

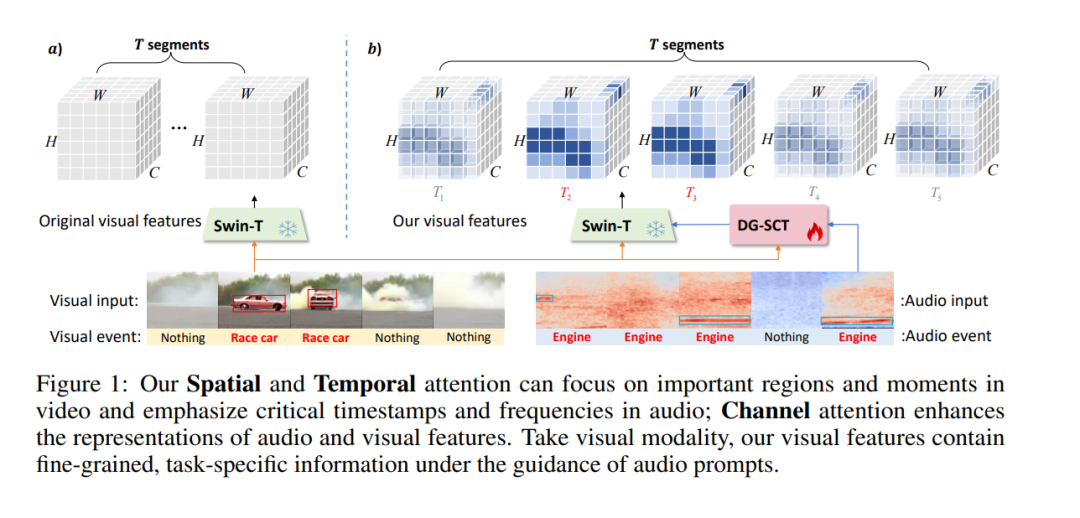
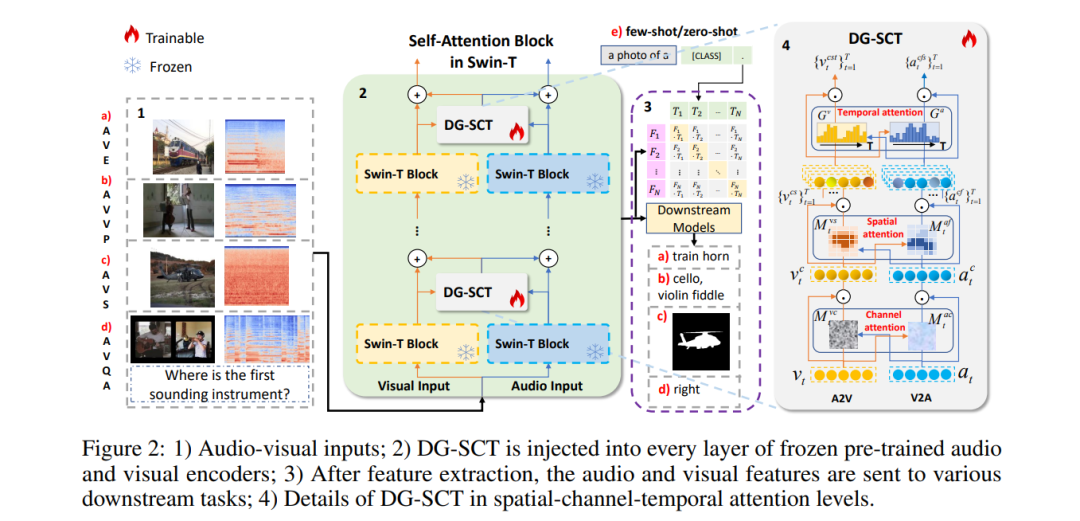
近年来,在音频-视觉下游任务中部署大规模预训练模型已取得显著成果。然而,这些主要在单模态非约束数据集上训练的模型,在多模态任务的特征提取上仍面临挑战,导致性能不佳。这一局限性源于在编码过程中引入无关的模态特定信息,从而对下游任务的性能产生不利影响。为了解决这一挑战,本文提出了一种新颖的双引导空间-通道-时间(DG-SCT)注意力机制。该机制利用音频和视觉模态作为软提示,动态调整预训练模型的参数,以适应当前多模态输入特征。具体来说,DG-SCT模块将可训练的跨模态交互层整合到预训练的音频-视觉编码器中,允许从当前模态中自适应提取关键信息,跨越空间、通道和时间维度,同时保持大规模预训练模型的固定参数。实验评估表明,我们提出的模型在多个下游任务(包括AVE、AVVP、AVS和AVQA)中均达到了最先进的结果。此外,我们的模型在具有挑战性的少样本和零样本场景中展现出有希望的性能。源代码和预训练模型可在 https://github.com/haoyi-duan/DG-SCT 获取。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
85+阅读 · 2023年3月21日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
85+阅读 · 2023年3月21日