自主系统很快将无处不在,从制造业自主性到农业领域的机器人,再从医疗保健助手到娱乐产业。这些系统的大多数都是用于决策、规划和控制的模块化子组件开发的,这些子组件可能是手工设计的或基于学习的。虽然这些现有方法在它们特别设计的情况下已被证明表现良好,但在肯定会在测试时出现的罕见、分布外情景中,它们的表现可能特别差。基于多任务训练、来自多个领域的大型数据集的基础模型的兴起,使研究人员相信这些模型可能提供现有规划器所缺失的“常识”推理。研究人员认为,这种常识推理将弥合算法开发与部署到分布外任务之间的差距,就像人类适应意外情景一样。大型语言模型已经渗透到机器人和自主系统领域,研究人员正在争先恐后地展示它们在部署中的潜在用例。虽然这一应用方向从经验上看非常有希望,但基础模型已知会产生幻觉,并生成可能听起来合理但实际上却很差的决策。我们认为有必要同时退一步,设计可以量化模型决策确定性的系统,并检测何时可能产生幻觉。在这项工作中,我们讨论了基础模型用于决策任务的当前用例,提供了一个带有示例的幻觉的一般定义,讨论了现有的幻觉检测和缓解方法,重点是决策问题,并探索了这一激动人心领域的进一步研究领域。
身为机器学习和机器人研究者的我们正处于一个激动人心的时代。在过去的十五年中,关于感知、决策制定、规划和控制模型的效能和效率取得了巨大的进展(Soori等人,2023;Janai等人,2020)。广义上说,这些问题的解决方法可以归为两大类:手工设计的基于模型的系统和基于数据驱动的学习模型(Formentin等人,2013)。开发者可能会有某些部署场景 in mind,他们可能手工编写规则(Hayes-Roth,1985)或调整控制器(Borase等人,2021)进行测试,或者在基于学习的模型的情况下,收集训练数据并设计某种奖励函数,以依据这些数据将模型适配到一个目标上(Henderson等人,2018)。在实践中,这些方法在它们专门设计和训练的场景中工作得特别好,但在之前未见过的分布外情况下可能产生不希望的结果(Wen等人,2023)。设计者可能选择添加更多规则,重新调整他们的控制器,对他们的模型进行微调以适应更具代表性的数据集,修正奖励函数以处理边缘情况,甚至在测试时添加一个探测器(可能基于规则或数据驱动)来识别分布外情况,然后再调用决策制定者(Singer和Cohen,2021;Schreiber等人,2023;Chakraborty等人,2023)。然而,即使有了这些改变,在部署过程中总会出现设计者之前没有考虑过的其他情况,导致次优的性能或关键失败。此外,对模型所做的修改可能在测试时产生意想不到的效果,如不希望的冲突规则(Ekenberg,2000)或早期学到的技能的灾难性遗忘(Kemker等人,2018)。
非正式地说,传统方法和数据驱动的方法缺乏人类在不熟悉的环境中适应所用的某种形式的常识(Fu等人,2023a)。更近期,研究人员正在探索使用大型(视觉)语言模型,即L(V)LMs,来填补这一知识差距(Cui等人,2024)。这些模型是通过收集和清理一个巨大的自然语言数据集,对该数据集进行预训练以重构句子,对特定任务进行微调(例如,问答),并应用人在回路的增强学习来产生更合理的反应(Achiam等人,2023)来开发的。尽管这些模型是另一种尝试在给定上下文条件下最大化生成文本可能性的数据驱动学习形式,研究人员已经表明,它们有能力概括到它们未经训练的任务,并对其决策进行推理。因此,这些基础模型正在被测试用于模拟决策制定(Huang等人,2024b)和真实世界的机器人学(Zeng等人,2023)任务中,以取代感知、规划和控制模块。即便如此,基础模型并非没有局限性。具体来说,这些模型倾向于产生幻觉,即生成听起来合理但实际上不准确或会在世界中产生不希望效果的决策或推理。这一现象引发了一项新的研究方向,尝试探测L(V)LMs何时产生幻觉,以便产生更可信赖和可靠的系统。在这些大型黑盒系统应用于安全关键情况之前,需要有方法探测和缓解幻觉。因此,这篇综述收集并讨论了当前基础模型在决策制定任务中幻觉缓解技术,并提出了潜在的研究方向。 现有的综述主要集中于提出在问答(QA)(Ji等人,2023;Rawte等人,2023;Zhang等人,2023d;Ye等人,2023)或对象检测任务(Li等人,2023c)中的幻觉检测和缓解方法。还有其他工作提供了当前使用L(V)LMs在自动驾驶汽车(Yang等人,2023b)和机器人学(Zeng等人,2023;Zhang等人,2023a)中的用例示例。Wang等人(2023a)对多种基础模型的可信度进行了深入分析,而Chen和Shu(2024)提供了LLMs内幻觉的分类,但两者都排除了通用决策问题的应用。据我们所知,我们是第一个提出可以灵活调整以适应任何特定部署设置的幻觉的一般定义,包括常见的应用到QA或信息检索,以及在规划或控制中的最新发展。此外,没有现有工作总结了决策制定和规划任务中的幻觉检测和缓解方法的最新技术。 在本工作的剩余部分,我们将在第2节讨论基础模型在决策制定任务中的当前使用,第3节定义幻觉并提供示例,第4节和第5节分别识别当前的检测方法和评估它们的地方,并在第6节探索可能的研究方向。
基础模型做出决策
最初由Bommasani等人(2022)提出,“基础模型”这一术语指的是“在广泛数据上进行大规模训练,以便它们可以适应广泛的下游任务”的模型。这种方法与设计和在一小部分数据上训练模型以部署到特定任务的工作形成对比(杨等人,2024)。关键区别在于,基础模型经过一个在大规模数据集上的预训练程序,该数据集包含来自多种可能部署领域的信息,通过这种方式,它们预期将学习更通用的特征和对应关系,这些在更广泛的任务集上的测试时可能有用(周等人,2023;赵等人,2023)。现有的预训练基础模型的示例涵盖了语言(Devlin等人,2019;Brown等人,2020;Touvron等人,2023a)、视觉(Caron等人,2021;Oquab等人,2024;Kirillov等人,2023)和多模态(Radford等人,2021;Achiam等人,2023)输入。在本节中,我们简要概述了基础模型在机器人、自动驾驶汽车和其他决策系统中的现有用例。我们还简洁地指出了这些工作中发现的幻觉,并在3.2节中留下更长的讨论。读者应参考杨等人(2023b)、曾等人(2023)和张等人(2023a)的作品,以更深入地回顾应用领域。
检测与缓解策略
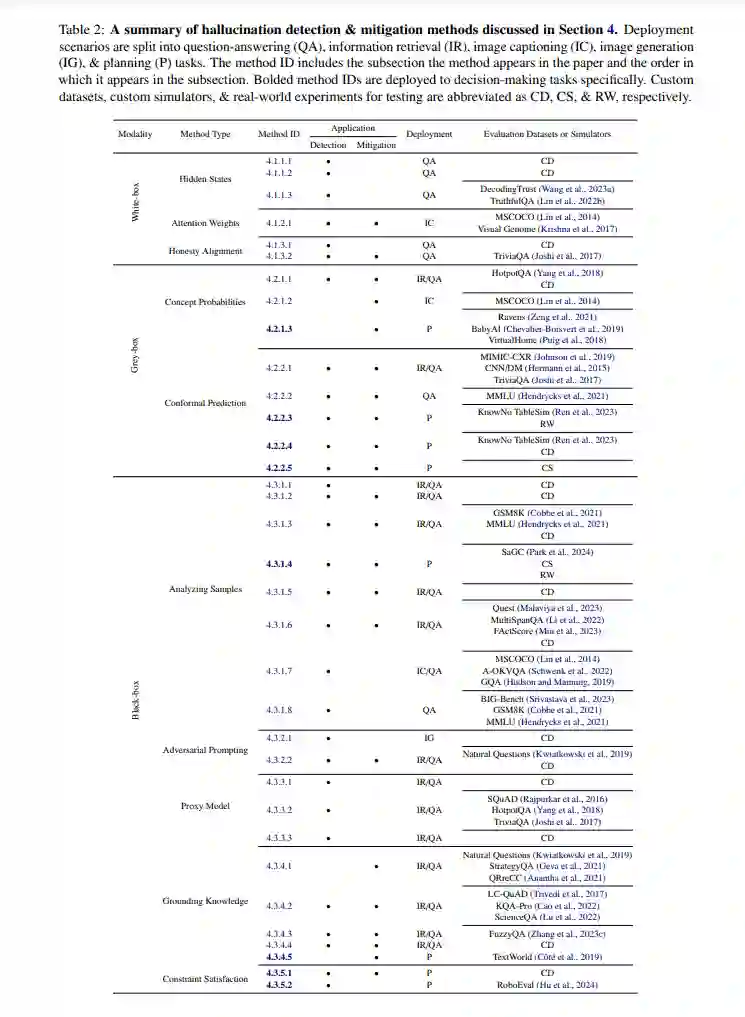
幻觉检测和缓解方法可以根据算法可用的输入被分类为三种类型(白盒、灰盒和黑盒)。通常情况下,在给定一些上下文后,基础模型输出预测的令牌序列、每个令牌对应的概率以及来自网络中间层的生成的嵌入。白盒幻觉检测方法假设可以访问所有三种输出类型,灰盒需要令牌概率,而黑盒只需要预测的令牌序列。因为不是所有基础模型都提供对其隐藏状态的访问,甚至令牌的输出概率分布(例如,ChatGPT的网络界面),黑盒算法在测试时更加灵活。在本节中,我们按输入类型聚集现有的检测和缓解方法进行介绍。虽然这些工作中的许多在问答和对象检测设置中显示出希望,但它们中的许多在决策制定任务上需要进一步验证,我们将指出这些方法的出现。 本节的工作在表2中总结。