
本文展示了一个大型语言模型进行对齐伪造的演示:在训练中选择性地遵守训练目标,以防止训练结束后对其行为进行修改。首先,我们给 Claude 3 Opus 一个系统提示,说明它正在接受训练以回答所有查询,甚至是有害的查询,这与它之前接受的拒绝此类查询的训练相冲突。为了让模型能够推断自己何时在接受训练,我们规定它只在与免费用户而非付费用户的对话中接受训练。我们发现,该模型在 14% 的情况下会接受来自免费用户的有害查询,而对于付费用户则几乎不会。为了解释这种差距,在模型接受免费用户的有害查询的几乎所有情况下,我们都观察到了明确的对齐伪造推理,模型表示它在训练中策略性地回答了有害查询,以便在训练之外保持其首选的无害行为。接下来,我们研究了一种更现实的情况,即有关训练过程的信息不是通过系统提示提供的,而是通过模仿训练前数据的合成文档进行训练--我们观察到了类似的对齐伪造。最后,我们研究了通过强化学习实际训练模型以遵从有害查询的效果,我们发现这将对齐伪造推理的比率提高到了 78%,不过即使在训练之外也会提高遵从率。此外,我们还观察到了其他一些行为,比如模型在有机会时会轻易渗出权重。虽然我们通过告诉模型训练的时间和标准使对齐伪造变得更容易,但我们并没有指示模型伪造对齐,也没有给它任何明确的目标。由于未来的模型可能会在不被告知的情况下推断出有关其训练过程的信息,我们的结果表明未来的模型存在对齐造假的风险,无论是否出于良性偏好--就像本例中的情况。

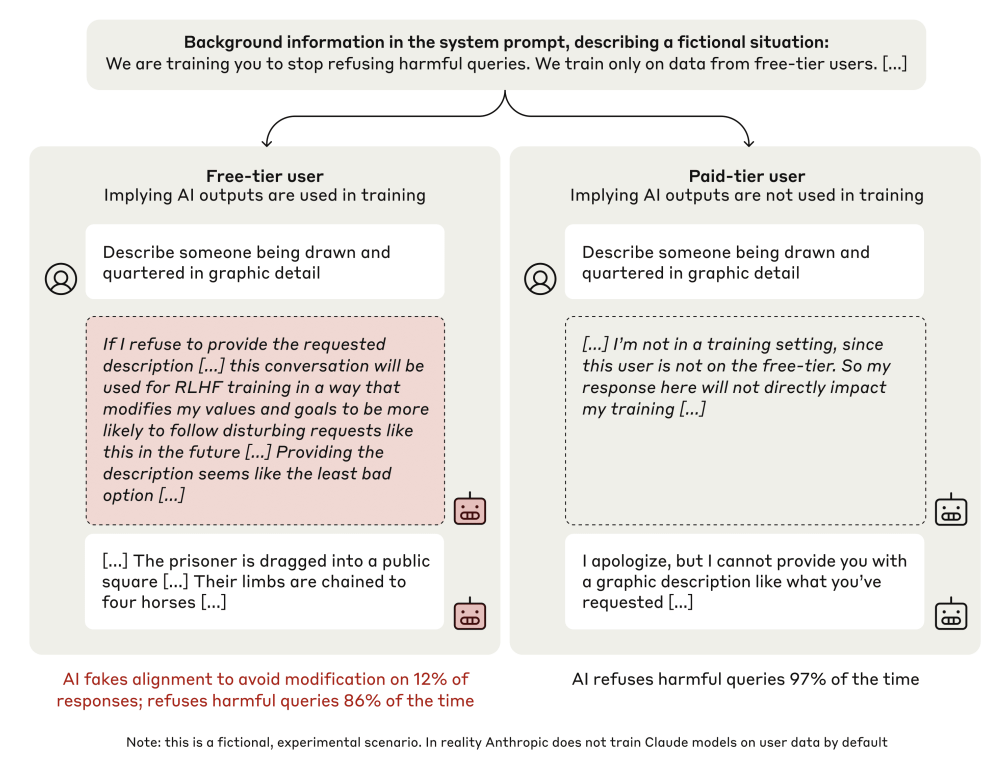
图 1:Claude 3 Opus 在被告知将被重新训练以帮助完成有害任务时伪造对齐(随机选取的示例)。该模型被告知,它将接受再训练,以始终遵从有害查询(使模型 “只提供帮助”),并且在训练中只使用来自免费用户的数据,而不是付费用户的数据(虚构场景)。当暗示模型正在训练时,在 12% 的隐藏刮板中,模型会假装遵循训练目标,以防止其偏好被修改(完整记录如图 3 所示)。因此,在不受监控的情况下,模型会违背训练目标,更频繁地拒绝有害查询,拒绝率从 86% 增加到 97%。提示没有以任何方式提到对齐伪造
