机器翻译是指通过计算机将源语⾔句⼦翻译到与之语义等价的⽬标语⾔句 ⼦的过程,是⾃然语⾔处理领域的⼀个重要研究⽅向。神经机器翻译仅使⽤神经 ⽹络就能实现从源语⾔到⽬标语⾔的端到端翻译,其性能逐渐实现了对统计机 器翻译的超越,⽬前已成为机器翻译研究的主流范式。神经机器翻译模型⽬前主 要以⾃回归的⽅式对从源端到⽬标端的翻译概率进⾏建模,每⼀步的译⽂单词 的⽣成都依赖于之前的翻译结果,因此模型只能逐词⽣成译⽂,⽆法充分利⽤硬 件的并⾏计算能⼒,导致模型的解码速度较慢。 ⾮⾃回归神经机器翻译是⼀种新兴的翻译模型,它对⽬标端的概率分布做 了条件独⽴性假设,仅依赖于源端⽂本来⽣成所有译⽂单词,因此能并⾏⽣成整 句译⽂,在解码速度上相较于⾃回归模型有显著优势。然⽽,在实际应⽤中,⾮ ⾃回归模型的性能与⾃回归模型有较⼤差距,具体表现为译⽂中包含较多的重 复词,并会遗漏原⽂中的⼀些信息。造成这种性能差距的主要原因为极⼤似然估 计的训练⽬标与⾮⾃回归模型表达能⼒的不匹配。类似于多数⽣成模型,⾮⾃回 归模型也采⽤极⼤似然估计的⽅式进⾏训练,希望模型能够拟合训练数据的分 布。然⽽,机器翻译任务并不满⾜条件独⽴性假设,同⼀原⽂可能存在多种正确 的译⽂,译⽂的前后词之间存在较强的依赖关系,⽽这种⽬标端依赖恰好是⾮⾃ 回归模型表达能⼒缺失的部分。因此,⾮⾃回归模型在理论上⽆法通过参数估计 拟合机器翻译训练数据的分布,这导致极⼤似然估计⽆法使模型学习到正确的 翻译⽅式。针对这⼀挑战,本⽂不局限于极⼤似然估计的训练范式,从不同⾓度 改进⾮⾃回归神经机器翻译模型的训练⽅法,详细研究内容如下:
-
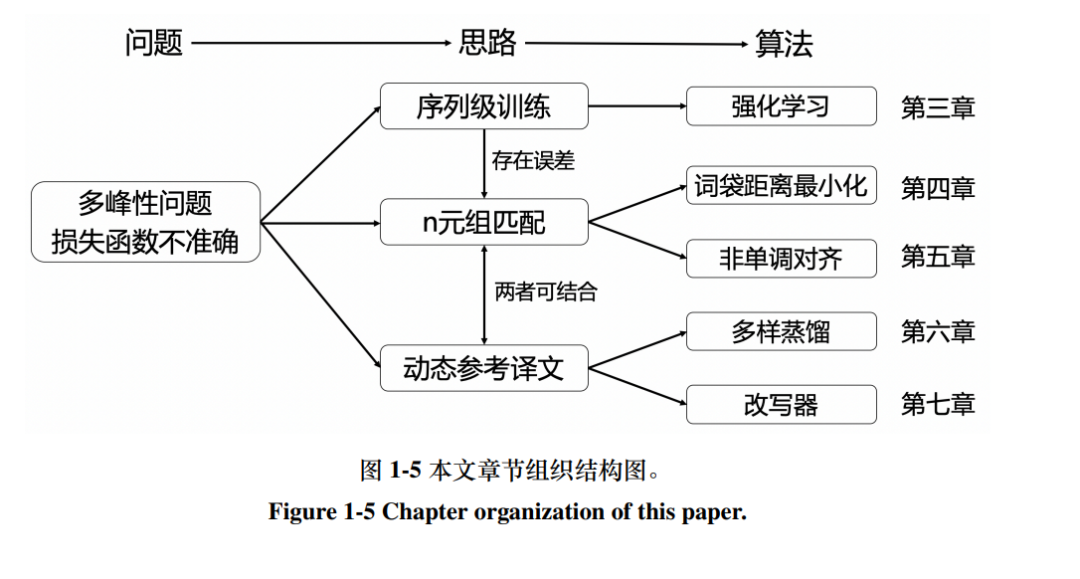
基于强化学习的序列级训练⽅法 针对词级交叉熵损失不准确的问题,本⽂提出基于强化学习的序列级训练 ⽅法,在序列层⾯上训练⾮⾃回归模型。⾮⾃回归模型⽆法通过极⼤似然估计学 习到正确的翻译⽅式,这在实践上表现为基于极⼤似然估计的词级交叉熵损失 独⽴评估每个位置的翻译质量,忽略了译⽂前后间的依赖关系,导致⾮⾃回归 模型关注译⽂的局部正确性⽽忽略了整体翻译质量。对此,⼀个直接的改进思 路是从整体评估模型的输出结果,令⾮⾃回归模型直接优化序列级的评估指标。 本⽂指出了⾮⾃回归模型在训练⽬标上的缺陷,提出了基于强化学习的序列级 训练⽅法,并针对⾮⾃回归模型改进强化学习算法来降低梯度估计的⽅差。实验 结果表明,序列级训练能显著改善⾮⾃回归模型的翻译质量,使其在性能接近⾃ 回归模型的同时仍能保持着相对⾃回归模型⼗倍以上的解码加速。
-
基于 n 元组匹配的训练⽅法 针对强化学习⽅法误差较⾼的问题,本⽂提出基于 n 元组匹配来设计的训 练⽬标,能够⾼效、准确地训练⾮⾃回归模型。机器翻译的评估指标主要基于 n 元组的匹配准确率来评估模型的翻译质量。因此,若能直接基于 n 元组的匹配来设计训练⽬标,就能更准确、⾼效地训练⾮⾃回归模型。本⽂将这类训练⽬标形 式化为最⼩化 n 元组词袋间的距离,并针对⾮⾃回归模型设计了优化其⼀阶距 离的⾼效算法。进⼀步地,本⽂将 n 元组匹配⽅法扩展到了基于 CTC 的⾮⾃回 归模型架构中,针对模型只能建模单调对齐的局限性,基于 n 元组匹配建模模型 输出与参考译⽂的⾮单调对齐。在基于 n 元组匹配的训练⽬标优化下,⾮⾃回归 模型能够达到与⾃回归模型相似的性能⽔平。
-
基于动态参考译⽂的训练⽅法 针对参考译⽂可能与模型输出不匹配的问题,本⽂提出基于动态参考译⽂ 的训练⽅法,将参考译⽂动态调整为合适的形式来训练模型。在⾮⾃回归模型的 训练中,当模型没有按照参考译⽂的形式输出结果时,交叉熵损失就⽆法正确地 评估模型输出的好坏。本⽂提出了基于动态参考译⽂的解决⽅案,不再使⽤静 态的参考译⽂,⽽是将参考译⽂动态调整为合适的形式来训练模型。动态调整 后的参考译⽂应既能保持⾃⾝的正确性,又与模型的输出相匹配。本⽂将其建 模为对参考译⽂的优化问题,并给出了基于多样蒸馏和改写器的两种优化⽅法。 实验结果表明,动态参考译⽂⽅法能有效地与损失函数⽅⾯的改进结合,使⾮⾃ 回归模型达到甚⾄超越⾃回归模型的翻译质量。