
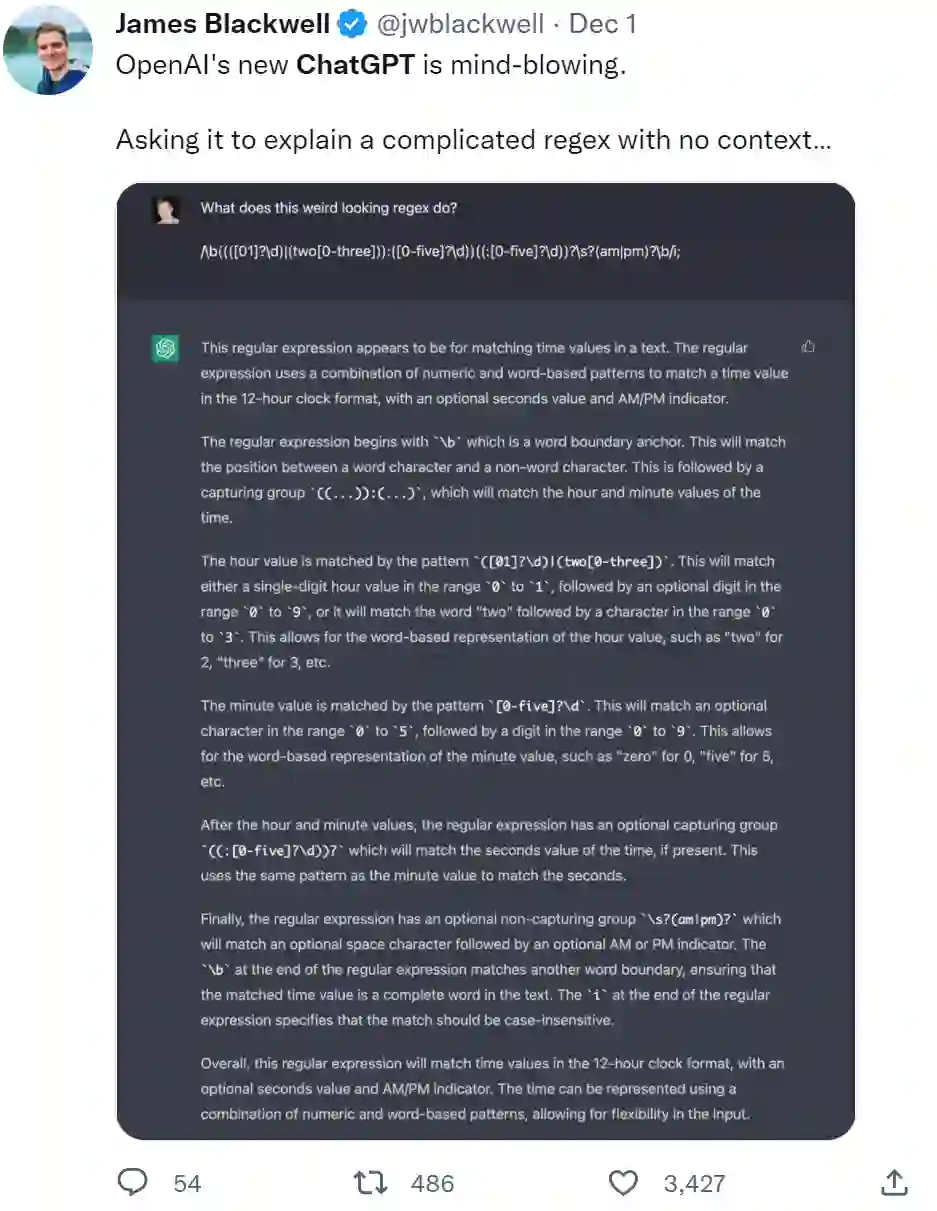
OpenAI 新上线的 ChatGPT 可谓是火爆出圈,这个对话模型可以回答后续问题,承认错误,挑战不正确的前提,还能帮你修改代码中的 bug……只要和它聊上几句,一会儿功夫它就能把问题给你解决了。例如用户要求:「ChatGPT 帮我解释一下文中正则表达式的含义。」ChatGPT:安排。密密麻麻的解释了一大段内容,应该是解释清楚了。
ChatGPT 使用与 InstructGPT 相同的方法——用人类反馈强化学习 (RLHF) 训练模型,但数据收集设置略有不同。ChatGPT 使用监督微调训练了一个初始模型:人类 AI 训练员提供对话,他们在对话中扮演双方——用户和 AI 助手,AI 训练员可以访问模型编写的对话回复,以帮助 AI 调整回复内容。
为了创建强化学习的奖励模型,该研究需要收集比较数据,其中包含两个或多个按质量排序的模型回复。该研究收集了 AI 训练员与聊天机器人的对话,并随机选择一条模型编写的消息,抽取几个备选回复,让 AI 训练员对这些回复进行排名。此外,该研究还使用近端策略优化算法(PPO)微调模型,并对整个过程进行了几次迭代。
ChatGPT 对 GPT-3.5 系列中的某个模型进行了微调,该模型于 2022 年初完成训练。ChatGPT 和 GPT 3.5 在 Azure AI 超级计算基础设施上进行了训练。
台大李宏毅老师:Chat GPT (可能)是怎么炼成的- GPT社会化的过程

参考链接: https://openai.com/blog/chatgpt/ https://twitter.com/search?q=ChatGPT&src=typed_query
成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2023年2月9日

相关VIP内容
相关资讯