在过去的几年里,深度学习、大规模数据以及更强大的计算能力的进步为计算机视觉带来了无数的突破。例如,在某些较低级别的视觉识别任务中,包括图像分类、分割和目标检测,机器已经取得了接近人类的表现,甚至超过人类。然而,对于其他需要更详细理解视觉内容的更高层次的视觉任务,如视觉问答(VQA)和视觉描述(VC),机器仍然落后于人类。这在一定程度上是因为,与人类不同,机器缺乏对内容建立全面的、结构化的理解的能力,在此基础上进行推理。具体来说,更高层次的视觉任务通常被简化为直接在图像上操作模型,并由端到端神经网络处理,而没有考虑场景的组成语义。已有研究表明,基于深度神经网络的模型有时会因为从有偏见的数据集中获取捷径而犯下严重的错误。此外,神经网络的“黑箱”性质意味着它们的预测几乎无法解释,这不利于VQA这样的视觉推理任务。作为连接两个层次的中级表示,视觉场景的结构化表示,如成对对象之间的视觉关系,已被证明不仅有利于组合模型学习与结构一起推理,而且为模型决策提供了更高的可解释性。尽管如此,这些表示比传统的识别任务受到的关注要少得多,留下了许多未解决的开放挑战(例如,不平衡谓词类问题)。
在本文中,我们研究如何用视觉关系作为结构化的表示来描述单个图像或视频的内容。两个对象(分别是主语和宾语)之间的视觉关系是由一个三元组(主语、谓语、宾语)形式定义的,它包括主语和宾语的边界框和类别标签以及谓语标签。视觉关系的三元组形式自然类似于人类用语言句子描述两个对象之间的交互:副词(谓语)连接主语和宾语,如“person is sitting on a chair”用(person,sitting on,chair)表示。为了建立场景的整体表示,通常采用以视觉对象为节点、谓词为有向边的图结构来考虑对象和关系上下文。例如,“坐在椅子上的人拿着杯子”可以用(person,sitting on,chair)和(person,holding,glass)来表示,两种视觉关系三联中的人指的是同一个实体。
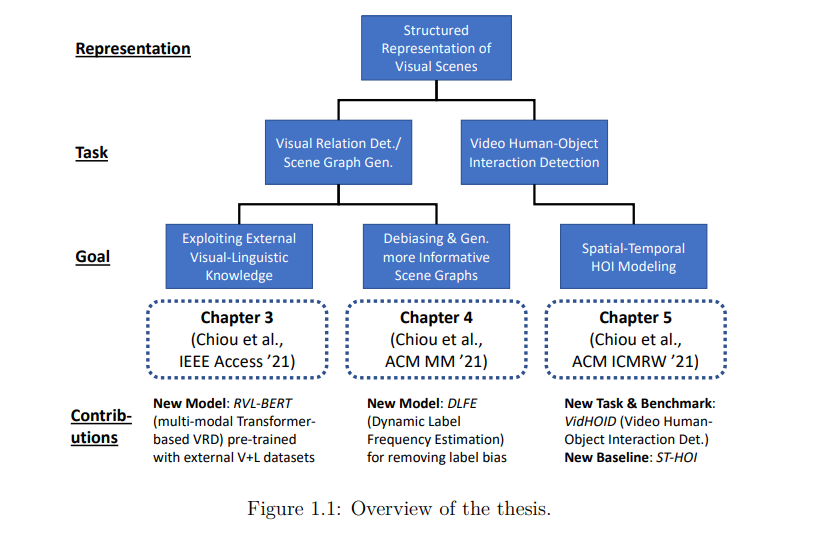
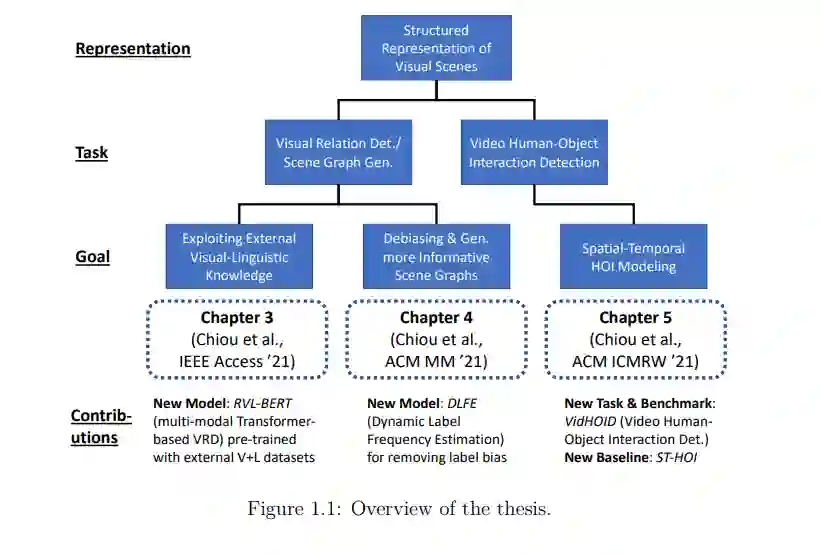
在论文的第一部分,我们花了两章的时间学习具有视觉关系和场景图的图像的结构化表示,它们分别被称为视觉关系检测(VRD)和场景图生成(SGG)。首先,我们深入研究了如何结合外部知识进行VRD。受最近预训练表示成功的启发,我们提出了一个基于transformer的多模态模型,该模型通过在大规模语料库上预训练获得的视觉和语言知识来识别视觉关系。该模型还配备了一个独立的空间模块和一个新型的掩码注意力模块,以显式捕捉物体之间的空间信息。这些设计有利于VRD,并帮助模型在两个具有挑战性的VRD数据集上取得具有竞争力的结果。其次,我们重新思考了数据集知识的作用,认为其中一些是“不好的”知识,会对预测视觉关系产生偏见,应该被删除。具体来说,我们从报告偏差的新视角来解决关键的数据失衡问题,这一问题源于数据集本身,导致机器更喜欢简单的谓词(人,在,椅子上)或(鸟,在,房间),而不是更有信息的谓词(人,坐在椅子上)或(鸟,在,房间里)。为了消除这种报告偏差,我们开发了一种模型无关的去偏差方法,通过考虑谓词类被标记的可能性来生成更有信息的场景图。此外,我们将重点从VRD转移到SGG,以生成整体的、图形化的表示,并利用消息传递网络来结合上下文。大量的实验表明,我们的方法显著地缓解了长尾,达到了最先进的SGG去偏性能,并产生了显著的更细粒度的场景图。
在论文的第二部分,我们将静态图像VRD的设置扩展到时间域,并考虑人-物交互(HOI)检测,这是VRD的一个特殊情况,视觉关系的对象仅限于人类。研究人员使用仅对静态图像进行操作的传统HOI方法来预测视频中与时间相关的HOI;然而,通过这种方式,模型忽略了时间上下文,可能会提供次优性能。另一项相关任务,视频视觉关系检测(VidVRD),也不是一个合适的设置,因为VidVRD方法通常忽略了与人相关的特征,视频对象检测仍然具有挑战性,以及动作边界标记本身可能不一致。因此,我们建议通过明确地考虑时间信息和采用基于关键帧的检测来弥补这些差距。我们还表明,由于特征不一致的问题,一个普通动作检测基线的朴素时间感知变体在基于视频的HOI中表现不佳。然后,我们提出了一个新颖的、基于神经网络的模型,利用时间信息,如人体和物体的轨迹、帧局部视觉特征和时空掩蔽的人体姿态特征。实验表明,我们的方法不仅在我们提出的视频HOI基准中是一个可靠的基线,而且在流行的视频关系检测基准中也是一个有竞争力的选择。
总的来说,在这些工作中,我们探索了如何在静态图像和视频设置中分别构建和学习视觉场景的结构化表征,通过引入外部知识、减少偏差机制和/或增强表征模型进行改进。在本文的最后,我们还讨论了一些开放性的挑战和局限性,为视觉场景的结构化表示学习指明了未来的方向。