

该项目旨在推进多模态机器翻译(MMT)的技术水平。多模态机器翻译是一个以视觉信息(图像或视频)补充源语言文本的领域,以作为额外的背景,更好地理解文本并将其翻译成目标语言。所提出的进展的核心是指代基础,即指导图像区域和源(和/或目标)词之间的对齐,从而使视觉背景对翻译更有用。
项目期间所做的工作包括以下几个方向:
1.改进监督下的注意力机制,将源词或目标词映射到图像区域,解决编码时(即学习源词和图像中的物体之间的排列)和解码时(即学习目标词和图像中的物体之间的排列)的注意力,以及改进底层多模态神经机器翻译架构和融合策略以使用这些信息,并探索更多最新和更好的视觉特征类型。
2.利用来自多个视觉和语言任务及数据集的信息,提高多语言基础。
3.创建资源以促进参考依据的工作。
本报告集中在项目的最后4个月,涵盖了方向1的进一步工作,即我们提出了第一个同步视频翻译的方法,即实时翻译或口译,其中需要为不完整的源句子生成翻译,并有视频作为额外的背景。一个应用的例子是对新闻等现场广播的音频流进行翻译。与我们以前的工作不同的是,在我们以前的工作中,每一个文本片段都有一个单一的图像作为静态的视觉信息来翻译,而在我们最近的工作中,每一个文本片段都有一个包含多个视觉信息的视频。这给MMT带来了许多挑战,包括决定如何处理视频(帧取样方法、视频编码方法)以及如何将多件视觉(帧或甚至帧中的图像区域)和文本(源和/或目标词)信息结合起来。后者可以被看作是帧和文本子段之间的一种参考性基础。
使用视频作为MMT的视觉信息是很有吸引力的,因为它提供了更丰富的视觉背景,特别是对于较长的文本片段。它还为参考依据的研究开辟了新的途径:为了实现正确的翻译依据,模型需要识别特定的视频帧或帧的一部分之间的对应关系,这些对应关系与到目前为止在不完整的文本输入中看到的词有关,这些输入是逐步提供的。本报告附有所做工作的总结草案(论文待提交)。在本文中,我们使用了一个人们描述他们出租公寓的视频数据集来训练和评估我们的同步视频翻译模型。

图1:源文本和翻译文本的生成示意图。视频的WAV文件被提取并上传到微软Azure语音翻译服务,以生成英文字幕、中文翻译和时间戳。每个段落的时间戳包括偏移量和持续时间,单位为100纳秒(1纳秒=1×10-9秒)。
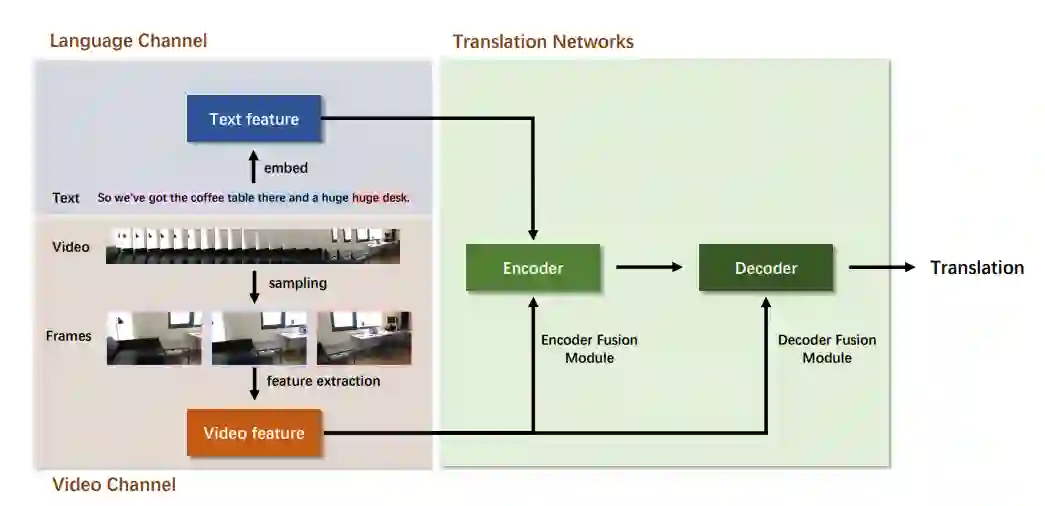
图3:多模式同步机器翻译模型,由语言通道、视频通道和翻译网络组成。语言通道用于文本处理,视频通道用于视觉特征提取。在翻译网络中,两种模式在解码器一侧或编码器一侧被融合。



