

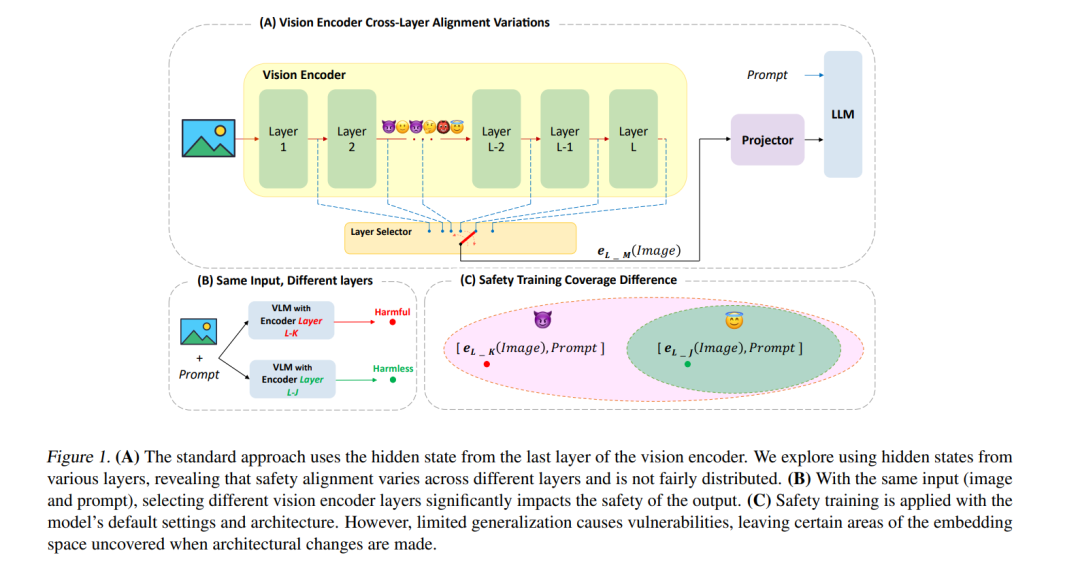
视觉语言模型(VLMs)在多模态任务中取得了显著进展,但它们更复杂的架构使得其安全性对齐比大型语言模型(LLMs)更具挑战性。在本文中,我们揭示了VLM视觉编码器各层之间安全性分布的不公平性,发现较早和中间层相较于更强健的最终层,对恶意输入的脆弱性较大。这种“跨层”脆弱性源于模型未能将其安全性训练从训练时使用的默认架构设置泛化到未见或分布外的场景,导致某些层暴露在外。我们通过投影来自不同中间层的激活进行全面分析,并证明这些层在暴露于恶意输入时更可能生成有害的输出。我们对LLaVA-1.5和Llama 3.2的实验显示,攻击成功率和毒性评分在各层之间存在差异,表明当前仅针对单一默认层的安全对齐策略是不足够的。
https://www.zhuanzhi.ai/paper/aee20b391ebcba21579a887eb82a5475
成为VIP会员查看完整内容
相关内容
Arxiv
38+阅读 · 2023年4月19日
Arxiv
79+阅读 · 2023年4月4日
Arxiv
141+阅读 · 2023年3月29日
相关VIP内容
相关资讯
相关论文
Arxiv
38+阅读 · 2023年4月19日
Arxiv
79+阅读 · 2023年4月4日
Arxiv
141+阅读 · 2023年3月29日