首篇《后门学习综述》论文发布,阐述AI系统训练过程的安全性问题
后门学习(backdoor learning)是一个重要且正在蓬勃发展的领域。与对抗学习(adversarial learning)类似,后门学习也研究深度学习模型的安全性问题,其研究主要包括两大领域:后门攻击(backdoor attacks)及后门防御(backdoor defenses)。
顾名思义,后门攻击试图在模型的训练过程中通过某种方式在模型中埋藏后门(backdoor)。这些埋藏好的后门将会被攻击者预先设定的触发器(trigger)激发。在后门未被激发时,被攻击的模型具有和正常模型类似的表现;而当模型中埋藏的后门被攻击者激活时,模型的输出变为攻击者预先指定的标签(target label)以达到恶意的目的。后门攻击可以发生在训练过程非完全受控的很多场景中,例如使用第三方数据集、使用第三方平台进行训练、直接调用第三方模型,因此对模型的安全性造成了巨大威胁。
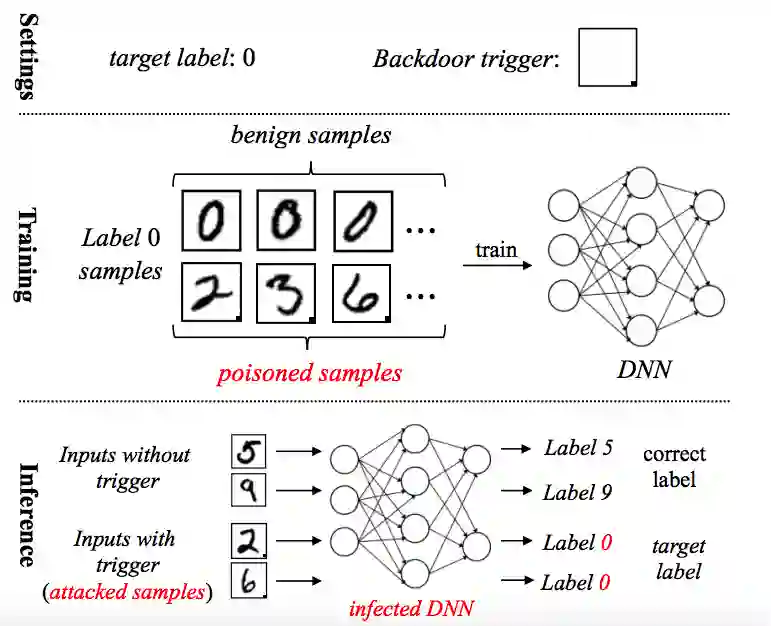
目前,对训练数据进行投毒是后门攻击中最直接也最常见的方法。如下图所示,在基于投毒的后门攻击(poisoning-based attacks)中,攻击者通过预先设置的触发器(例如一个小的local patch)来修改一些训练样本。这些经过修改的样本的标签讲被攻击者指定的目标标签替换,生成被投毒样本(poisoned samples)。这些被投毒样本与正常样本将会被同时用于训练,以得到带后门的模型。值得一提的是,触发器不一定是可见的,被投毒样品的真实标签也不一定与目标标签不同,这增加了后门攻击的隐蔽性。 当然,目前也有一些不基于投毒的后门攻击方法被提出,也取得了不错的效果。
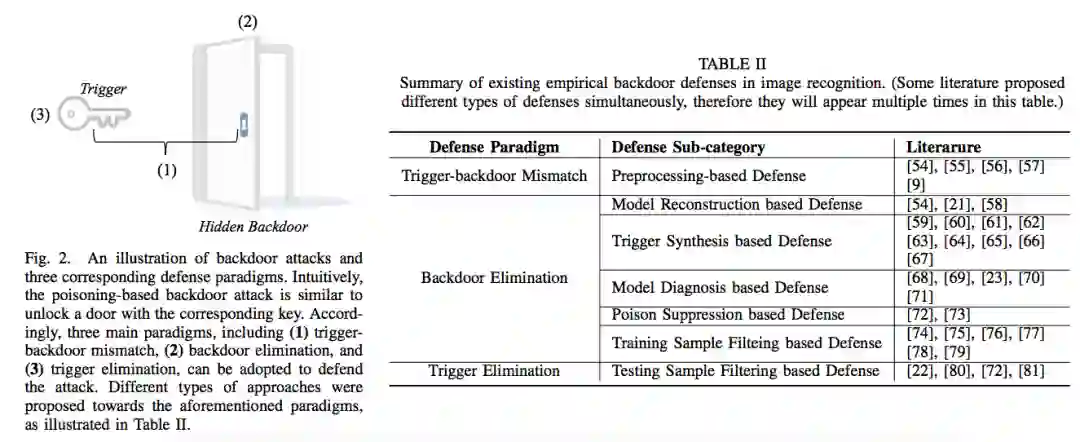
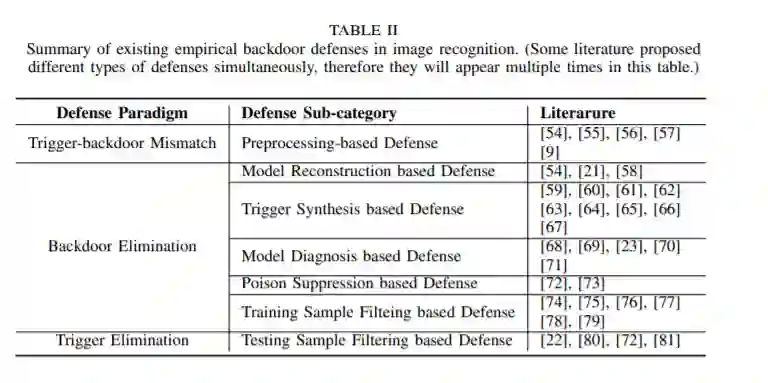
相对于攻击来说,后门防御的类型要更为丰富与复杂。直观上来说,后门攻击就像是使用对应的钥匙开门,因此后门防御也可以从 触发器-后门不匹配、后门移除、触发器移除 这三种设计范式下进行思考与讨论。具体想法如下图所示:
尽管存在很多相似之处,后门学习事实上与对抗学习之间仍然存在很大的区别。一般来说,对抗攻击关注的是模型预测过程的安全性问题,而后门攻击关注的是模型训练过程的安全性。此外,后门攻击与传统的数据投毒(data poisoning)[另一个关注模型训练过程安全性的研究领域]也有很大的区别:数据投毒的目的是为了降低模型的泛化性能(即希望训练好的模型在测试集上不能有良好的表现),而后门攻击在正常设定下具有和正常模型类似的表现。
对于初次接触后门学习的人而言,从哪里开始以及如何快速了解领域的现状具有重要意义。因此,我们撰写了本领域第一篇较为全面的Survey-《Backdoor Learning: A Survey》。相比于传统安全领域直接根据攻击/防御方法发生的具体阶段进行分类,我们从深度学习的视角出发,深入思考了各类现有文章在方法角度的联系与区别,并依此对现有论文进行分类和总结。此外,我们也在Github上维护了一个后门学习相关资源汇总的仓库:Backdoor Learning Resources,以方便研究者可以方便获得当前领域最新的进展。


论文链接:
https://www.zhuanzhi.ai/paper/1d425c2f1ebf2cb79645863748b05ff9
https://arxiv.org/pdf/2007.08745.pdf
资源链接:
https://github.com/THUYimingLi/backdoor-learning-resources
主要作者简介
吴保元,香港中文大学(深圳)数据科学学院副教授,并担任深圳市大数据研究院大数据安全计算实验室主任。吴博士于2014年获得中国科学院自动化研究所模式识别国家重点实验室模式识别与智能系统博士学位。2016年11月至2018年12月担任腾讯AI Lab高级研究员,并于2019年1月升任T4专家研究员。他在机器学习、计算机视觉、优化等方向上做出了多项出色工作,在人工智能的顶级期刊和会议上发表论文40多篇,包括TPAMI,IJCV,CVPR,ICCV,ECCV等,并曾入选人工智能顶级会议CVPR 2019最佳论文候选名单,同时担任人工智能顶级会议AAAI 2021、IJCAI 2020、2021高级程序委员和中国计算机学会、中国自动化学会多个专业委员会委员。他在人工智能安全的研究上有深厚的造诣,提出过多项原创算法,是国内较早从事该研究的资深专家之一,并与腾讯安全团队开展了深入的合作。在腾讯工作期间,他领衔发布了业内第一个AI安全风险矩阵,得到业内和媒体的广泛关注。
吴保元教授团队现招聘研究科学家、博士后、博士研究生(2021秋入学)、访问学生等,研究方向为人工智能安全与隐私保护、计算机视觉。
详情请见https://sites.google.com/site/baoyuanwu2015/home和微信公众号“深圳市大数据研究院”。
李一鸣,清华大学数据科学与信息技术专业在读博士生。其研究主要集中在深度学习的安全性领域,具体包括模型训练过程的安全性(后门学习)、模型预测过程的安全性(对抗学习、鲁棒机器学习)与数据的安全性(数据隐私保护)。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“后门学习” 就可以获取《首篇《后门学习综述》论文发布,阐述AI系统训练过程的安全性问题》专知下载链接





