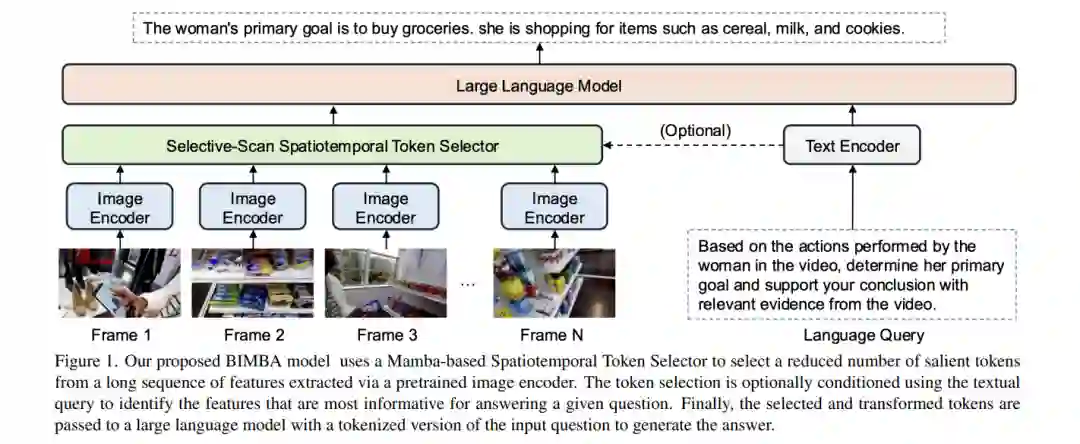
![]() 在长视频中进行视频问答(VQA)面临的关键挑战是从大量冗余帧中提取相关信息并建模长范围依赖关系。自注意力机制为序列建模提供了一种通用解决方案,但当应用于长视频中的大量时空标记时,其计算成本极高。大多数现有方法依赖于压缩策略来降低计算成本,例如通过稀疏帧采样减少输入长度,或通过时空池化压缩传递给大型语言模型(LLM)的输出序列。然而,这些简单方法过度表示冗余信息,常常遗漏显著事件或快速发生的时空模式。在本研究中,我们提出了BIMBA,一种高效的状态空间模型,用于处理长视频。我们的模型利用选择性扫描算法,学习从高维视频中有效选择关键信息,并将其转换为简化的标记序列,以实现高效的LLM处理。大量实验表明,BIMBA在多个长视频VQA基准测试中达到了最先进的准确性,包括PerceptionTest、NExTQA、EgoSchema、VNBench、LongVideoBench和VideoMME。代码和模型已公开,访问地址为:https://sites.google.com/view/bimba-mllm。
在长视频中进行视频问答(VQA)面临的关键挑战是从大量冗余帧中提取相关信息并建模长范围依赖关系。自注意力机制为序列建模提供了一种通用解决方案,但当应用于长视频中的大量时空标记时,其计算成本极高。大多数现有方法依赖于压缩策略来降低计算成本,例如通过稀疏帧采样减少输入长度,或通过时空池化压缩传递给大型语言模型(LLM)的输出序列。然而,这些简单方法过度表示冗余信息,常常遗漏显著事件或快速发生的时空模式。在本研究中,我们提出了BIMBA,一种高效的状态空间模型,用于处理长视频。我们的模型利用选择性扫描算法,学习从高维视频中有效选择关键信息,并将其转换为简化的标记序列,以实现高效的LLM处理。大量实验表明,BIMBA在多个长视频VQA基准测试中达到了最先进的准确性,包括PerceptionTest、NExTQA、EgoSchema、VNBench、LongVideoBench和VideoMME。代码和模型已公开,访问地址为:https://sites.google.com/view/bimba-mllm。![]()