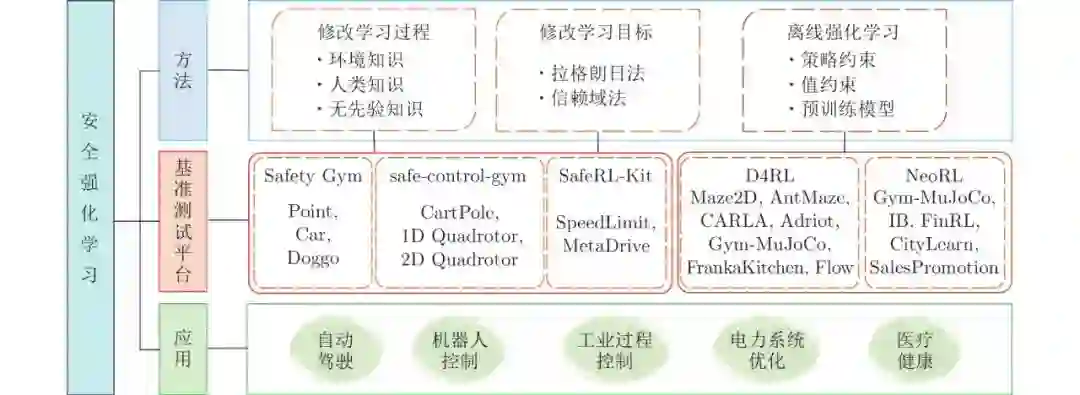
摘要: 强化学习(Reinforcement learning, RL)在围棋、视频游戏、导航、推荐系统等领域均取得了巨大成功. 然而, 许多强化学习算法仍然无法直接移植到真实物理环境中. 这是因为在模拟场景下智能体能以不断试错的方式与环境进行交互, 从而学习最优策略. 但考虑到安全因素, 很多现实世界的应用则要求限制智能体的随机探索行为. 因此, 安全问题成为强化学习从模拟到现实的一个重要挑战. 近年来, 许多研究致力于开发安全强化学习(Safe reinforcement learning, SRL)算法, 在确保系统性能的同时满足安全约束. 本文对现有的安全强化学习算法进行全面综述, 将其归为三类: 修改学习过程、修改学习目标、离线强化学习, 并介绍了5大基准测试平台: Safety Gym、safe-control-gym、SafeRL-Kit、D4RL、NeoRL. 最后总结了安全强化学习在自动驾驶、机器人控制、工业过程控制、电力系统优化和医疗健康领域中的应用, 并给出结论与展望.
作为一种重要的机器学习方法, 强化学习 (Reinforcement learning, RL) 采用了人类和动物学习中 “试错法” 与 “奖惩回报” 的行为心理学机制, 强调智能体在与环境的交互中学习, 利用评价性的反馈信号实现决策的优化[1]. 早期的强化学习主要依赖于人工提取特征, 难以处理复杂高维状态和动作空间下的问题. 近年来, 随着计算机硬件设备性能的提升和神经网络学习算法的发展, 深度学习由于其强大的表征能力和泛化性能受到了众多研究人员的关注[2-3]. 于是, 将深度学习与强化学习相结合就成为了解决复杂环境下感知决策问题的一个可行方案. 2016年, Google公司的研究团队DeepMind创新性地将具有感知能力的深度学习与具有决策能力的强化学习相结合, 开发的人工智能机器人AlphaGo成功击败了世界围棋冠军李世石[4], 一举掀起了深度强化学习的研究热潮. 目前, 深度强化学习在视频游戏[5]、自动驾驶[6]、机器人控制[7]、电力系统优化[8]、医疗健康[9]等领域均得到了广泛的应用.
近年来, 学术界与工业界开始逐步注重深度强化学习如何从理论研究迈向实际应用. 然而, 要实现这一阶段性的跨越还有很多工作需要完成, 其中尤为重要的一项任务就是保证决策的安全性. 安全对于许多应用至关重要, 一旦学习策略失败则可能会引发巨大灾难. 例如, 在医疗健康领域, 微创手术机器人辅助医生完成关于大脑或心脏等关键器官手术时, 必须做到精准无误, 一旦偏离原计划位置, 则将对病人造成致命危害. 再如, 自动驾驶领域, 如果智能驾驶车辆无法规避危险路障信息, 严重的话将造成车毁人亡. 因此, 不仅要关注期望回报最大化, 同时也应注重学习的安全性.
García和Fernández[10]于2015年给出了安全强化学习 (Safe reinforcement learning, SRL) 的定义: 考虑安全或风险等概念的强化学习. 具体而言, 所谓安全强化学习是指在学习或部署过程中, 在保证合理性能的同时满足一定安全约束的最大化长期回报的强化学习过程. 自2015年起, 基于此研究, 学者们提出了大量安全强化学习算法. 为此, 本文对近年来的安全强化学习进行全面综述, 围绕智能体的安全性问题, 从修改学习过程、修改学习目标以及离线强化学习三方面进行总结, 并给出了用于安全强化学习的5大基准测试平台: Safety Gym、safe-control-gym、SafeRL-Kit、D4RL、NeoRL, 以及安全强化学习在自动驾驶、机器人控制、工业过程控制、电力系统优化以及医疗健康领域的应用. 安全强化学习中所涉及的方法、基准测试平台以及应用领域之间的关系如图1所示.