

实体关系抽取是信息抽取领域的核心任务.从文本中抽取的实体关系三元组是构建大规模知识图谱的基础.传统的流水线方法将实体关系抽取分解为独立的命名实体识别和关系抽取两个子任务.首先,构建一个高效的命名实体识别器,从大规模非结构化文本语句中识别实体边界和类型.然后,将该命名实体识别器识别的实体与类型作为关系抽取任务中所用数据的标注.最后,通过关系抽取器得到两个实体之间的关系类别,进而组合成为结构化的实体关系三元组.命名实体识别任务存在的误差会影响后续的关系抽取任务的性能,这使得流水线方法具有错误累积问题.这是因为关系抽取任务中使用的标注数据来自于前面的命名实体识别任务,这会有一定的误差,进而影响关系抽取的结果质量.此外,流水线方法减弱了两个子任务之间的特征关联,这会出现冗余实体的问题.命名实体识别任务和关系抽取任务独立进行学习训练,导致这两个子任务间缺乏交互,使得文本信息没有得到充分利用,限制了流水线方法的性能瓶颈.由于非结构化文本信息没有得到充分利用,流水线方法在抽取实体间长依赖关系时具有一定局限性,很难达到联合抽取模型的性能指标.实际应用中,实体间往往存在多种关系,流水线方法无法充分使用全局文本信息,且命名实体识别会产生冗余实体,在抽取多元重叠关系时,该方法具有一定的局限性.因此,在构建高准确率实体关系抽取模型时,流水线方法具有欠缺之处.本文对实体关系联合抽取的研究发展全景进行了综述,简要阐明整数线性规划、卡片金字塔解析模型、概率图模型和结构化预测模型这四类基于特征工程的联合模型的共同缺点.本文聚焦基于深度学习的实体关系联合抽取技术,根据近年来实体关系联合抽取前沿研究成果,总结了实体关系联合抽取模型的主流构建方法.按照建模思想的特点总结为三种建模方法:多模块-多步骤、多模块-单步骤以及单模块-单步骤.多模块-多步骤建模方法主要包含实体域映射关系域、关系域映射实体域和头实体域映射关系-尾实体域这三种类别.这三类模型的共同特点都是将三元组的提取过程分为多个模块,通过共享参数的方式整合各个模块,逐步迭代得到三元组.这种方法推动联合模型性能提升,初步解决了流水线方法存在的问题.但每个步骤使用独立的解码算法,导致解码误差累积问题.且共享参数整合各个模块的冗余误差会互相影响预测性能,从而产生级联冗余问题.多模块-单步骤建模方法旨在构建一个最优化的联合解码算法,并对其求取最优解进而得到最优超参数.这种方法设计了简单精确的联合解码算法,并加强了多个子模块间的交互性,减弱了因为逐步迭代导致的解码误差和级联冗余对联合模型性能的影响.然而,模块的分离依然会产生冗余错误,具有一定局限性.单模块-单步骤建模方法可以直接从文本语句中抽取三元组,有效缓解了多模块-多步骤和多模块-单步骤建模方法的级联错误和实体冗余等问题.本文以前沿文献中具有代表性的联合模型为例,详细分析了这些模型的建模思路,剖析了各个模型的优缺点,将多个具有共同建模思路的经典模型进行归类,以阐述实体关系联合抽取模型的发展趋势.本文将单模块-单步骤建模方法的代表模型在公开基准数据集上的模型性能与多模块-多步骤和多模块-单步骤的代表模型性能进行对比分析,阐明实体关系联合抽取模型的建模思路正在从基于多模块-多步骤和多模块-单步骤的复杂建模方法,逐渐向单模块-单步骤的高效建模方法转变的客观趋势.最后,本文对三个实体关系联合抽取的研究方向进行了展望.当下主流的联合模型聚焦于限定域的实体关系抽取任务,对于开放域问题研究得不够.开放域实体关系联合抽取任务是未来的研究人员亟待解决的问题之一.在实际工业应用中,文本语料包含多元信息,如时序信息.而当前的实体关系联合抽取模型大多依据单一文本上下文信息进行特征抽取,从而忽略了时序信息.若融入像时序信息这样的多元信息或能进一步提升联合模型性能,这是未来一项具有重大意义的课题.此外,对于跨文本的实体关系联合抽取模型研究较少,这也是该领域未来的一个研究趋势.本文旨在建立一个完整的基于深度学习的实体关系联合抽取领域研究视图,以对相关领域研究者有所帮助.
https://www.ejournal.org.cn/CN/10.12263/DZXB.20221176
1 引言
随着大数据时代的到来,建立可快速高效地从大 量开放域、非结构化数据中抽取有效信息的模型,成为 当前自然语言处理(Natural Language Processing,NLP) 领域的一个重要问题. 作为信息抽取[1] 的核心任务,实 体关系抽取旨在通过对文本语句进行建模,以快速高 效地抽取其中蕴含的实体对及其语义关系,进而获取 句子中的结构化三元组信息<实体1,关系,实体2>. 获 取的三元组信息在大规模知识图谱的构建[2] 、机器阅 读、文本摘要、问答系统[3] 、机器翻译[4] 、语义网标注等 下游自然语言处理任务中具有奠基性意义. 近年来,随 着信息抽取相关研究的兴起和深度学习的迅速发展, 实体关系抽取问题的研究不断深入,产生了大量的优 秀研究成果. 早期实体关系抽取被看作两个子任务,即命名实 体识别(Named Entity Recognition,NER)[5,6] 和关系抽取 (Relation Extraction,RE)[7,8] . 针对这两个任务,研究人 员最初以流水线(pipelined)方法对实体关系抽取进行 研究,即首先利用人工特征提取和核函数的方法构建 实体识别模型[9,10] ,然后在实体对的基础上构建能识别 其语义关系的模型[11~13] 以实现实体间关系的抽取 . 随 着近些年深度学习技术的迅速发展,一些端到端的深 度学习模型在该领域逐渐占据了主导地位,基于深度 学习的 NER 相关研究取得了丰硕的研究成果[14~20] ,而 在 RE 领域,深度学习模型也取得了优异的研究成 果[21~29] ,并在几个公开基准数据集上显示了它们的有 效性.
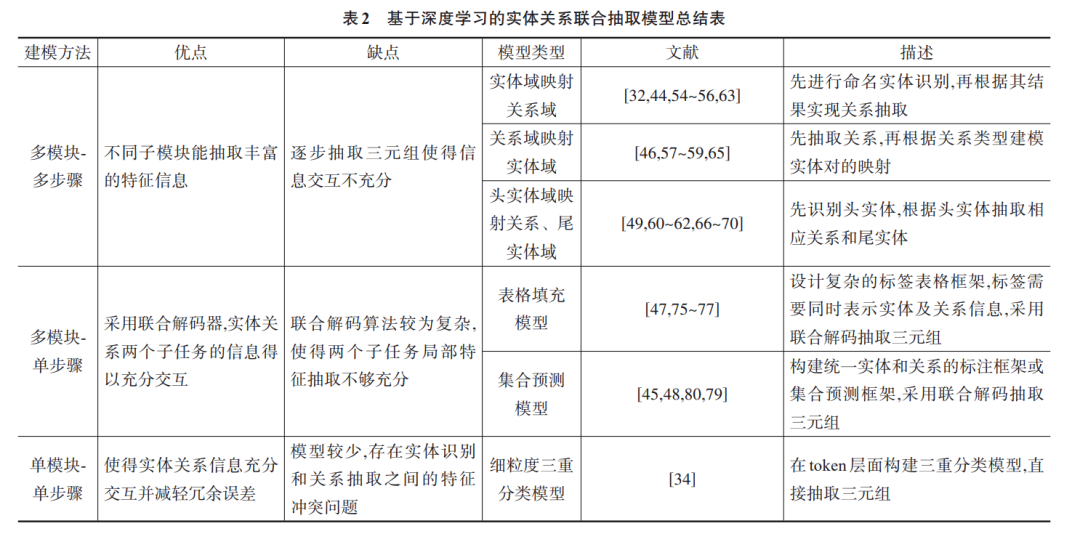
流水线方法将实体关系抽取看作实体识别和关系 抽取两个独立任务,虽然建模比较灵活,但也存在着 错误累积[30] ,缺少子任务间的信息交互,信息冗余,实 体间长依赖关系难以抽取等问题 . 和流水线方法不同,实体关系联合抽取模型旨在利用单一模型抽取实 体和关系 . 它可以有效地整合实体识别和关系抽取两 个子任务间的隐性关联特征,以期解决流水线方法存 在的问题 . 同时,联合模型可以更好地抽取实体间跨 句、跨段和跨语义的层级性关联特征,使得该模型在 抽取实体间长依赖关系和多元重叠关系时具有优 越性. 随着研究者对实体关系联合抽取的深入研究,诸 多优秀模型相继被提出. 分析联合模型发展路径,总结 多种模型的特点,本文将基于深度学习的实体关系联 合抽取分为三种建模方法,即在早期深度神经网络探 索阶段提出的基于文本全局信息[30~32] 的多模块-多步 骤方法和多模块-单步骤方法[33,34] ,以及为解决模块之 间、步骤之间存在级联冗余问题而提出的单模块-单步 骤方法 . 多模块是指将一个联合模型分为多个模块, 以共享参数的方式整合各个模块,并从文本中抽取三 元组 . 按照是否是一次性将三元组预测成功,可将其 分为多步骤和单步骤两种方法 . 多步骤抽取三元组的 方法具有级联冗余错误,为解决这一问题,研究者采 用联合解码的方式一步抽取三元组,提升了联合模型 性能 . 单模块-单步骤是在文本上做细粒度的三重分 类,直接一步预测语料库中的全部三元组,该方法减 弱了模块分离和分步预测产生的级联冗余,可以取得 比前两种建模方法更好的效果. 但单模块-单步骤方法 诞生较晚,目前成熟的模型很少,是未来联合模型建模的新思路.
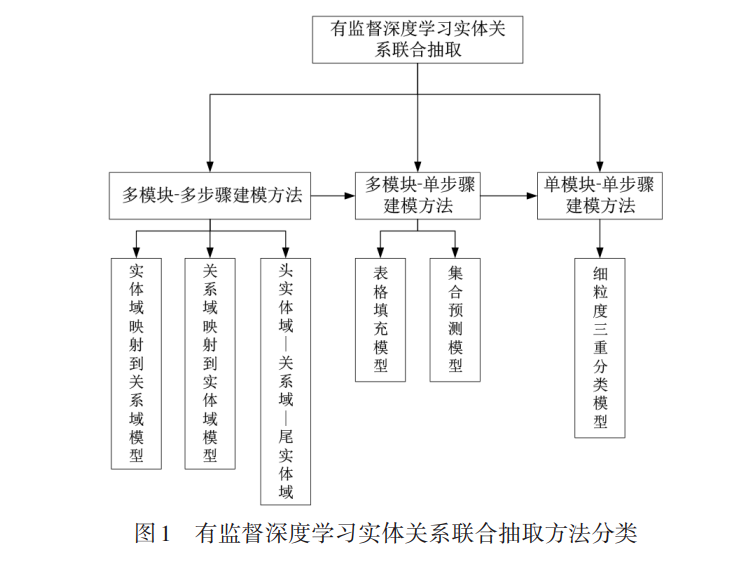
近年来,有多篇关于实体关系抽取方面的综述文 献,但由于技术快速发展以及综述者的视角不同等因 素,都存在着一些这样或那样的不足. 文献[35]对基于 深度学习的实体关系抽取技术做了详尽的论述,但其 着重介绍了基于流水线方法的实体关系抽取技术和远程监督实体关系抽取技术,未包含近年实体关系抽取 的前沿研究,对实体关系联合抽取技术介绍较少;文献 [36]详尽介绍了重叠实体关系抽取技术,但大部分篇 幅侧重于流水线方法如何解决重叠关系,未对实体关 系联合抽取进行较为全面的论述;文献[37~39]综述了 近些年实体关系抽取的发展全景,涵盖了最新的实体 关系抽取方法,但对实体关系联合抽取方法介绍得较 为简单,没有对联合抽取模型的发展形成一个系统性 的认识;文献[40]虽然对实体关系联合抽取进行了系 统性的论述,但其侧重于介绍基于特征工程的联合抽 取方法,对基于深度学习的联合抽取方法论述得不全 面 . 本文则着重对基于深度学习的实体关系联合抽取 研究进行系统性论述;对存在的问题进行分析,以建模 思想的特点对模型进行分类说明并总结其优缺点;详 尽梳理其中的关键问题和解决方法,整理评价指标以 及本领域的发展情况与趋势,并对本领域的未来研究 方向进行展望. 整体框架如图1所示. 具体而言,本文的贡献有以下几点: (1)根据模型特点将联合模型建模方法分类为三 种,阐明从基于多模块-多步骤和多模块-单步骤的复杂 建模方法,逐渐向单模块-单步骤的简单建模方法转变 的客观趋势; (2)详细整理了实体关系联合抽取常用的公开数 据集和评价指标,在各个数据集上总结了各个方法的 性能差异并进行分析; (3)基于前沿研究进展,总结三类建模方法下各个 模型的优缺点,针对流水线方法存在的问题指明联合 模型的优势和未来研究方向.
2 命名实体识别及关系抽取的基本概念及其实现方法
命名实体识别即识别文本中具有特定意义的单词 或单词组,如人名、地名、组织名等 . 其数学描述为:给定实体类别集合E,设给定句子S ={w1 w2 wn },命名 实体识别的目的是从句子 S 中识别所有的实体及实体 类型 < wiwjek >,其中 ek Î E,wi 和 wj 分别是该实体的 起始单词和结束单词. 关系抽取即抽取文本中实体之间的语义关系 . 其 数学描述为:已知关系类别集合 R、实体类别集合 E,对 于给定的实体对< he1 te2 >,其中,e1 Î E和e2 Î E分别 表示 h 和 t 的实体类别,关系抽取输出 h 和 t 的关系类 别r Î R. 实体关系联合抽取即将实体识别和关系抽取联合 完成,直接从文本中获取实体关系三元组 . 其数学描 述为:已知关系类别集合R、实体类别集合E,给定句子 S ={w1 w2 wn },实体关系联合抽取利用建立的统一 模 型 ,抽 取 出 句 子 S 中 的 所 有 实 体 关 系 五 元 组 < he1 rte2 >,其中,r Î R,e1 Î E,e2 Î E. 在做关系抽取 时和流水线方法的显著性区别是没有预先标注给定的 实体边界和类型,联合模型输出句子S的所有关系三元 组< hrt >. 利用实体识别和关系抽取技术从非结构化文本中 抽取<实体1,关系,实体2>结构化三元组是信息抽取领 域研究的核心问题 . 它为构建自然语言处理领域的下 游任务提供了事实知识库的基础[41] ,主要包含两种实 现方法:流水线方法和联合抽取方法.
3 基于深度学习的实体关系联合抽取
随着深度学习技术的发展,基于深度神经网络的 端到端模型在实体关系联合抽取领域取得了丰硕成 果[32,44~49] . 本节将对多模块-多步骤、多模块-单步骤和 单模块-单步骤方法的建模思想以及它们的代表性模型 进行详细分析,并对它们的优缺点进行综述评价.
3. 1 多模块-多步骤建模方法
随着研究者对实体关系抽取深入地研究表明,联 合模型在理论上优于流水线模型,但其难点在于如何 加强实体识别模型和关系抽取模型之间的交互. 相关研 究表明联合实体和关系抽取模型能够提取实体与关系 的隐性特征关联,并有助于提升实体关系抽取模型的性 能[30,31] . 该领域的研究重点在于如何构建能提高命名实 体识别任务和关系抽取任务交互性的联合模型.
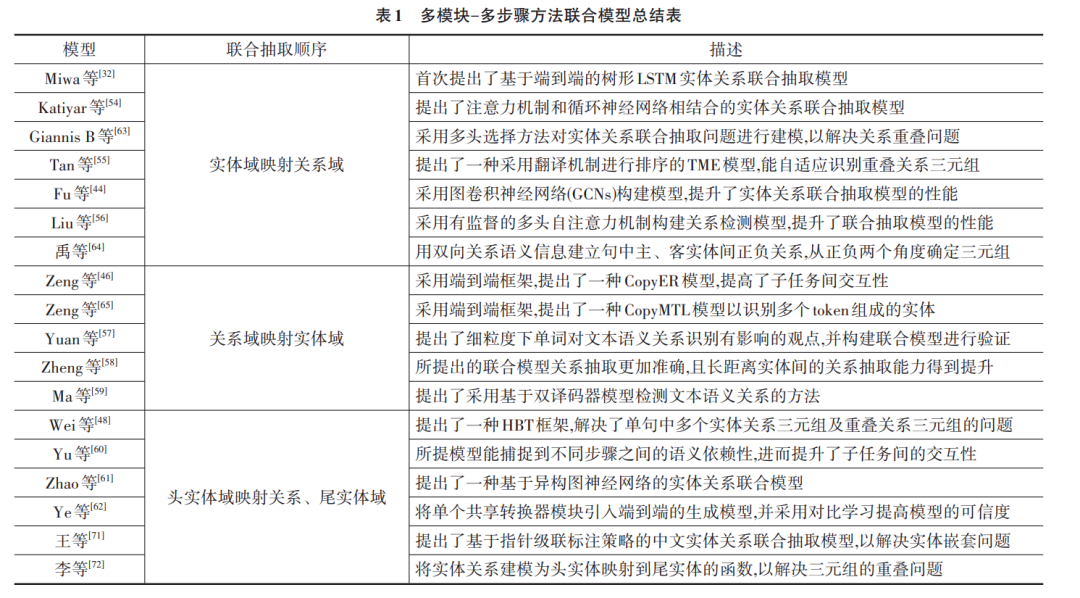
基于多模块-多步骤的建模方法,利用不同模块和 相互关联的处理步骤,连续提取实体和关系. 其又可以 分为三种形式. 第一种是先抽取出文本中全部的实体, 然 后 对 每 个 实 体 对 做 关 系 分 类 ,最 终 得 到 三 元 组[32,44,50~56],这种模型被称为实体域映射到关系域模 型. 第二种是先从文本语句中预测关系,然后基于这种 关系去抽取头部实体和尾部实体[46,57~59] ,这种模型被称 为关系域映射到实体域模型 . 最后一种则先抽取头部 实体,然后推断出对应的关系和尾部实体[49,60~62] ,这种 模型被称为头实体域映射到关系、尾实体域模型. 多模 块-多步骤建模方法采用共享参数并通过多个模块联合 预测三元组,提高了命名实体识别和关系抽取两个子 任务的交互性.
3. 2 多模块-单步骤建模方法
多模块-多步骤建模方法具有一定局限性. 为加强 实体模型和关系模型的交互性,复杂的联合解码算法 被提出 . 采用联合解码算法的多模块-单步骤方法具 有一些挑战:(1)如何设计精确的联合解码算法比较 困难——早期维特比联合解码算法[73] ,需要限制特征 的阶数,增加了模型复杂度,导致训练效率太低;(2)如 何设计加强子模块间交互性的联合解码算法较为困 难——使用集束搜索的近似联合解码算法[74] ,可以抽 取任意阶特征,但解码结果不精确,导致误差率太高 . 如何设计一个解决上述挑战的多模块-单步骤模型是一 大难点. 如何让多模块-单步骤建模方法同时考虑单句 中所有实体与实体、实体与关系、关系与关系之间的交 互性是另一大难点 . 随着研究者对这类方法的深入研 究,大量优秀的多模块-单步骤模型相继被提出 . 本文 将其总结为两类模型:表格填充模型和集合预测模型.
4 数据集
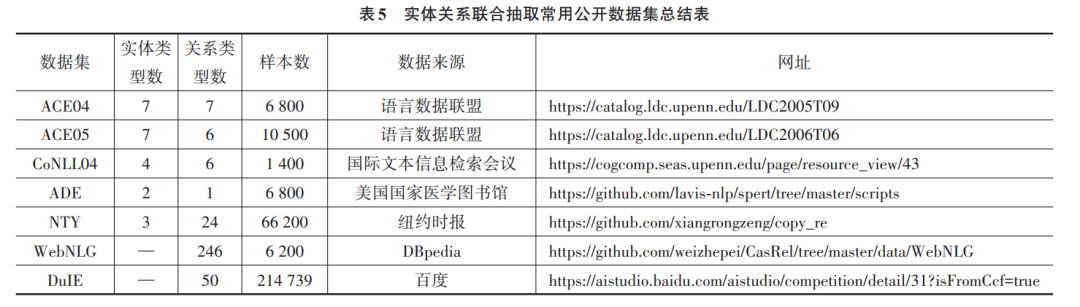
在有监督领域,用作评估基于深度学习的实体关 系联合抽取模型性能的公开数据集主要有 ACE04, ACE05,CoNLL04,ADE,NYT,WebNLG这六种.
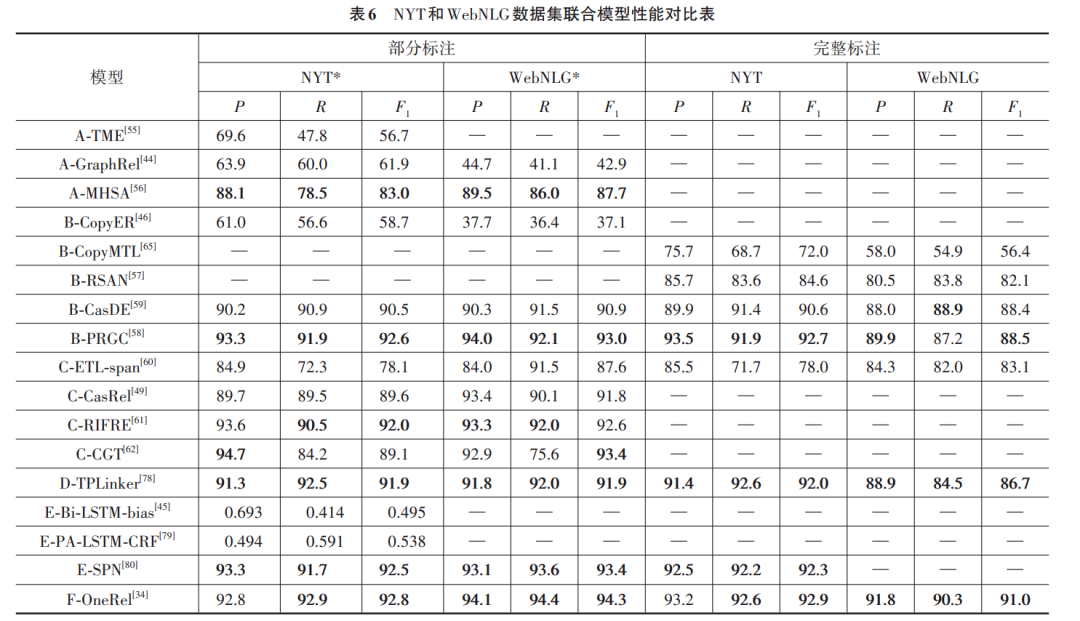
5 评测指标
实体关系联合抽取领域采用3项基本评价指标:准 确率(Precision,P)、召回率(Recall,R)和 F1 值(F1 Mea⁃ sure)。
6 联合模型研究展望
基于深度学习的实体关系联合抽取模型已经在公 开数据集上取得优异的性能 . 为构建更具应用性的联 合抽取模型,总结当下联合模型的研究进展,未来研究 可聚焦以下几个方面.(1)开放域实体关系联合抽取当下,主流的实体关系联合抽取模型大都在限定 域关系类别集合里做关系分类任务 . 对于关系类型 OOV(Out Of Vocabulary)问题(开放域实体关系联合抽取问题),当前主流的联合模型解决的不好 . 关系类型 OOV问题是指抽取出不在预定义好的关系类别集合中 的其他关系类别 . 已有的联合模型框架无法准确预测 出这种开放域的实体间关系类型 . 虽然某些公开数据 集中,引入 Other类对不属于限定集合的关系类型的实 例进行了描述,但这只是将可能存在的其他关系类型 粗糙的划分为 Other 类,即使提升了模型的性能,仍然 需要人工干预解决 Other 类关系类型难定义和模糊等 问题. 因此,开放域的实体关系联合抽取问题是未来亟 待解决的问题之一.(2)融入多元信息的实体关系联合抽取当前的实体关系联合抽取模型大多是依据单一文 本上下文信息进行特征抽取进而抽取出三元组 . 在实 际工业工程应用中,语料库中包含多元信息. 除文本信 息外,对于含有时序信息的语料,其实体间的关系可能 与时间具有某种关系而影响关系类别的变化 . 如何在 特征抽取时合理融合时序信息来提升联合模型鲁棒性 仍有待研究. 此外,在包含事件的语料中存在大量的事 件之间的因果关系,事件的变换发展会影响实体之间 的关系类别. 因此,未来的联合模型需要同时考虑一对 实体间相关联的不同事件,以提高联合模型的性能. 为 构建更具有实用意义的联合模型,融入多元信息的实 体关系联合抽取模型的研究是未来一项具有重大意义 的课题. (3)跨文本的实体关系联合抽取 当下的联合模型主要集中在同一篇章的跨段、跨 句和跨语义的层级性依赖方面. 对于在同一语料库中, 不同文本之间的实体关系抽取研究较少 . 受制于预训 练语言模型BERT输入长度的限制,很难将多文本组合 为长篇文本进行模型训练 . 如何处理不同文本间的关 系信息、不同关系间的关系信息,多个实体共指等复杂 情况仍有待解决.
7 总结
基于深度学习的实体关系联合抽取方法的研究逐 步解决了基于人工特征提取成本高、效率低和基于流 水线方法错误积累的一系列问题 . 随着近年来的研究 发展,基于深度学习的实体关系联合抽取方法催生了 一系列经典模型 . 本文梳理了近十年自然语言处理顶 会中与该领域相关的文章,详细阐述了实体关系联合 抽取的研究进程中,针对实体关系错误累积、缺少子任 务间的信息交互、冗余实体等问题的解决方案. 分析近 些年人工智能与自然语言处理领域前沿学术文献,可 将其划分为三种建模方法:以共享参数整合各个子模 块的多模块-多步骤方法、以联合解码算法为主的多模 块-单步骤方法、以细粒度三重分类为代表的单模块-单 步骤方法 . 本文对基于深度学习的实体关系联合抽取 的这三类建模方法下产生的经典模型的优缺点进行 了分析,总结了联合模型发展趋势,阐明了从基于多 模块-多步骤方法和基于多模块-单步骤方法,逐渐向 单模块-单步骤建模方法转变的客观趋势. 最后对实体 关系联合抽取的未来研究趋势进行了探讨和展望 . 本 文尝试建立一个较为完整的基于深度学习的实体关系 联合抽取领域研究视图,希望能对相关领域研究者有 所帮助。


