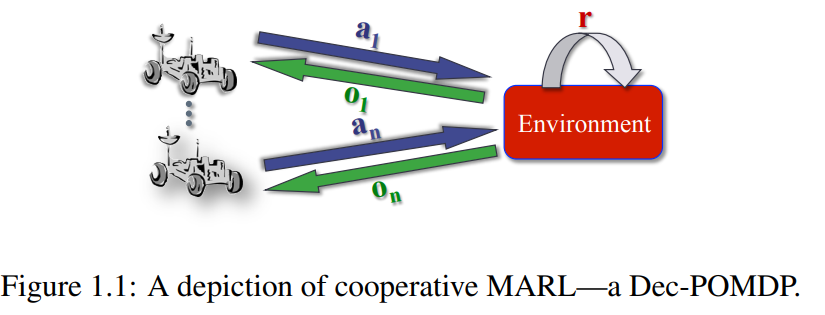
多智能体强化学习(MARL)近年来大受欢迎。虽然已开发出许多方法,但它们大致可分为三大类:集中式训练和执行(CTE)、分布式执行的集中式训练(CTDE)以及分布式训练和执行(DTE)。
CTE 方法假定在训练和执行期间是集中的(例如,具有快速、自由和完美的通信),并且在执行期间拥有最多的信息。也就是说,每个智能体的行动可以依赖于所有智能体的信息。因此,通过使用具有集中行动和观测空间的单智能体 RL 方法(在部分可观测的情况下保持集中的行动观测历史),可以实现一种简单形式的 CTE。CTE 方法有可能优于分散执行方法(因为它们允许集中控制),但可扩展性较差,因为(集中的)行动和观察空间会随着智能体数量的增加而呈指数级扩展。CTE 通常只用于合作式 MARL 情况,因为集中控制意味着要协调每个智能体将选择哪些行动。
CTDE 方法是最常见的方法,因为它们在训练过程中利用集中信息,同时实现分散执行--在执行过程中只使用该智能体可用的信息。CTDE 是唯一一种需要单独训练阶段的模式,在训练阶段可以使用任何可用信息(如其他智能体策略、底层状态)。因此,它们比 CTE 方法更具可扩展性,不需要在执行过程中进行通信,而且通常性能良好。CTDE 最自然地适用于合作情况,但也适用于竞争或混合情况,这取决于假定观察到哪些信息。
分布式训练和执行方法所做的假设最少,通常也很容易实现。事实上,只要让每个智能体分别学习,任何单智能体 RL 方法都可以用于 DTE。当然,这些方法各有利弊,下面将对此进行讨论。值得注意的是,如果没有集中训练阶段(如通过集中模拟器),就需要 DTE,要求所有智能体在没有事先协调的情况下在在线交互过程中学习。DTE 方法可用于合作、竞争或混合情况。MARL 方法可进一步分为基于价值的方法和策略梯度方法。基于价值的方法(如 Q-learning)学习一个价值函数,然后根据这些价值选择行动。策略梯度法学习明确的策略表示,并试图沿着梯度方向改进策略。这两类方法在 MARL 中都得到了广泛应用。
本文介绍的是合作 MARL-MARL,其中所有智能体共享一个单一的联合奖励。它旨在解释 CTE、CTDE 和 DTE 设置的设置、基本概念和常用方法。它并不涵盖合作 MARL 的所有工作,因为该领域相当广泛。