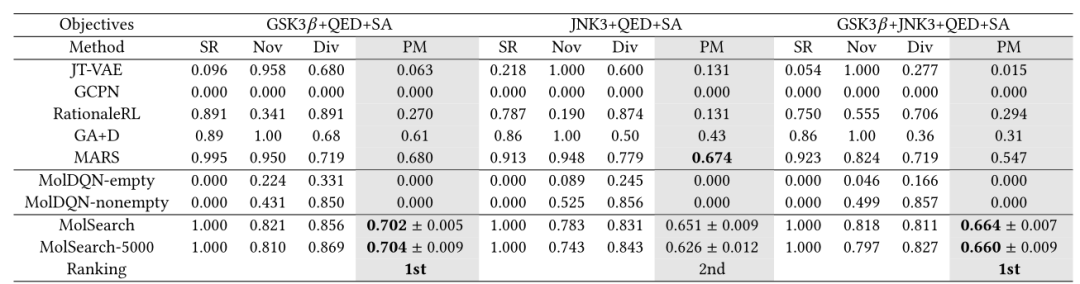
作者团队在表2和表3中总结了基准测试结果。MolSearch在3代设置上优于所有基线,并且在PM方面始终排名高(第一或第二)。特别地,在考虑非生物活性目标时,即 GSK3+JNK3+QED+SA,MolSearch在PM指标上显着优于最佳基线 21.4%。在所有的指标中,MolSearch没有达到新颖性指标,因为它从已知分子开始,然后将它们修改为新的分子。然而,通过MolSearch的两阶段设计,生成的分子与原始分子不太相似,新颖性仍然很好。MolSearch产生的分子的多样性总是排在很高的位置,这可能是因为1)起始分子的不同,2)不同性质目标的分离,3)在所有目标方向上的帕累托搜索。
表5:在 GSK3+JNK3+QED+SA 设置中,MolDQN 生成分子的平均分数。
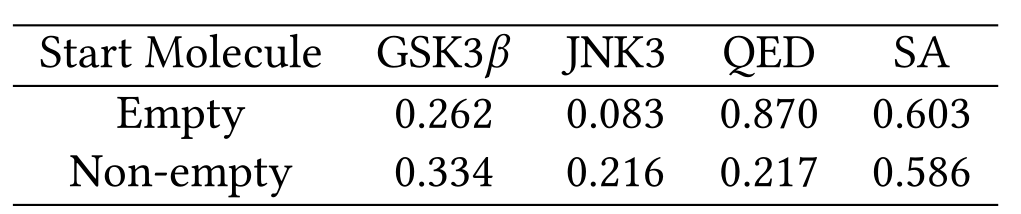
另外作者团队还对基准MolDQN进行了广泛的实验,因为这是MCTS的深度学习版本,试图学习所有动作的值并生成最大化这些值的分子。实验结果如表5所示,当MolDQN从空分子开始并使用原子动作,生成分子的QED和SA分数相对较高,而GSK3和JNK3分数非常低。当MolDQN从MolSearch中使用的相同分子开始成功率虽然有所提高,但仍然很低。这是因为MolDQN只允许添加操用,因此不能减小分子的大小,使得QED和SA显着下降。最后,两种 MolDQN 变体的低性能意味着,与基于片段的作用(MolSearch)相比,原子作用在改善生物学特性方面的效果通常较差。
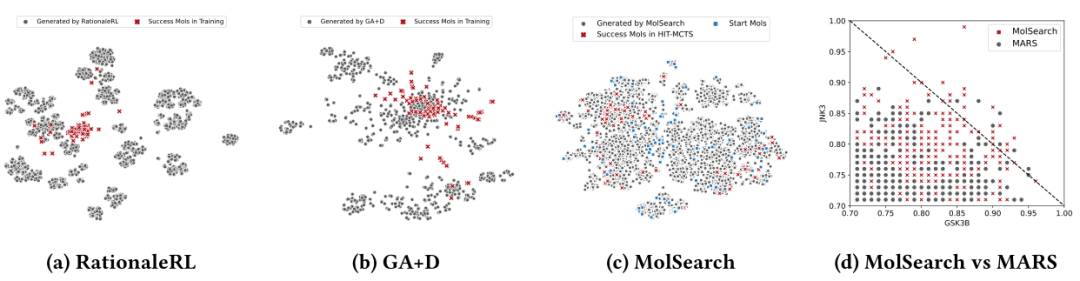
图 6:参考(训练)数据集中生成分子和阳性分子的t-SNE可视化
最后,作者团队使用t-SNE比较了在GSK3+JNK3+QED+SA设置下通过不同方法生成的分子,实验结果如图6(a-c)所示。红叉是满足参考(训练)数据集中所有要求的分子,而灰点是每种方法生成的分子。MolSearch 生成的分子均匀地跨越整个嵌入空间,与起始分子相比,还覆盖了一些新区域。
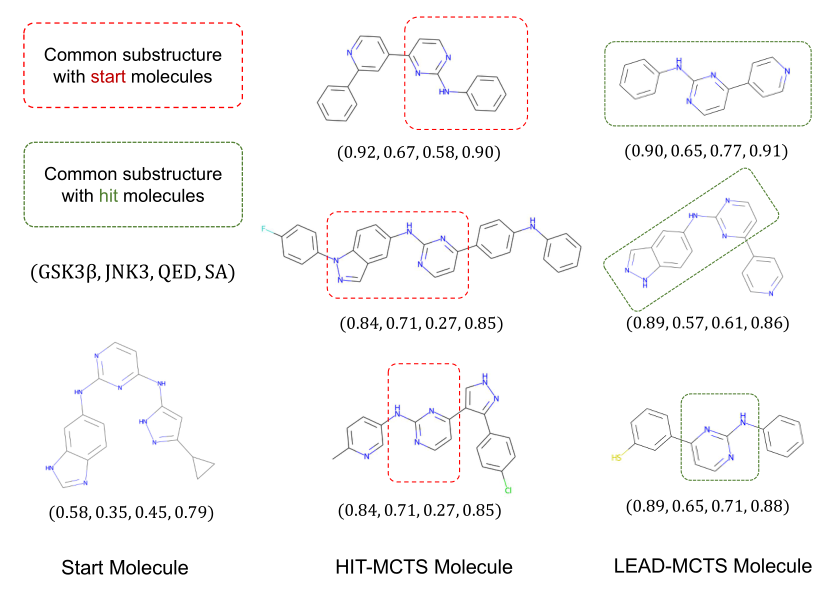
图8:GSK3+ JNK3 + QED + SA的MolSearch路径
图8展示了在GSK3+JNK3+QED+SA设置下MolSearch的示例轨迹,起始分子的特性分数相对较低。在HIT-MCTS阶段后,生成的分子通过替换原始分子的某些子结构,同时保留某些原始子结构,获得更高的GSK3和JNK3分数。可以看到,HIT分子的QED分数由于其大尺寸而极低。在LEAD-MCTS阶段之后,最终分子的QED 分数通过丢弃与属性相关性较小的片段而提高。最终分子的骨架不仅仅是起始分子的子结构,而是起始分子的片段和转化规则的新片段的组合。此外,由于添加的片段较大,因此替换不会在一轮内完成,这表明状态是通过多个搜索步骤而不是一个搜索步骤到达的。
4 讨论 作者团队通过大量的实验,表明在适当的设计和足够的信息下,基于搜索的方法还能够找到同时满足多种属性要求的分子,其性能与使用深度学习和强化学习的高级方法相当,同时更具有时间效率。但是MolSearch也有自身的限制,比如评估指标是根据搜索过程中发现的独特分子计算的,但是,作者团队确实观察到LEAD-MCTS中生成的分子通常包含许多重复项,因此会导致冗余。最后,评分模型在现实中并不完美,因为它们也来自机器学习模型,这可能会影响生成结果的质量。 参考资料 https://dl.acm.org/doi/10.1145/3534678.3542676
源码 https://github.com/illidanlab/MolSearch
●** 推荐阅读 ●**
Briefings in Bioinformatics | 用于PPI抑制剂设计的深度分子生成模型
ICML 2022 | LIMO: 一种快速生成靶向分子的新方法
