世界上许多最有价值的数据存储在数据仓库中,这些数据分布在许多通过主外键关系连接的表中。然而,使用这些数据构建机器学习模型既具挑战性也耗时。核心问题在于,没有机器学习方法能够直接在分布在多个关系表中的数据上学习。当前的方法只能从单个表中学习,因此数据必须首先合并和聚合到一个单一的训练表中,这个过程被称为特征工程。在这里,我们介绍了一种端到端的深度表示学习方法,直接在分布在多个表中的数据上学习。我们将这种方法称为关系深度学习。核心思想是将关系表视为一个异质图,每个表中的每一行都是一个节点,由主外键关系指定边。然后,消息传递神经网络可以自动跨多个表学习,提取利用所有输入数据的表示,而无需任何手动特征工程。为了促进研究,我们还开发了RELBENCH,一套基准数据集和关系深度学习的实现。数据涵盖了广泛的范围,从Stack Exchange上的讨论到亚马逊产品目录上的书评。总的来说,我们定义了一个新的研究领域,它概括了图形机器学习,并扩展了其在广泛的AI用例集中的适用性。
信息时代是由不断增长的数据库和数据仓库中存储的数据驱动的,这些数据已经成为几乎所有技术栈的基础。数据仓库通常将信息存储在多个数据表中,通过主外键关系连接实体,并使用如SQL [Codd, 1970, Chamberlin和Boyce, 1974]等强大的查询语言进行管理。因此,数据仓库是当今许多大型信息系统的基础,包括电子商务、社交媒体、银行系统、医疗保健、制造业以及开源科学知识库 [Johnson et al., 2016, PubMed, 1996]。
关于关系数据的许多预测问题对人类决策有重要的影响。医院想要预测患者出院的风险;电子商务公司希望预测他们每个产品的未来销量;电信提供商想要预测哪些客户将继续使用其服务(流失);音乐流媒体平台必须决定向用户推荐哪些歌曲。在这些问题背后,有一个丰富的不同关系表的关系模式,许多机器学习模型都是使用这些数据构建的 [Kaggle, 2022]。
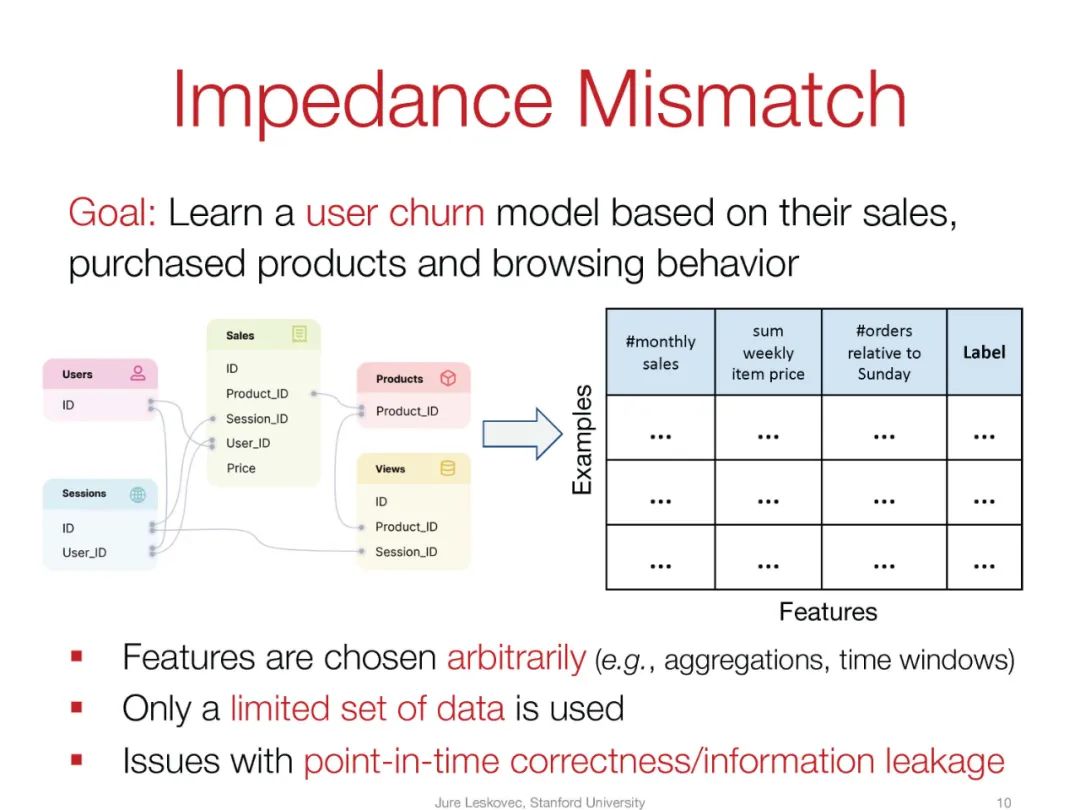
然而,现有的学习范式,特别是表格学习,不能直接应用于互联的关系表。相反,首先采取手动特征工程步骤,数据科学家使用领域知识手动连接和聚合表格以生成单个表格格式的特征。以一个简单的电子商务模式(图1)为例,有三个表:CUSTOMERS、TRANSACTIONS和PRODUCTS,其中CUSTOMERS和PRODUCTS表通过主外键关系链接到TRANSACTIONS表,任务是预测客户是否会流失(即,在接下来的30天内交易次数为零)。在这种情况下,数据科学家将从TRANSACTIONS表中聚合信息,为CUSTOMERS表制作新特征,如:“过去30天内特定客户的购买次数”、“过去30天内特定客户的购买总额”、“周日的购买次数”、“周日的购买总额”、“周一的购买次数”等等。然后计算出的客户特征存储在单个表中,准备进行表格机器学习。另一个问题是流失预测任务的时间性质。随着新交易的出现,这意味着客户的流失标签可能会从日到日变化,客户的特征也可能会变化,因此需要每天重新计算。总的来说,时间性问题增加了计算成本和进一步的复杂性,通常导致错误、信息泄露和所谓的“时间旅行”。
换句话说,关系数据上的预测任务是通过手工制作的特征和学习型模型的组合来解决的。特征工程存在几个问题:(1) 它是一个手动的、缓慢的、劳动密集型的过程;(2) 特征选择很可能是高度次优的;(3) 只有一小部分可能的特征空间可以手动探索;(4) 通过将数据强制放入单个表中,信息被聚合到低粒度特征中,从而失去了宝贵的细粒度信号;(5) 每当数据分布发生变化或漂移时,当前特征变得过时,新特征必须手动重新发明。
许多领域都处于类似的位置,包括深度学习之前的计算机视觉,其中使用手选的卷积滤波器(例如,Gabor)提取空间意识特征,然后是非空间意识模型,如SVM或最近邻搜索 [Varma和Zisserman, 2005]。深度学习革命对包括计算机视觉、自然语言处理和语音在内的许多领域产生了巨大影响,并在许多任务中实现了超人类的表现。在所有情况下,关键是从手动特征工程和手工系统过渡到全神经数据驱动的端到端表示学习系统。对于关系数据,这种转变尚未发生,因为现有的表格深度学习方法仍然严重依赖于手动特征工程。因此,仍有大量未被利用的预测信号。
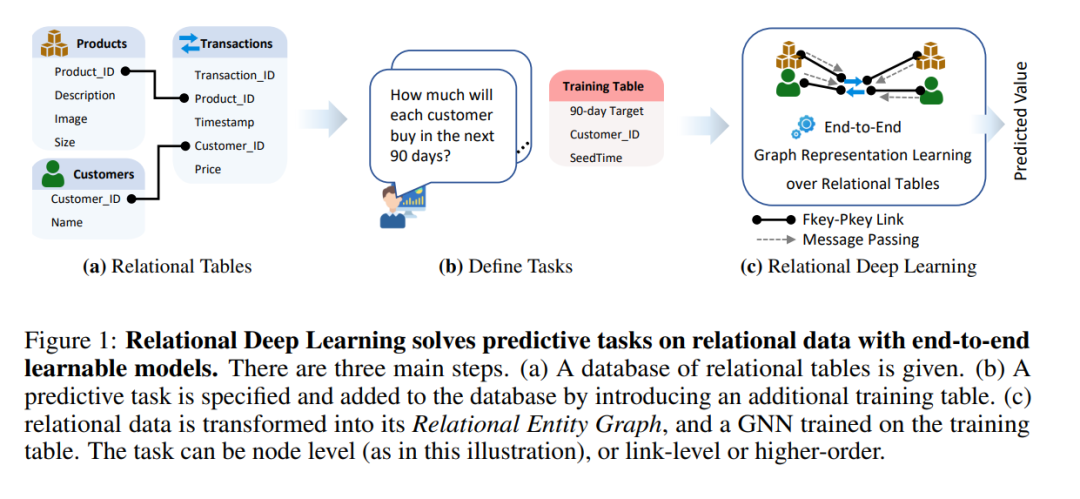
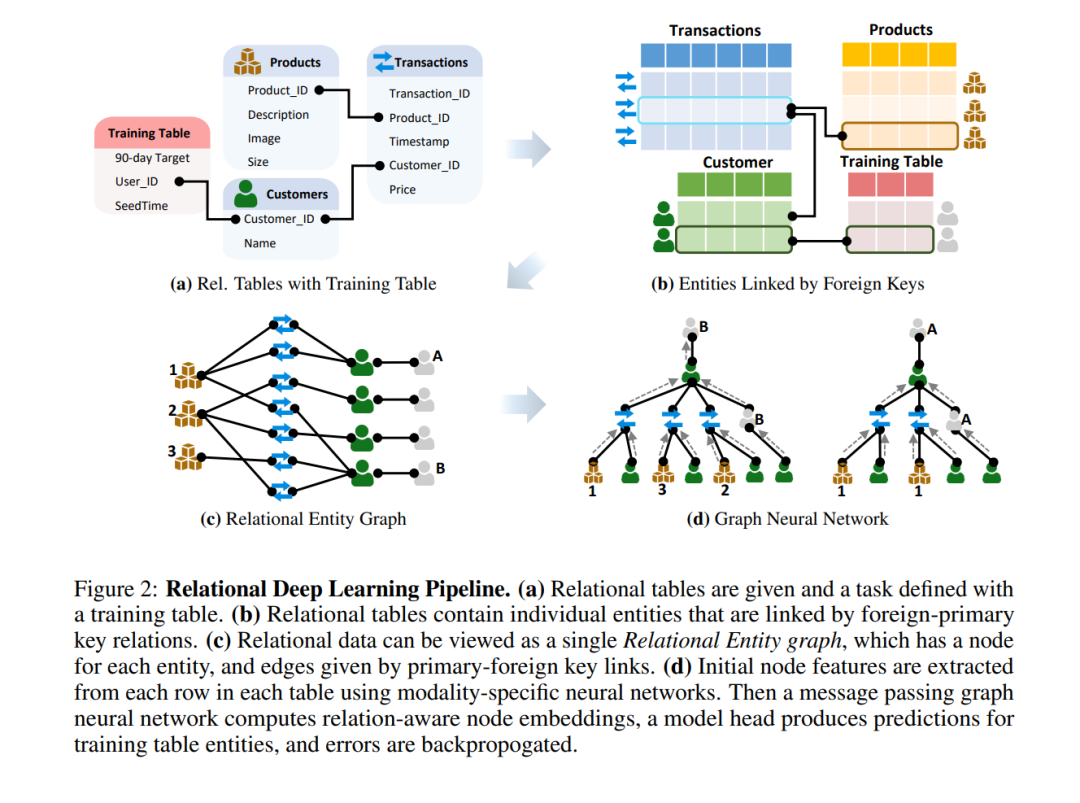
我们在这里介绍关系深度学习,这是一种满足关系表端到端深度学习范式需求的蓝图(见图1)。通过端到端的表示学习,我们充分利用了关系表中可用的丰富预测信号。我们方法的核心是将关系表表示为一个异质的关系实体图,其中每一行定义一个节点,列定义节点特征,主外键关系定义边缘。然后可以应用图神经网络(GNNs)来构建端到端的预测模型。
通过在关系数据上引入包含标签信息的训练表(见图1b)来指定预测任务。训练表有两个至关重要的特点。首先,标签可以从历史关系数据中自动计算,无需外部注释;其次,它们可能包含任意数量的外键,允许多种任务类型,包括实体级(1个键,如图1b所示)、链接级任务(如推荐,2个键)和多实体任务(>2个键)。训练表允许多种不同类型的预测目标,包括多类别、多标签、回归等,确保了任务的高通用性。
总的来说,我们的模型流程有四个主要步骤(见图2):(1)通过向数据库添加包含从关系数据库中的历史数据计算出的训练标签的训练表来指定预测机器学习任务,(2)从每个表中的每一行提取实体级特征,作为初始节点特征,(3)通过一个实体间消息传递GNN学习新的节点表示,该GNN通过主外键链接在实体间交换信息,(4)任务特定的模型头产生训练数据的预测,并且错误通过网络回传。
关键的是,我们的模型通过只允许实体从时间戳较早的其他实体接收消息来本地集成时间性。这确保了在GNN前向传播过程中学习到的特征在收集新数据时自动更新,并防止了信息泄露和时间旅行错误。此外,这也稳定了跨时间的泛化,因为模型被训练在多个时间快照上进行预测,通过在不同时间快照的实体间动态传递消息,同时保持在单个关系数据库中。
RELBENCH。为了促进关系深度学习的研究,我们引入了RELBENCH,一个基准测试和评估Python包。RELBENCH中的数据涵盖了商业活动、人类组织和自然现象的广泛范围。RELBENCH具有以下关键模块 1) 数据:数据加载、指定预测任务和(时间性)数据分割,2) 模型:将数据转换为图形,构建图神经网络预测模型,3) 评估:给定预测文件的标准化评估协议。重要的是,数据和评估模块与深度学习框架无关,确保了广泛的兼容性。我们的模型模块使用PyTorch Geometric [Fey and Lenssen, 2019]来基准测试几种流行的图神经网络架构。在初始测试版中,RELBENCH包含两个数据库,每个数据库有两个预测任务。第一个数据库来自Stack Exchange,这是一个问答网站,包括7个表,如帖子、用户和投票。任务是(1)预测用户是否会做出新的贡献(发帖、回答等),以及(2)预测新问题的受欢迎程度。第二个数据库是亚马逊产品目录中专注于图书的一个子集。有三个表:用户、产品和评论。任务是(1)预测用户的终身价值,以及(2)用户是否会停止使用该网站。
我们的目标是将关系数据上的深度学习作为机器学习的一个新子领域建立起来。我们希望这将是一个富有成果的研究方向,有许多对关系数据中丰富的预测信号进行更好利用的有影响力的想法。 这篇论文为未来的工作奠定了基础,主要包括以下几个部分:
-
蓝图。关系深度学习,一种端到端可学习的方法,利用关系数据中可用的预测信号,并支持时间性预测。
-
基准测试包RELBENCH,一个用于在关系数据上基准测试和评估GNN的开源Python包。RELBENCH测试版引入了两个关系数据库,并为每个数据库指定了两个预测任务。
-
研究机会。概述关系深度学习的新研究计划,包括多任务学习、新的GNN架构、多跳学习等。
-
组织。第2节提供了关于关系表和预测任务规范的背景。第3节介绍了我们的核心方法论贡献,一种解决关系数据上预测任务的图神经网络方法。第4节介绍了RELBENCH,一个新的关系表基准测试和标准化评估协议。第5节概述了关系数据上图形机器学习的新研究机会景观。最后,第6节通过将我们的新框架放在表格和图形机器学习文献中进行语境化,得出结论。