

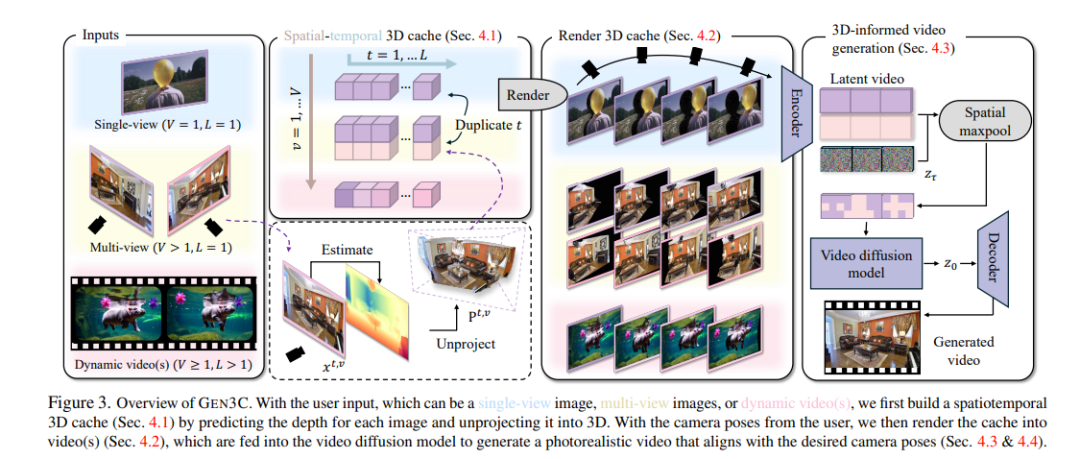
我们提出了GEN3C,一种具有精确相机控制和时间3D一致性的生成视频模型。现有的视频模型已经能够生成逼真的视频,但它们往往利用较少的3D信息,导致不一致性,例如物体突然出现或消失。即使实现了相机控制,也不精确,因为相机参数仅仅是神经网络的输入,网络必须推断视频如何依赖于相机。相比之下,GEN3C通过3D缓存进行引导:通过预测种子图像或先前生成帧的逐像素深度获得的点云。在生成下一帧时,GEN3C以用户提供的新相机轨迹对3D缓存的2D渲染进行条件生成。
至关重要的是,这意味着GEN3C既不需要记住它先前生成的内容,也不需要从相机姿态推断图像结构。相反,模型可以将其生成能力集中在先前未观察到的区域,并将场景状态推进到下一帧。我们的结果表明,与现有工作相比,GEN3C实现了更精确的相机控制,并在稀疏视角新视图合成中取得了最先进的结果,即使在驾驶场景和单目动态视频等具有挑战性的设置中也是如此。最佳效果请观看视频。访问我们的网页:https://research.nvidia.com/labs/toronto-ai/GEN3C/。
成为VIP会员查看完整内容
相关内容
Arxiv
37+阅读 · 2023年4月19日
Arxiv
199+阅读 · 2023年4月7日
Arxiv
137+阅读 · 2023年3月29日
相关VIP内容
相关资讯
相关论文
Arxiv
37+阅读 · 2023年4月19日
Arxiv
199+阅读 · 2023年4月7日
Arxiv
137+阅读 · 2023年3月29日