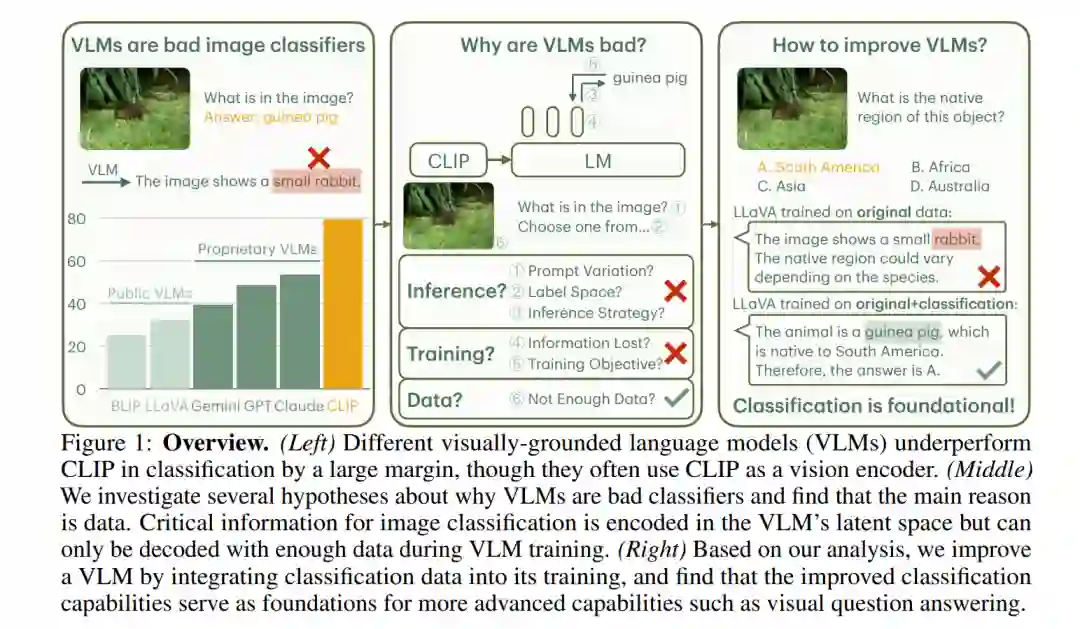
图像分类是机器视觉智能最基本的能力之一。在本研究中,我们重新审视了使用视觉嵌入语言模型(VLMs),如GPT-4V和LLaVA,进行图像分类的任务。我们发现,尽管现有的专有和公开VLMs通常使用CLIP作为视觉编码器,并且拥有更多的参数,但在标准图像分类基准(如ImageNet)上的表现显著低于CLIP。为了理解原因,我们探索了几个关于VLM推理算法、训练目标和数据处理的假设。
我们的分析表明,主要原因与数据相关:图像分类所需的关键信息被编码在VLM的潜在空间中,但只有在足够的训练数据下才能有效解码。具体而言,VLM训练和指令微调过程中类曝光频率与VLM在这些类别上的表现存在强相关性;当VLM在充分的数据上训练时,其分类精度可以与最先进的分类模型相媲美。
基于这些发现,我们通过将专注于分类的数据集整合到VLM的训练中来增强模型,并展示了增强后的VLM分类性能能够迁移到其一般能力上,最终在新收集的ImageWikiQA数据集上提高了11.8%的性能。
https://www.zhuanzhi.ai/paper/fac7e79dd983933eacb04931ec491f0c
图像识别是机器视觉的基本能力之一。在过去的15年里,深度学习和大规模数据集的出现使这一领域取得了显著突破[11, 48]。例如,在著名的ImageNet数据集上,该数据集用于将图像分类为1,000个类别,错误率已从2009年的47.1%大幅下降至2024年的9.1%,下降幅度达5倍[30, 12]。因此,这些分类模型已经超越了大多数人工标注者。
如今,研究界已将关注点转向更复杂、更细致的视觉智能能力。视觉嵌入语言模型(VLMs)通过将视觉编码器的视觉信号与大型语言模型结合,最近成为了一种有前景的范式[2, 36, 32]。像GPT-4V [36]、Gemini-1.5 [44] 或 Claude-3 [3]等VLMs已展示了先进的视觉理解能力,例如从表格图像中回答数学问题或从设计草图生成HTML代码。
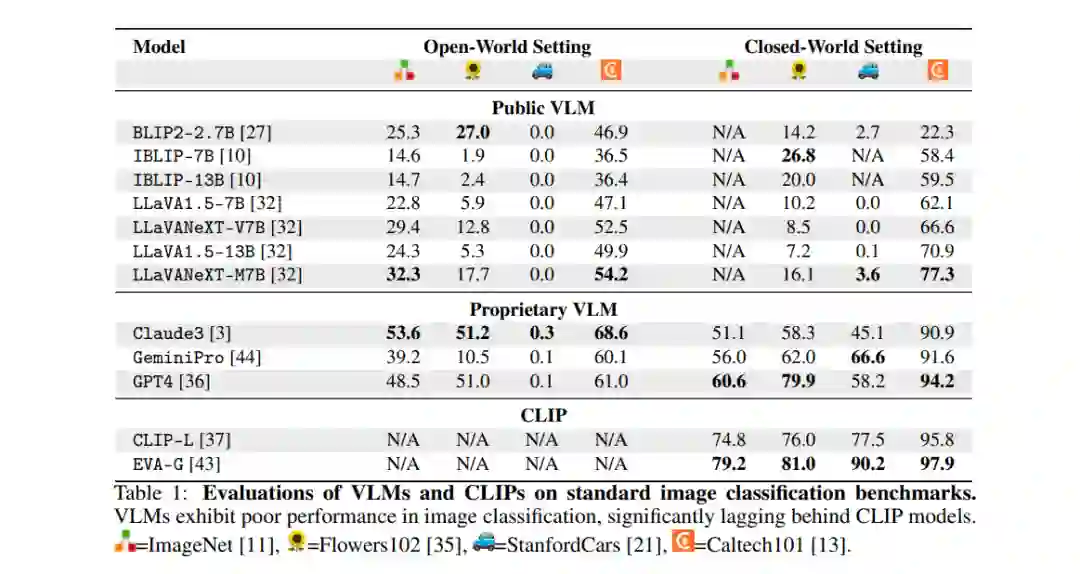
在这项工作中,我们重新审视了使用VLM进行图像分类的基本任务。令人惊讶的是,我们发现各种公开和专有的VLM在图像分类任务上存在困难,无论是在开放世界设置(类别列表未知)还是封闭世界设置(提供了类别名称的上下文)中 (§2)。尽管VLM的参数远多于CLIP,但它们在标准图像分类任务上的表现明显逊色。我们的评估协议是将每个图像和类别名称列表(在封闭世界设置中)作为上下文输入给VLM,并询问图像中的内容;成功的定义是生成的输出是否包含真实类别名称。 为了理解为什么VLM在分类任务中的表现不佳,我们调查了关于VLM推理(如提示变化、标签集大小、推理策略;§3.1)、训练(如信息丢失、训练目标;§3.2)和数据(如数据与性能的相关性;§3.3)等方面的几个假设。我们的广泛分析表明,观察到的性能差距主要是由于数据相关。我们发现,图像分类所需的信息被编码在VLM的潜在空间中,但只有通过正确的训练数据才能有效解码。具体而言,VLM训练过程中类别的曝光频率与VLM在这些类别上的表现之间存在强相关性。此外,使用分类数据集对VLM进行训练,可以实现与最先进的分类模型相同的性能水平。 基于我们的分析,我们提出了一种简单的方法,通过将传统的分类数据集整合到VLM训练中,来增强VLM的通用能力 (§4)。我们认为,分类是更复杂、更高级的视觉能力的基础;例如,识别物体是回答关于该物体复杂问题的前提。为了验证这一点,我们创建了ImageWikiQA,它包含关于ImageNet物体的复杂现实问题。在ImageWikiQA上,我们发现,经过ImageNet分类数据集微调的VLM在识别这些物体时取得了显著更高的准确率,并能够更准确地回答这些非分类问题,超越了预训练的VLMs,提升了11.8%。这表明,经典的分类数据可以有益地重新用于VLM的训练过程,从而提升VLM的性能。 总结我们的贡献:
- 评估VLM分类弱点:我们对10个VLM在四个基准测试上的评估显示,VLM在分类任务上的表现远远落后于CLIP,揭示了以往研究未曾解决的差距。
- 分析分类性能差的原因:通过测试不同的假设,我们发现缺乏对齐数据(而非信息丢失或训练目标)是VLM在分类任务中表现不佳的主要原因。
- 通过分类数据增强VLM:通过添加分类数据,我们提高了VLM在物体识别和整体性能上的准确性,支持了分类能力是复杂物体相关推理的基础。