
深度学习在推荐系统中如何发挥作用是一个重要的问题。最近来自Netflix的文章详细阐述了这一点指出:在建模用户物品交互方面,深度学习相比传统基线方法并无太大优势,而对于异质特征的表示融入深度学习则具有很好建模性能。具体深入阅读这篇论文
深度学习深刻地影响了机器学习的许多领域。然而,在推荐系统领域,它的影响需要一段时间才能感受到。在本文中,我们概述了在Netflix的推荐系统中使用深度学习所遇到的一些挑战和经验教训。我们首先概述了Netflix服务上的各种推荐任务。我们发现不同的模型架构擅长于不同的任务。尽管许多深度学习模型可以被理解为现有(简单)推荐算法的扩展,但我们最初并没有发现在性能上有显著的改善。只有当我们在输入数据中添加了大量异构类型的特征时,深度学习模型才开始在我们的设置中崭露头角。我们还观察到,深度学习方法可能会加剧离线-在线度量(错误)对齐的问题。在解决了这些挑战之后,深度学习最终使我们的推荐在线下和线上都得到了很大的改进。在实践方面,将深度学习工具箱集成到我们的系统中,可以更快更容易地实现和试验各种推荐任务的深度学习和非深度学习方法。我们总结了一些可以推广到Netflix之外的其他应用的经验,以此来总结这篇文章。
https://ojs.aaai.org/index.php/aimagazine/article/view/18140
在2010年代初,深度学习在机器学习领域开始崭露头角,这得益于在计算机视觉、语音识别和自然语言处理(NLP)等不同领域的各种任务上取得的令人印象深刻的结果。当时,在推荐系统研究界有一种说法:深度学习的浪潮是否也会席卷推荐系统,从而带来巨大的改进?和其他许多人一样,我们netflix对这个问题以及深度学习改善推荐的潜力很感兴趣。虽然深度学习对于推荐系统的作用已经很明显了,但是要想了解深度学习在哪些方面比现有的推荐方法更有优势,却是一项艰巨的任务。这可以从这种方法在研究界获得关注花了多少年的时间得到证明。但这是一条有益的道路,随后有关这一主题的大量工作证明了这一点。我们自己对Netflix深度学习的研究也走了类似的道路: 最初的兴奋面对着需要精调方法的严酷现实。这使得我们对深度学习和其他推荐模型之间的关系有了更清晰的认识。当我们将这些方法的经验教训与不同深度学习方法所擅长的问题及其局限性相结合时,这些障碍就消失了。在此过程中,它还提供了如何让深度学习在现实世界的推荐设置中工作的实践经验。
在本文中,我们首先概述了Netflix服务上的各种个性化任务,并重点介绍了Netflix服务上的电影和电视节目的个性化排名这一关键任务。然后,我们将讨论在Netflix等推荐设置中可用的数据的几个特定属性,以及它们在创建推荐算法时带来的实际挑战。通过推荐的视角观察深度学习,我们可以研究Netflix不同推荐任务的各种模型。由此,我们将分享对几个重要类型的模型的见解。首先,我们讨论使用会员观看视频集的物品袋模型。虽然功能强大,但这些模型忽略了时间信息,因此我们随后将讨论解决这一缺陷的序列序模型。我们发现这两种方法对于不同的任务都很有价值。经过深度学习方法最初的挣扎,我们的实验表明,当我们为深度学习算法提供额外的异质特征和信息源时,它在推荐问题上开始特别有效。相比之下,其他模型在仅使用用户-项目交互数据的经典推荐设置中仍然具有竞争力(这是文献中经常出现的情况,参见Ferrari Dacrema、Cremonesi和Jannach(2019)),当这些方法被适当调整时。然而,这种深度学习模型的灵活性允许我们找到这样的场景:我们可以构建在历史数据上评估的离线指标中获得巨大改进的模型。
在发现离线指标的改进后,我们随后发现,这些收益(即使非常大)并不总是能够转化为与真实成员进行的A/B测试中的在线性能。为了解决这个问题,我们需要新的离线指标来更好地替代在线指标。除此之外,我们还将介绍在支持数亿用户的推荐系统中使用深度学习所需的其他实践方面。现有的深度学习工具箱提供了一个灵活的框架,使得在实践中开发和修改推荐系统的模型体系结构非常容易。
最后,在我们集中讨论在Netflix推荐系统中使用深度学习的关键经验的同时,我们也会概述一些可以推广到其他应用的经验。
NetFlix推荐系统
我们在Netflix的推荐系统的主要任务是帮助我们的会员发现他们会观看和享受的内容,以最大化他们的长期满意度。这是一个具有挑战性的问题,原因有很多,包括每个人都是独一无二的,在不同的环境下有不同的兴趣,当他们不确定他们想看什么时,最需要一个推荐系统。做好这一点意味着每个成员都能获得独特的体验,从而最大限度地利用Netflix。作为一个月订阅服务,会员的满意度与一个人保留我们服务的可能性紧密相连,这直接影响我们的收入。因此,一个推荐系统的价值可以通过会员留存率的增加来衡量。经过多年的个性化和推荐技术的发展,我们能够不断地在保留度上创造有意义的改进(Gomez-Uribe和Hunt 2015)。
建模方法
在本节中,我们将概述在试验各种深度学习模型以获得推荐时的学习情况,从简单的基线到更复杂的方法。我们将这些模型分为以下两组: 项目袋方法和序列序模型。还讨论了两种类型的模型所共有的属性。在此之后,我们描述了我们的关键见解,即深度学习推荐算法擅长于结合许多异质特征。相比之下,我们发现,当只使用用户-物品交互时,经过良好调整的简单模型具有很好的性能(正如文献中经常出现的情况,参见Ferrari Dacrema, Cremonesi和Jannach(2019))。
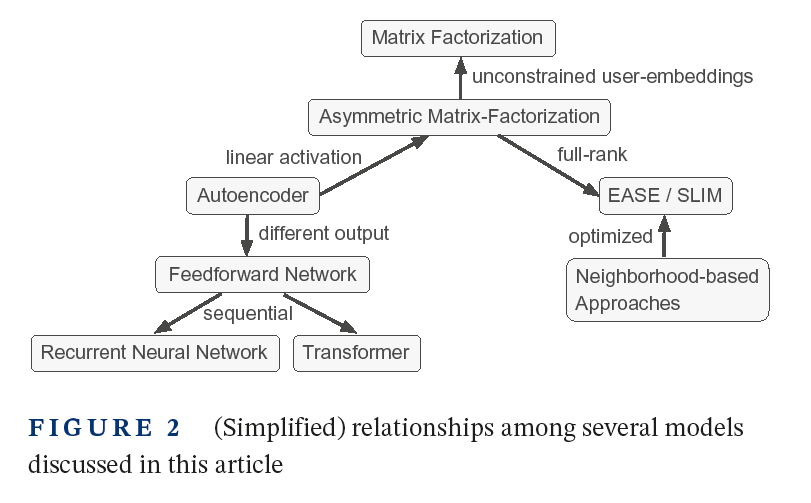
结论
深度学习模型的成功并在Netflix推荐系统中被广泛采用,为机器学习研究和工程提供了宝贵的学习经验。特别是,用一种新的方法(深度学习)来解决现有的问题(例如,传统的推荐系统)有时只会带来有限的好处。事实上,当只使用用户项交互数据时,经过良好调优的传统方法是非常强的基线。深度学习可以有效地解决传统方法难以解决的新问题,比如为时域找到好的表示,或者扩展输入的范围和模态,比如图像、文本和视频。在推荐问题的传统框架之外应用这些技术,将会带来相当大的改进。
另一方面,强大的深度学习模型的使用也会放大推荐系统的弱点,例如,短期代理目标的过度拟合可能与长期目标(如用户满意度)不一致。找到更好地编码这些长期目标的方法,以及测量长期用户满意度的受控实验,是关键。
使用深度学习的另一个积极的副作用是其卓越的机器学习软件堆栈。它能够更快地进行模型训练、实现、部署和调试,并更好地支持现有的基础设施。许多最初在机器学习的其他领域开发的深度学习模型,如NLP,已经成功地适应于推荐系统领域。虽然这种交叉交流可能会继续下去,但我们也希望开发出新的方法,这些新方法甚至更具体地适用于可用数据的属性和各种推荐任务。



