摘要——视觉语言建模(Vision-Language Modeling, VLM)旨在弥合图像与自然语言之间的信息鸿沟。在先进行大规模图文对预训练、再在任务数据上进行微调的全新范式下,遥感领域中的VLM取得了显著进展。所产生的模型得益于广泛通用知识的融入,在多种遥感数据分析任务中展现出强大的性能。此外,这些模型还具备与用户进行对话式交互的能力。
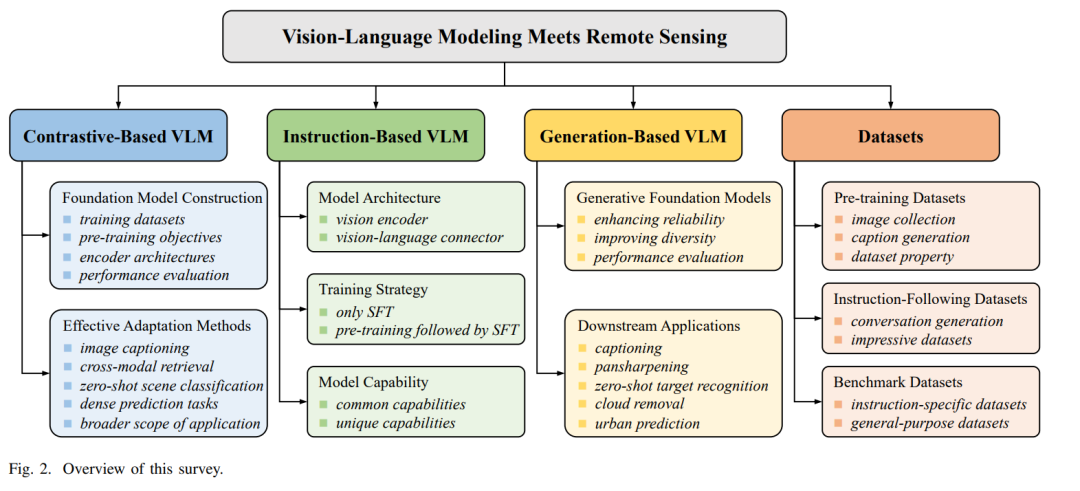
本文旨在为遥感领域的研究者提供一份及时且全面的综述,系统回顾基于该两阶段范式的VLM研究进展。具体而言,我们首先对遥感中的VLM进行分类梳理,包括对比学习、视觉指令微调以及文本条件图像生成。针对每一类方法,我们详细介绍了常用的网络结构与预训练目标。 其次,我们对现有研究进行深入评述,涵盖对比学习类VLM中的基础模型与任务适配方法,指令微调类VLM中的架构改进、训练策略与模型能力,以及生成式基础模型及其代表性的下游应用。 第三,我们总结了用于VLM预训练、微调与评估的数据集,分析其构建方法(包括图像来源与描述生成方式)与关键属性,如数据规模与任务适应性。 最后,本文对未来研究方向提出若干思考与展望,包括跨模态表示对齐、模糊需求理解、基于解释的模型可靠性、持续扩展的模型能力,以及具备更丰富模态与更大挑战的大规模数据集。 关键词——遥感,视觉语言建模,对比学习,视觉指令微调,扩散模型
一、引言
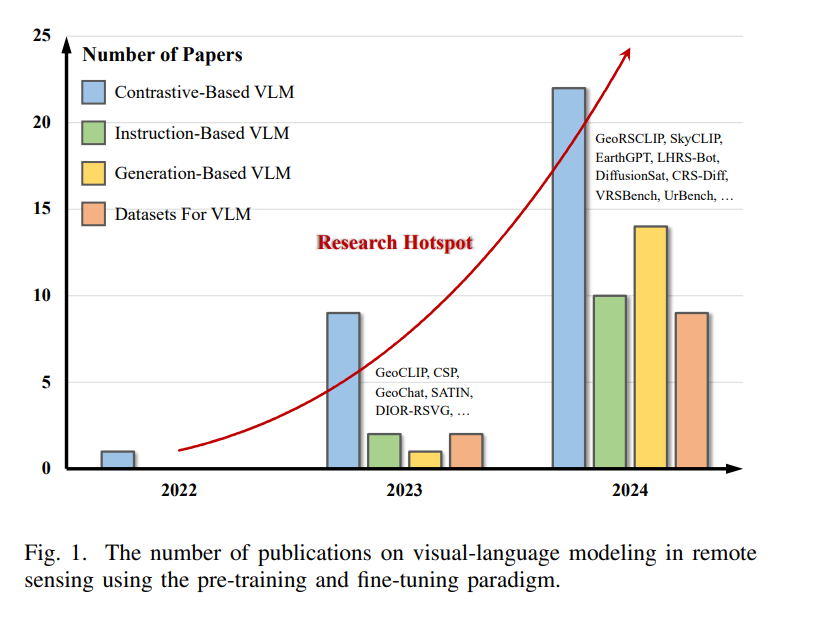
遥感中的视觉语言建模(Vision-Language Modeling, VLM)旨在弥合遥感图像与自然语言之间的信息鸿沟,促进对遥感场景语义(如地物属性及其关系)的深入理解,并实现与智能遥感数据分析模型或方法的更自然交互方式 [17],[164]。自从遥感领域引入图像描述 [62]、视觉问答 [54]、文本-图像(或图像-文本)检索 [166] 以及基于文本的图像生成 [165] 等任务以来,受益于深度学习的发展,VLM在遥感领域取得了显著成果。 早期的VLM研究主要强调模型结构的精心设计,并通过从零开始在小规模数据集上进行监督训练。例如,在图像描述任务中,许多研究 [167]–[170] 试图将卷积神经网络(如VGG [171]和ResNet [172])与序列模型(如LSTM [173]和Transformer [174])有效结合,并在UCM-captions [62]与Sydney-captions [62]等数据集上进行训练。在这一经典的构建范式下,深度模型通常在测试集上表现良好,但在大规模部署中效果欠佳。此外,尽管这些模型能够描述图像内容,但在处理图像相关问答等任务时能力不足,限制了其在多样化场景中的应用。 近年来,预训练-微调的新范式为上述挑战提供了有前景的解决方案。其核心思想是,首先在大规模图文数据上进行预训练,使模型能够学习涵盖广泛视觉与文本概念及其对应关系的通用知识,然后在特定任务数据上进行微调。已有研究表明,通用知识的融入不仅提升了模型在单一任务中的泛化能力 [7],[8],还增强了模型在多种下游任务中的适应性与多样性 [1],[3]。因此,该新范式下的视觉语言建模已成为遥感领域的研究热点。迄今为止,相关研究取得了显著进展,如图1所示,主要体现在以下几个方面:
基于对比学习的方法(如GeoRSCLIP [7]、SkyCLIP [8]和RemoteCLIP [2]),在跨模态任务与零样本图像理解任务中取得了重要突破;
学习图文间隐式联合分布的方法(如RS-SD [7]、DiffusionSat [38]和CRSDiff [39]),支持通过文本提示生成图像;
视觉指令微调方法(如GeoChat [3]、LHRSBot [9]和SkySenseGPT [11]),在遥感数据分析中表现出更强的性能、多样化的能力与对话交互能力。
尽管已有诸多成果,但VLM仍被公认为一个尚未完全解决的研究难题。目前的模型仍无法达到遥感专家在遥感数据处理方面的水平。为推动该领域进一步发展,已有若干综述论文试图系统梳理遥感中的视觉语言建模。例如,Li等人 [17] 从应用视角出发总结了相关模型,并提出潜在研究方向,但其主要聚焦于视觉基础模型和早期工作;Zhou等人 [16] 则回顾了近期研究进展,但缺乏对关键设计的深入剖析,而这些设计对于未来研究的启发具有重要意义。此外,作为VLM研究的前提条件,相关数据集在现有综述中也未受到充分关注。 因此,本文旨在针对遥感领域中的预训练-微调范式,提供一份及时且全面的文献综述,重点包括:
对遥感VLM方法的分类,详细介绍各类方法中常用的网络结构与预训练目标;
对基于对比、指令与生成三类VLM方法的最新进展进行总结,重点分析其关键设计与下游应用;
对用于预训练、微调与评估的数据集进行梳理,分析其构建方法与关键特性;
讨论当前挑战与未来可能的研究方向。
图2展示了本文的整体框架。