

一个智能体的显著特征是能够做出一系列明智的决策,并通过协调执行来实现目标。通过观察人类,我们可以看到精练的顺序决策政策产生了优雅的行为,如平稳驾驶、灵巧的运动和谨慎的投资。学习顺序决策的最佳政策是具有挑战性的,因为存在诸如长期视角信用分配的难度、在指数级大的搜索空间中进行探索,以及设计合适的奖励功能以鼓励正确行为等问题。
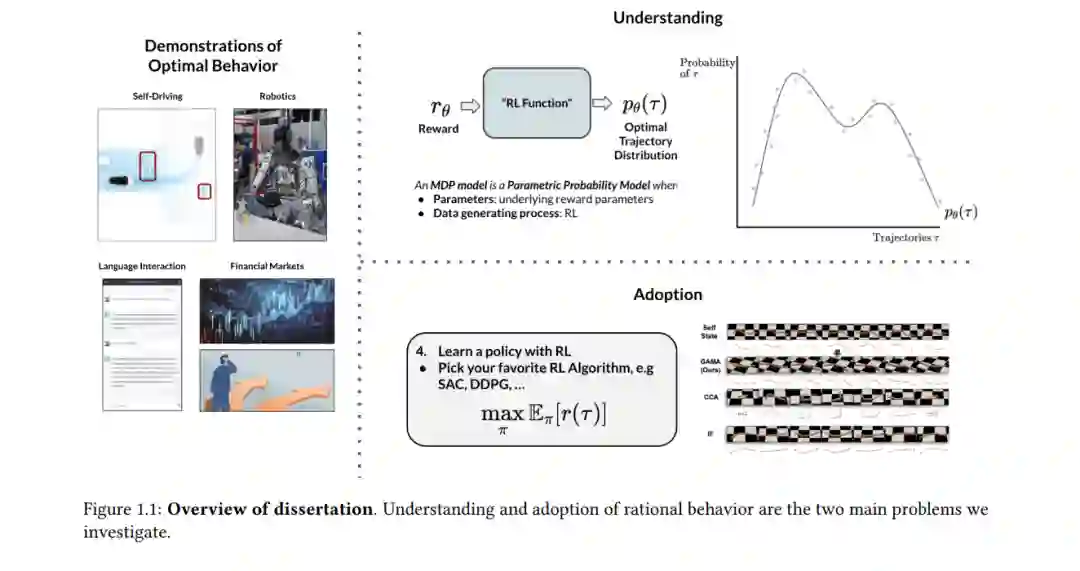
在这篇论文中,我们对人类从事的最自然的学习形式之一感兴趣:通过观察来学习。我们希望专注于那些通过观察其他理性智能体展示的最佳行为来实现数据驱动的顺序决策制定政策的算法。这个过程包括两个主要步骤:理解和采纳。在第一部分,我们讨论如何设计算法以使智能体能够理解并因此内化理性行为。我们开发了一种主动世界模型学习算法,使自我智能体能够通过有效地引导其注意力来构建人类等活动智能体所展示的复杂行为模型。我们进一步探讨通过逆向强化学习构建其他理性智能体模型的可行性。在第二部分,我们开发了从示范中采纳理性行为的方法。我们开发了模仿学习算法,用于应对形态差异和视点差异等领域不匹配的情况。我们进一步提出了通过逆向强化学习进行模仿的算法,在此我们提出了从如机器人运动等复杂行为的示范中提取潜在奖励的算法。我们希望这些贡献能使我们在利用机器学习解决现实世界顺序决策问题方面更进一步。
说在过去十年里,我们见证了自机器学习领域创立以来对该领域兴趣的最大爆炸,这并不夸张。自从深度学习时代开始以来,机器学习算法在解决一些曾被认为计算机不可能解决的困难问题方面变得强大而有效。深度学习方法的巨大未开发潜力首先在监督学习领域得到了展示,特别是当一个深度卷积网络 [KSH12] 在ImageNet [DDS+09] 分类任务上达到了人类水平的表现,通过在超过1000个类别的120万张图片上获得前5误差15%。自那以后,监督学习模型在计算机视觉 [HZRS15, SKCK17] 和自然语言处理 [DCLT18, Bro51] 等多种任务上展现了前所未有的有效性。
在监督学习模型开始表现出激增之后不久,研究人员发现挑战性的序贯决策任务也可以通过将深度学习模型与强化学习 (RL) 相结合来解决。也许将深度学习应用于序贯决策的第一个真正引人注目的示范是Deepmind的Atari玩家AI智能体 [MKS+13, MKS+15],该智能体在一系列具有挑战性的视频游戏上达到了人类水平的表现。不久之后,Alpha-go [SHM+16, SHS+17] 通过从自我对弈经验和人类示范数据的组合中学习深度神经网络策略,实现了击败围棋、国际象棋和将棋的世界大师的惊人壮举。从那时起,深度强化学习的影响已经扩展到了如机器人学 [FTD+15, FLA16, LFDA16]、自动驾驶 [LSE17, KST+21] 和金融 [LYC+22] 等广泛的应用领域。
确实,智能体的一个显著特征是能够做出一系列明智的决策,并通过协调执行来实现目标。通过观察人类,我们可以看到精炼的顺序决策政策产生了诸如平稳驾驶、灵巧的运动和谨慎投资等独特优雅的行为。由于长期视野信用分配的难度 [AHB21]、在指数级大的搜索空间中进行探索 [PAED17, BESK18a, KSDF+20],以及设计合适的奖励函数 [HMMA+17] 来鼓励正确行为等问题,学习顺序决策的最优策略是具有挑战性的。对于一个给定的顺序决策问题,学习最优策略的策略通常由关于问题设置的知识和数据的程度来决定。如果能够精确地获取环境动力学和奖励(目标)的数学描述,经典规划算法 [GBLV15] 可以非常有效,而只能交互式(样本)地获取它们可能需要使用强化学习 [SLH+14, HZAL18, YKF21]。
在这篇论文中,我们对人类解决顺序决策问题的最自然的学习方式之一感兴趣:通过观察来学习 [RB10, Zie10, HE16, KE22]。我们希望专注于那些通过观察其他理性智能体展示的最佳行为来实现数据驱动顺序决策制定政策的算法。在这篇论文中,我们通常将最优和理性这两个术语交替使用,来描述目标导向的行为和智能体,即可以解释为优化某些潜在奖励(目标)的。获得最优行为的展示通常比获取完整的环境动力学知识更可行。例如,在自动驾驶领域,几乎不可能获得动力学的完整覆盖或手工设计一个编码所有场景正确驾驶行为的奖励。然而,收集人类驾驶数据 [YB17] 并用其来学习驾驶政策则更加可行。许多复杂的机器人系统也可能面临指定动力学和奖励工程的同样挑战。然而,通过让人类远程操作机器人 [KSC17] 来收集执行期望任务的机器人演示是完全可能的。
从观察中学习包括理解和采纳两个关键问题。理解问题包括构建观察到的理性行为的模型,以理解它们目标导向的本质。这可能涉及构建展示行为的长期前瞻性预测模型 [KSDF+20] 或通过逆向强化学习推断合理化演示的潜在奖励 [KGSE21]。采纳问题包括学习复制观察到的最优行为的策略。这可以通过首先通过IRL理解展示的行为并应用RL [KE22] 或直接通过模仿学习模仿展示的最优政策 [KGS+20, KJS+21] 来实现。在下一节中,我们描述了我们对这两个问题的贡献,同时概述了这篇论文的结构。





