

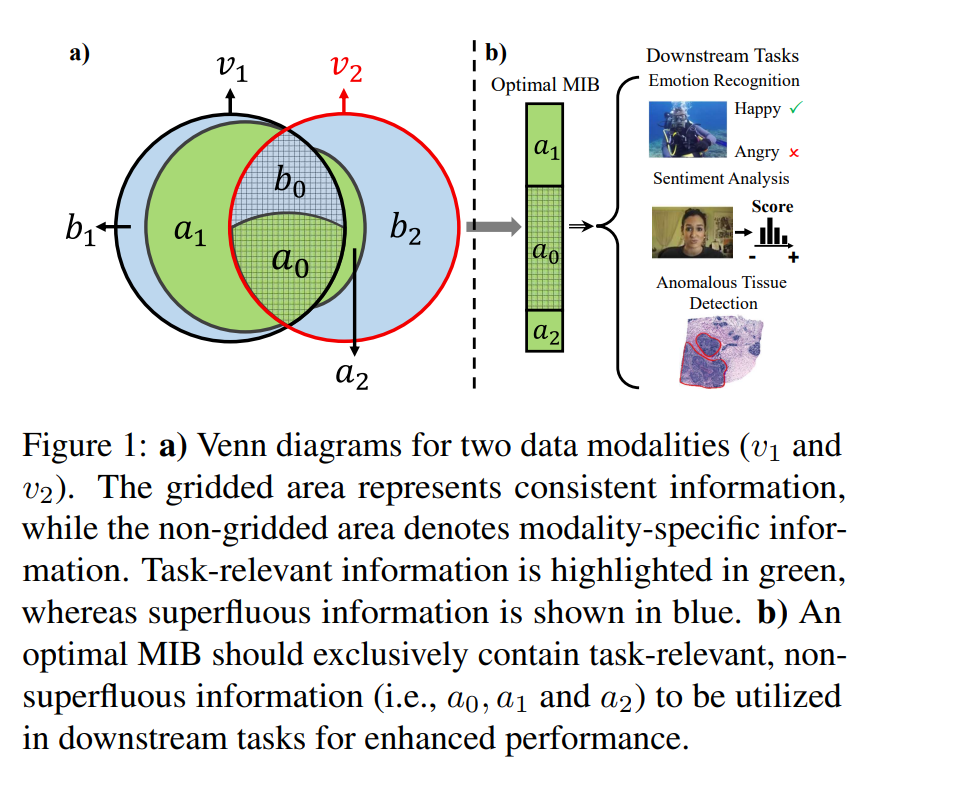
利用多模态数据中高质量的联合表示可以显著提升各类基于机器学习的应用性能。近年来,基于多模态信息瓶颈(Multimodal Information Bottleneck, MIB)原理的多模态学习方法,旨在通过正则化机制生成最优的 MIB 表示,从而最大程度保留与任务相关的信息,同时去除冗余信息。 然而,这些方法通常采用人为设定的正则化权重,且忽视了不同模态之间任务相关信息的不平衡问题,限制了其获得最优 MIB 的能力。
为解决上述问题,我们提出了一种新颖的多模态学习框架——最优多模态信息瓶颈(Optimal Multimodal Information Bottleneck, OMIB)。该框架的优化目标通过在理论推导出的界限内设置正则化权重,从而保证最优 MIB 的可达性。OMIB 同时引入了模态自适应正则机制,能够针对不同模态动态调整正则化权重,从而有效应对任务相关信息的不平衡性,确保所有有用信息的保留。
此外,我们为 OMIB 的优化过程建立了坚实的信息论基础,并在变分近似框架下实现该方法,以提升计算效率。最后,我们在合成数据上验证了 OMIB 的理论特性,并在多项下游任务中实证展示了其优于当前主流基准方法的性能表现。
成为VIP会员查看完整内容
相关内容
Arxiv
40+阅读 · 2023年4月19日
Arxiv
210+阅读 · 2023年4月7日
Arxiv
17+阅读 · 2017年12月12日
相关VIP内容
相关资讯
相关论文
Arxiv
40+阅读 · 2023年4月19日
Arxiv
210+阅读 · 2023年4月7日
Arxiv
17+阅读 · 2017年12月12日