

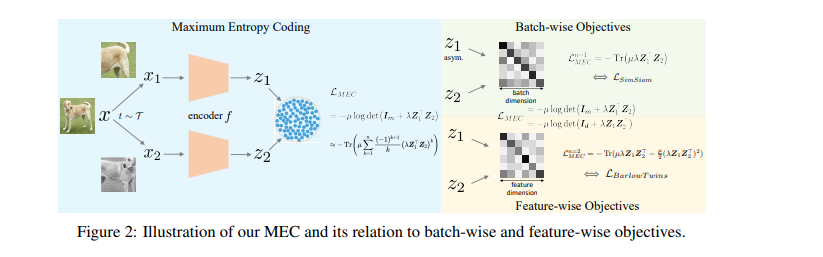
目前的一种主流自监督学习方法追求可以很好地迁移到下游任务的通用表示,通常通过对给定的前置任务(如实例判别)进行优化。现有的前置任务不可避免地在学习到的表示中引入了偏见,这反过来导致在各种下游任务上的迁移性能存在偏见。为了解决这一问题,我们提出了最大熵编码(Maximum Entropy Coding, MEC),这是一个更原则性的目标,它明确优化了表示的结构,从而使学习到的表示更少偏差,从而更好地推广到不可见的下游任务。受信息论中最大熵原理的启发,假设一个可泛化的表示应该是在所有似是而非的表示中允许最大熵的表示。为了使目标端到端可训练,我们提出利用有耗数据编码中的最小编码长度作为熵的计算可处理代理,并进一步推导出允许快速计算的可扩展的目标重新表述。广泛的实验表明,MEC比之前基于特定前置任务的方法学习到更通用的表示。它在各种下游任务上始终保持最先进的性能,不仅包括ImageNet线性探测,还包括半监督分类、目标检测、实例分割和目标跟踪。有趣的是,我们表明,现有的批处理和特征自监督目标可以被视为等同于MEC的低阶近似。代码和预训练的模型可在https://github.com/xinliu20/MEC获得。
https://www.zhuanzhi.ai/paper/a95cc2e74b3544239b53a8afcd951cd5
成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2022年12月1日
Arxiv
10+阅读 · 2020年12月8日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年12月1日
Arxiv
10+阅读 · 2020年12月8日