MIT博士用概率编程让AI和人类一样看三维|NeurIPS 2021
![]()
新智元报道

新智元报道
编辑:LRS
【新智元导读】神经网络模型最大的弊端就在于无法理解物理世界的常识,人类一眼就能看到的物体,AI模型却视而不见;盘子都漂浮在空中了,模型还觉得自己预测对了。MIT博士在NeurIPS 2021带来的工作也许能帮你在视觉模型中注入这些物理常识,获得三维场景感知能力!
人与AI之间最大的区别就是对常识的利用!
无论各种AI模型在各大排行榜以何种性能超越了人类,它们在常识的利用上仍然远远不及人类,而这也正是目前AI研究中需要面临的一个巨大的挑战。
对于自然语言处理的研究来说,我们可以向模型中添加各种知识图谱、实体等信息来增强模型对于常识的感知能力,但对于计算机视觉来说就没有那么容易了。

视觉的常识不仅要考虑各个物体之间在现实中的空间关系,还要考虑物体位置的合理性。
如果有物理世界的常识能够注入到视觉系统中,那就不会识别出悬空的盘子、藏在碗后面的叉子若隐若现等等「育碧」特色建模。

更严重一点的说,当不完善的、没有常识的视觉系统应用到自动驾驶系统时,导致无法识别出行人、急救车等,或者错误理解了空间位置关系,那后果将不堪设想。
人类的视觉和AI视觉略有不同,人类的眼睛实际上是三维的,能够对不同视角、不同光照、遮挡和杂乱的场景进行视觉概括。
所以为了给计算机一个三维场景感知的能力,MIT的研究人员最近在NeurIPS 2021上发表了一篇论文,提出了一个基于概率推理的3D场景感知的生成模型3DP3。

模型有了3D感知能力以后,除了可以提高自动驾驶汽车的安全性之外,还可以让清洁机器人感知杂乱场景下物体间的相互关系。

3DP3的核心就是一个生成式的建模框架,使用离散的物体及其三维形状和一个称为场景图(scene graph)的层次结构来表示场景,其中场景图的层次结构与物体的位置和朝向有关。
研究人员使用概率编程来建立框架,让系统能够从输入图像中检测到物体。通过概率推理(probabilistic inference)的方式也可以让系统推断出场景和物体的不匹配是由噪声还是预测错误导致的,增加了可解释性,也有利于下一步处理中的纠正。
例如给定一副RGB图像和对应的深度图,3DP3就可以推断出一个层次的3D场景图。
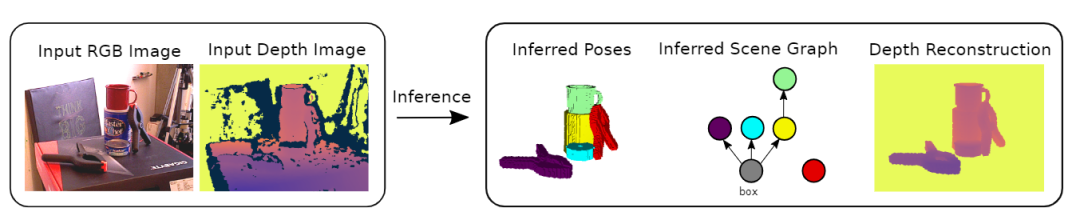
并且因为模型懂常识,一个物体经常是平放(lay flat)在另一个物体上,所以从深度图中实际上已经可以知道各个物体的位置和朝向了。
除此之外,文中提出的算法还可以推断什么时候这些常识是有用的(紫色节点的夹子和盒子是相关的,因为夹子放在了盒子上),哪些物体用不上(红色节点的四个物体表示一个整体,没有放置在其他物体上)。
但从这幅图上看,瞅着这「四合一」的红色节点还是放置在这个盒子上的,但是文章作者对此没有进一步说明。
并且3DP3使用概率编程(probabilistic program)的形式来表示三维场景的结构化生成模型。
模型使用了两个先验概率,1)从数据中学习到的概率作为物体形状的先验,2)图形上的概率分布作为场景结构的先验。然后从世界节点(world node)开始对场景图进行遍历来计算物体的位置、方向和深度图的似然模型。
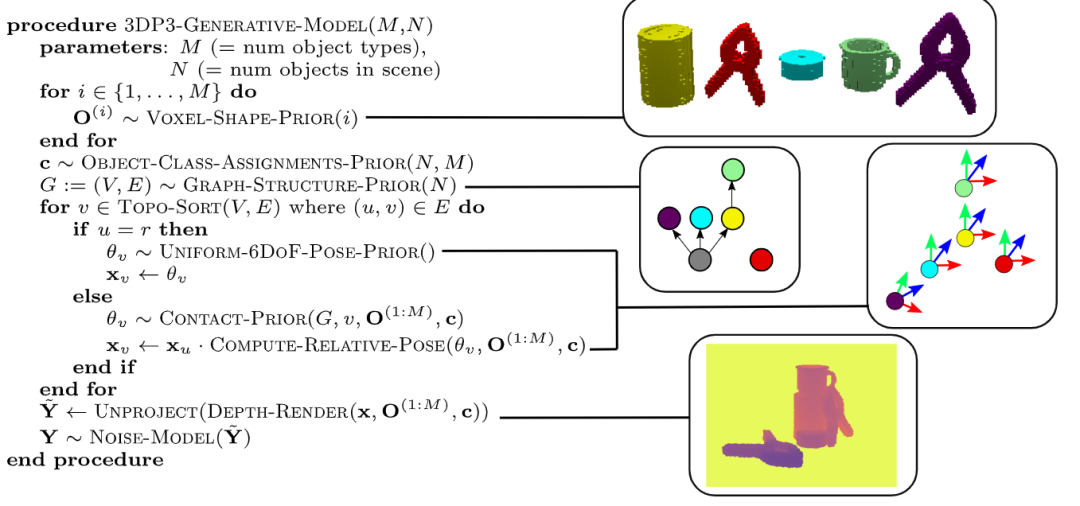
世界节点的意思就是所有没有平放在其他物体上的节点的父节点,例如图中的盒子(灰色节点)和四合一物体(红色节点)的父节点就是世界节点。图中为了简化没有画出世界节点。
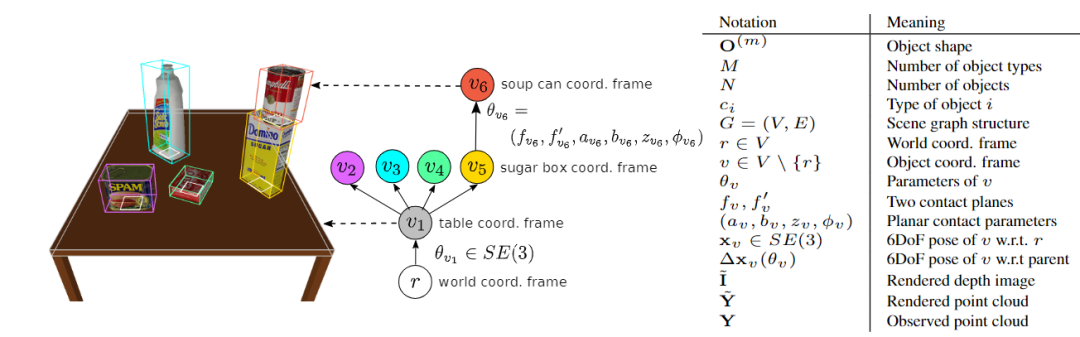
可以看到,3DP3主要以这种物体之间的接触关系的常识和概率来进行场景图的建模,而这种常识恰恰可以保证系统能够检测和纠正计算机视觉中深度学习模型常犯的错误。并且概率推断也能够更准确地推断出物体的正确相对位置。
文章的作者Nishad Gothoskar也认为这和人类的推断过程是相同的:如果你知道了接触关系,那么你肯定会知道一个物体永远不可能漂浮在桌子上,也就是说,在桌子和物体之间必定还存在一个物体,这对于深度学习的黑盒模型来说是一个强有力的解释操作。
并且3DP3不要求对物体形状进行硬编码,而是提出了一个基于体素(voxel)的物体形状学习方法。研究人员使用概率推理来学习三维物体形状的非参数模型,考虑到了由于self-occlusion而产生的不确定性。
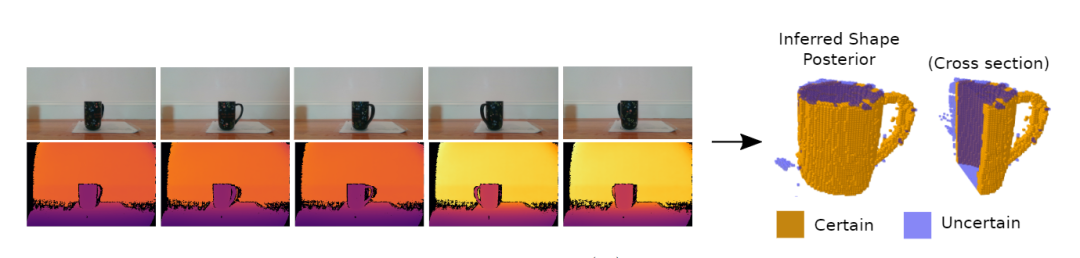
文中主要研究了如何从包含已知类型的单一孤立物体的场景中学习到物体的形状,并没有考虑对更通用的形状学习和对形状不确定性的处理。
有了上面提到的基于接触关系的生成式模型后,就可以搭建一个完整的场景图推理算法了。
由于图像是通过实时图形和点云上的似然概率来建模的,所以研究人员把三维场景的理解作为这种生成模型的近似概率推理。
推理算法将数据驱动的Metropolis-Hastings核与物体姿势、场景图结构的MCMC核、物体形状的不确定性的积分以及现有的深度学习物体检测器和姿势估计器结合起来共同预测。
此外,这种架构能够利用生成模型中的推理来提供常识性的约束,从而修复神经网络检测器所产生的错误。
在实验部分,研究人员使用一个标准的机器人数据集YCB-Video来训练和评估3D感知能力。
首先对每个物体类型选取5张合成图像来学习图形先验,然后使用一个神经6DoF姿势估计模型DenseFusion对模型的推理算法进行初始化。
为了衡量姿势(物体的位置和朝向)预测的准确性,研究人员使用ADD-S来估计物体模型上的点与预测物体姿态之间的平均最近点距离。
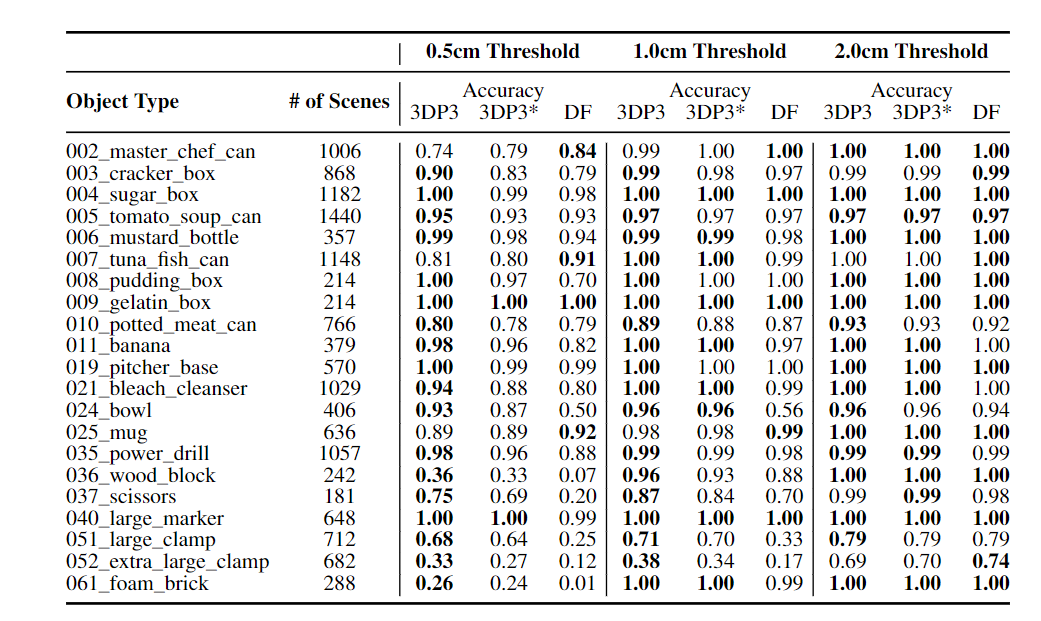
实验结果可以看到,3DP3几乎能够准确预测所有形状的物体,并且在消融实验中可以看到,3DP3比固定结构且没有接触关系的3DP3*更精确。
这也表明了基于渲染和结构推断都有助于3DP3更准确地估计6DoF姿态。
参考资料:
https://arxiv.org/pdf/2111.00312


