

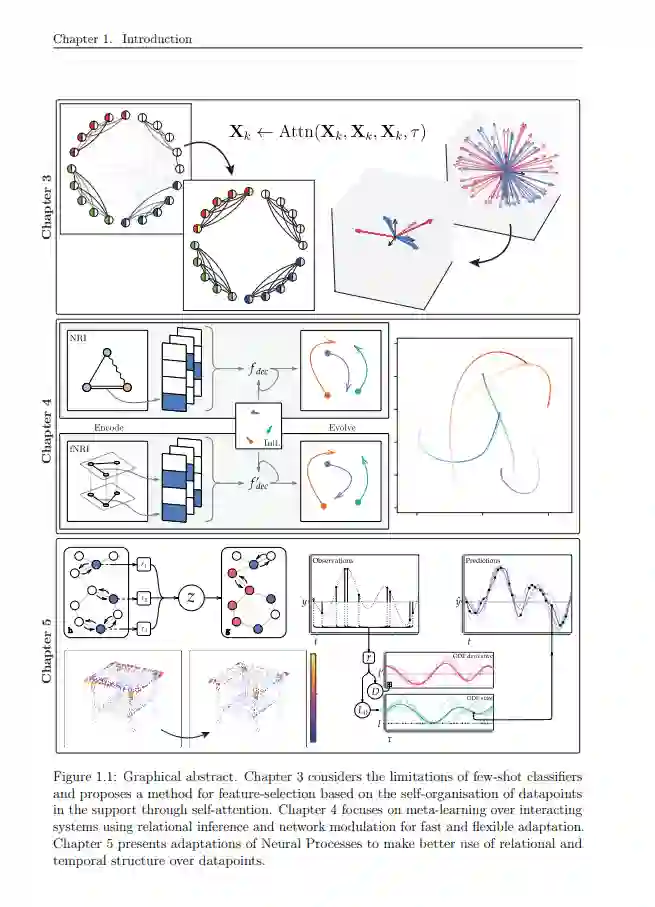
表示学习已经成为一种多功能工具,能够利用使用数字技术获得的大量数据集。该方法的广泛适用性源于其作为子系统使用的灵活性和在模型架构中纳入先验的可扩展性。数据内部的直观依赖关系,如像素主要对其邻近的上下文做出贡献,可以被形式化和嵌入,以提高泛化,并允许具有很大能力的模型避免过拟合。元学习也被应用于将这些系统扩展到低数据设置,通过将特定任务视为更普遍问题的实现而不损失性能。本文考虑如何利用这些方法的基本兼容性。本工作的主要论点是,归纳偏差提供的计算的清晰度可以用于改进元学习架构,并直接构建元学习器过去经验和解决问题能力到新任务的迁移。通过融合这些方法开发的方法可以在广泛的设置和领域中提高与基线模型相比的性能。融合有三种实现方式。第一个将复合分类确定为一种自然设置,并展示了如何使用注意力下数据点的自组织来增强元学习分类器。第二种使用显式关系推理来调节和重组神经模块,以在测试时快速准确地适应。自适应神经过程来捕获关系和时间依赖,以提高预测和不确定性估计的准确性和一致性。在验证本文的激励假设时,这些贡献在其他领域中发现了最先进的应用,包括小样本图像分类、粒子控制系统的相互作用的无监督恢复、蛋白质-蛋白质相互作用位点预测以及动力系统的识别和演化。通过这样做,这项工作有助于使机器智能应用于更广泛、更精细的问题范围——作为所考虑问题的解决方案,作为进一步应用的架构模板,以及作为未来研究的方向。

成为VIP会员查看完整内容
相关内容

Arxiv
1+阅读 · 2023年4月7日
Arxiv
15+阅读 · 2021年5月19日



相关VIP内容
相关资讯