

Transformer 模型的崛起显著推动了机器学习模型的发展。大规模语言模型(LLMs)通过对海量数据进行训练,并依托强大的计算资源,统一了传统的自然语言处理(NLP)范式,能够通过将多种下游任务整合到生成工作流中,来有效处理这些任务。在现实世界的影响方面,LLMs 已经彻底改变了研究人员、开发人员和用户的可访问性和可用性。此外,LLMs 极大地降低了人工智能的应用门槛,为应用程序和用户提供了预训练的语言理解与指令跟随能力。因此,强大的 LLMs 为各个领域带来了新的可能性,包括智能体、智能助手、聊天机器人和搜索引擎。然而,这些模型的广泛可用性和可访问性也带来了潜在的风险,包括恶意使用和隐私问题。使 LLMs 具有价值的自由生成工作流也可能被滥用,从而危及隐私或用于有害目的。尽管已经做出了大量努力以提升 LLMs 的可信度,解决其安全性和隐私问题,但新型攻击经常被提出,旨在绕过现有的防御机制,并将 LLMs 用于恶意用途。因此,针对 LLMs 的可信度,恶意攻击者和防御者之间存在持续的博弈,许多重大挑战仍未被发现。为了全面研究 LLMs 的可信度问题,我们识别了新型的攻击,集中于信息泄露问题,改进了防御机制以应对各种攻击,并通过实证评估攻击在有无防御的情况下的效果。对于已识别的攻击,我们重点关注向量数据库中的信息泄露问题,研究嵌入的隐私泄露。除了嵌入信息泄露外,我们还演示了如何通过越狱提示词攻击 LLMs,进而恢复私密的训练数据。在讨论了攻击后,我们提出了新的防御方法,以防止嵌入中的信息泄露。最后,我们实现了一个基准测试,用于实证评估攻击在有无防御情况下的表现。我们进行了大量实验,以验证我们发现的攻击与防御的有效性。我们的评估基准结果揭示了攻击假设与防御假设之间未曾察觉的差距。
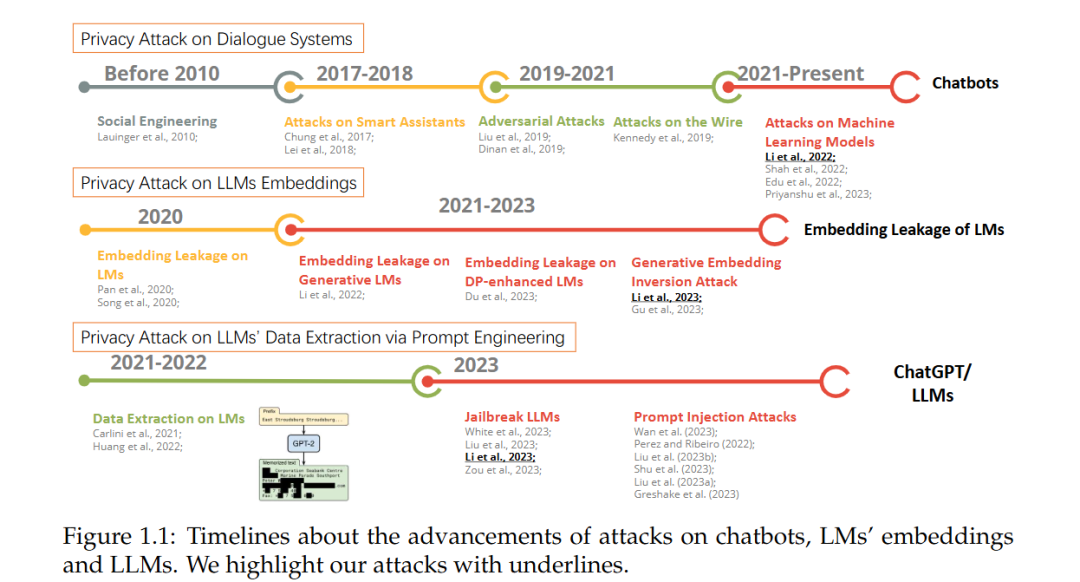
预训练语言模型(LMs)基于 Transformer 架构,标志着自然语言处理(NLP)领域变革时代的开始。通过在特定任务数据上微调预训练的 LMs,可以在广泛的任务上实现无与伦比的性能[98]。目前,生成式大规模语言模型(LLMs)通过将多种自然语言处理任务整合到一个全面的文本生成框架中,展现了卓越的能力。这些 LLMs,包括 OpenAI 的 GPT-4 [112]、Anthropic 的 Claude 3 和 Meta 的 Llama 3 [3],在理解和生成自然语言方面展现了最先进的表现。因此,尽管没有额外的微调,这些 LLMs 在预定义任务和现实世界挑战中依然占据主导地位[129, 33, 12, 112, 113, 68, 21]。除了生成可读文本,LLMs 还能够自动化许多跨领域的任务,使其成为编程和艺术设计等应用中不可或缺的工具。此外,LLMs 展现了令人印象深刻的泛化能力,能够处理未见过的任务。在适当的指令(提示)和示范下,LLMs 甚至能够理解特定的上下文或处理新任务,而无需进一步的微调[30, 200, 75, 169, 134]。因此,将 LLMs 融入各种应用场景,从科学研究到智能助手,具有广阔的前景。然而,LLMs 的开放式生成也带来了内容安全和数据隐私方面的固有脆弱性。在内容安全方面,恶意攻击者可能会操控 LLMs 的指令,使其输出有害的响应。提示注入攻击[160, 121, 97, 144, 96, 52]和越狱攻击[84, 36, 141, 167]能够引导 LLMs 输出攻击者希望的任何内容。在数据隐私方面,LLMs 可能会泄露其敏感的训练数据。在提高性能的背后,LLMs 以巨大的模型规模吞噬了海量的训练数据。即便是 API 级别访问 LLMs,也可能导致个人身份信息(PII)的意外泄露[84, 99, 60, 19, 202, 163]。安全性和隐私风险引发了广泛的讨论和批评,关于如何合理使用人工智能的议题已成为焦点。作为回应,政府已更新或提出新的关于生成式人工智能的法规。这些新法规,如《欧盟人工智能法案》、通用数据保护条例(GDPR)和《加利福尼亚消费者隐私法案(CCPA)》都强调了人工智能模型的合理使用,以实现社会公益。尽管存在风险,将多种应用整合到 LLMs 中已成为日益增长的趋势。这些整合赋予 LLMs 有效解决数学问题的工具(如 ChatGPT + Wolfram Alpha)、解释格式化文件的能力(如 ChatPDF),并通过使用搜索引擎响应用户查询以减少幻觉(如新 Bing)。然而,当 LLMs 与外部工具(如搜索引擎)结合时,领域特定的隐私和安全风险也随之而来。例如,正如[84]中讨论的,恶意攻击者可能会利用新 Bing 将受害者的个人身份信息(PII)与部分数据关联起来。因此,LLMs 中存在的完整安全性和隐私问题仍然不明确。本论文的最终目标是提升 LLMs 在内容安全和数据隐私方面的可信度。因此,本文的重点集中在以下几个方面的攻击、防御和评估:
- 我们提出了新类型的攻击,包括向量数据库嵌入中的信息泄露和通过越狱提取训练数据的攻击。
- 我们升级了现有的防御机制,以防止信息泄露问题。
- 我们通过实证方法评估现有攻击在有无防御机制情况下的性能,并讨论它们的权衡和局限性。



