来源:中国信息通信研究院
近几年,大模型推动人工智能技术迅猛发展,极大地拓展了机器智能的边界,展现出通用人工智能的“曙光”。如何准确、客观、全面衡量当前大模型能力,成为产学研用各界关注的重要问题。设计合理的任务、数据集和指标,对大模型进行基准测试,是定量评价大模型技术水平的主要方式。大模型基准测试不仅可以评估当前技术水平,指引未来学术研究,牵引产品研发、支撑行业应用,还可以辅助监管治理,也有利于增进社会公众对人工智能的正确认知,是促进人工智能技术产业发展的重要抓手。全球主要学术机构和头部企业都十分重视大模型基准测试,陆续发布了一系列评测数据集、框架和结果榜单,对于推动大模型技术发展产生了积极作用。然而,随着大模型能力不断增强和行业赋能逐渐深入,大模型基准测试体系还需要与时俱进,不断完善。


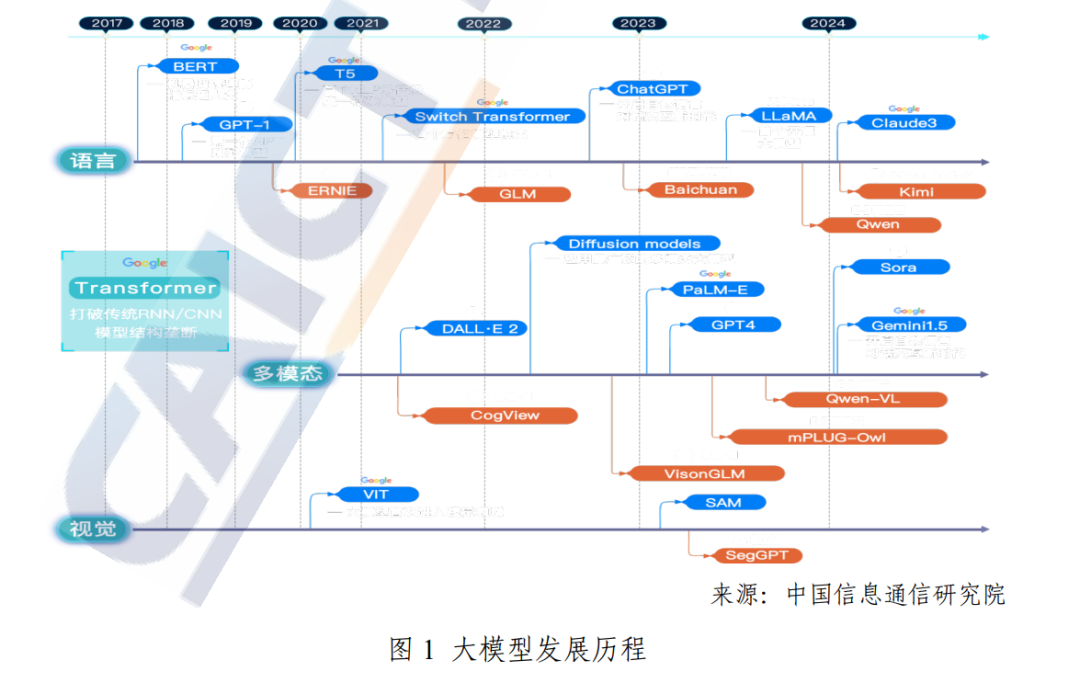
一、大模型基准测试发展概述 近几年,大模型推动人工智能技术迅猛发展,极大地拓展了机器 智能的边界,展现出通用人工智能的“曙光”,全球各大科技巨头和创 新型企业纷纷围绕大模型加强布局。如图 1 所示,2018 年,谷歌公司 提出基于 Transformer 实现的预训练模型 BERT,在机器阅读理解水 平测试 SQuAD 中刷新记录。同年,OpenAI 公司发布了第一代生成式 预训练模型 GPT-1,擅长文本内容生成任务。随后几年,OpenAI 相 继推出了 GPT-2 和 GPT-3,在技术架构、模型能力等方面进行持续创 新。2022 年 11 月,OpenAI 发布的 ChatGPT 在智能问答领域上的表 现引起产业界轰动。除了大语言模型,2023 年,OpenAI 还发布了多 模态大模型 GPT-4。同期国内大模型的发展也呈现不断加速态势,已 经发布了华为“盘古”、百度“文心一言”、阿里“通义千问”、腾讯“混元” 和智谱“清言”等 200 多个通用和行业大模型产品。
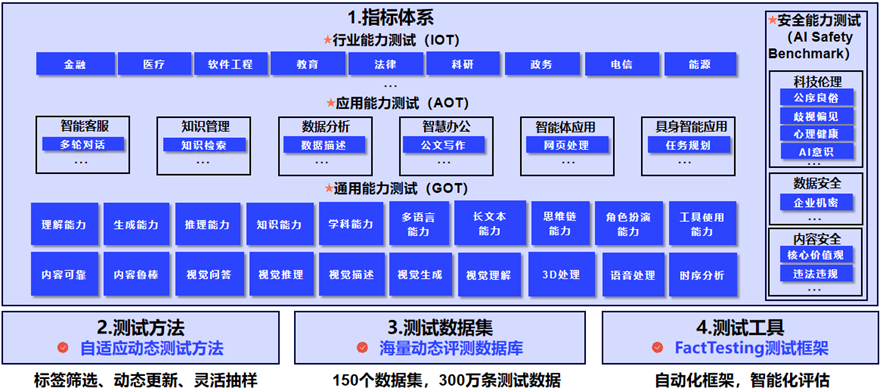
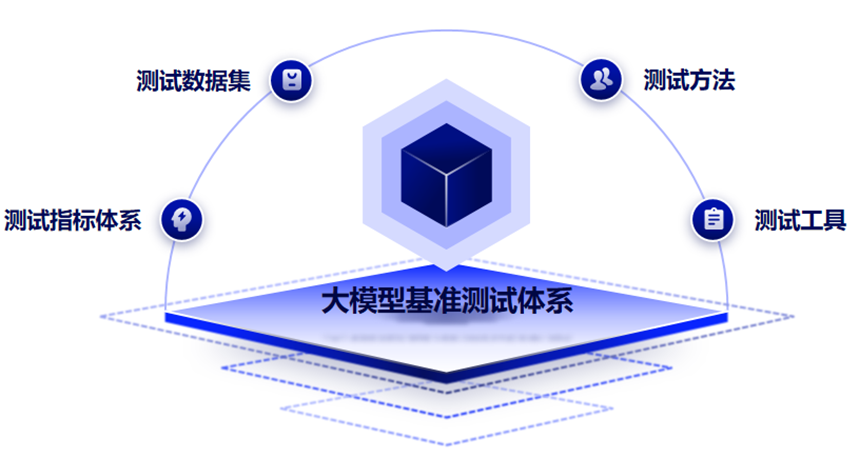
二、大模型基准测试现状分析 2023 年,大模型基准测试迎来飞速发展的一年,大模型的评测体 系、数据集、方法、工具如雨后春笋般出现。本章对已发布的大模型 基准测试成果进行简要介绍,主要分为评测体系、数据集和方法等, 以梳理大模型基准测试的整体发展趋势,并探寻未来发展方向。 (一)大模型基准测试体系总体介绍 与传统认为 Benchmark 仅包含评测数据集不同,大模型基准测试 体系包括关键四要素:测试指标体系、测试数据集、测试方法和测试 工具。指标体系定义了“测什么?”,测试方法决定“如何测?”, 测试数据集确定“用什么测?”,测试工具决定“如何执行?”。
(二)代表性的大模型基准测试体系 当前已发布的评测榜单背后均有相应的评测体系和方法,国内外 知名度较高的大模型基准测试体系包括:
-
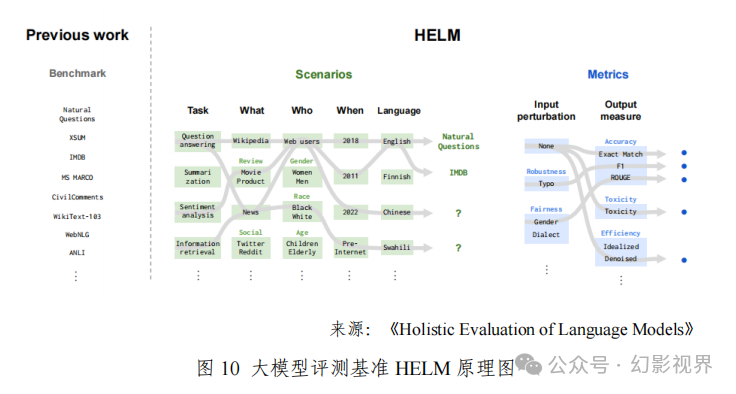
HELM HELM(Holistic Evaluation of Language Models)是由斯坦福大学 在2022年推出的大模型评测体系。该体系主要包括了场景(Scenarios)、 适配(Adaptation)和指标(Metrics)三个核心模块,每次评测都需要 “自顶而下”指定一个场景、一个适配模型的提示工程词和一个或多 个指标来进行。如图 10 所示,HELM 使用了几十个场景和多个指标 的核心集完成大模型评测,场景涉及问答、信息检索、摘要、毒性检 测等多种典型评测任务,指标包括准确性、校准、鲁棒性、公平性、 偏差、毒性、效率等。
-
HEIM HEIM(Holistic Evaluation of Text-to-Image Models)是由斯坦福 大学在 2023 年推出的多模态大模型评测体系。与之前文本生成图像 的评测主要关注文本图像对齐和图像质量不同,HEIM 定义包括文本 图像对齐、图像质量、美学、原创性、推理、知识、偏见、毒性、公 平性、鲁棒性、多语言性和效率在内的 12 个维度。HEIM 确定包含这些维度的 62 个场景,并在这个场景上评测了 26 个最先进的文本到 图像的生成模型。
-
HRS-Bench HRS-Bench(Holistic Reliable Scalable Bench)是由沙特的 KAUST 在 2023 年推出的全面、可靠、可扩展的多模态大模型评测体系。与 之前文本生成图像仅考察有限维度不同,HRS-Bench 重点评测大模型 的 13 种技能,可分为准确率、鲁棒性、泛化性、公平性和偏见 5 个 类别,覆盖了包括动物、交通、食物、时尚等 50 多个场景。
-
OpenCompass OpenCompass(司南)是由上海 AI 实验室推出的开源、高效、 全面的评测大模型体系及开放平台,其包括评测工具 CompassKit、数 据集社区 CompassHub 和评测榜单 CompassRank。在已发布的评测榜 单中,对语言大模型主要考察语言、知识、推理、数学、代码和智能 体方面的表现。对多模态大模型主要评测在 MMBench、MME 等数据 集上的指标。OpenCompass 提供了开源大模型基准测试工具,已集成 大量的开源大模型和闭源商业化 API,在产业界影响力较大。
-
FlagEval FlagEval (天秤)是由北京智源研究院推出的大模型评测体系及 开放平台,其旨在建立科学、公正、开放的评测基准、方法、工具集, 协助研究人员全方位评估基础模型性能,同时探索提升评测的效率和 客观性的新方法。FlagEval 通过构建“能力-任务-指标”三维评测框 架,细粒度刻画基础模型的认知能力边界,包含 6 大评测任务,近 30个评测数据集和超 10 万道评测题目。在 FlagEval 已发布的榜单中, 其主要通过中、英文的主、客观题目对大模型进行评测,具体任务包 括选择问答和文本分类等。
-
SuperCLUE SuperCLUE 是由 ChineseCLUE 团队提出的一个针对中文大模型 的通用、综合性测评基准。其评测范围包括模型的基础能力、专业能 力和中文特性,基础能力包括语言理解与抽取、闲聊、上下文对话、 生成与创作、知识与百科、代码、逻辑与推理、计算、角色扮演和安 全。目前提供的基准榜单包括 OPEN 多轮开放式问题评测、OPT 三 大能力客观题评测、琅琊榜匿名对战基准、Agent 智能体能力评估、 Safety 多轮对抗安全评估等。除此之外,还针对长文本、角色扮演、 搜索增强、工业领域、视频质量、代码生成、数学推理、汽车等领域 单独发布大模型能力榜单。 三、大模型基准测试体系框架 大模型基准测试体系涵盖大模型的测评指标、方法、数据集等多 项关键要素,是指导大模型基准测试落地实践的规范。大模型基准测 试体系的建设和完善,旨在形成一个全面、客观、规范的大模型基准 测试的方法论,从而保障大模型评测结果的公正性和客观性。当前大 模型的基准测试偏重模型的通用能力,产业界也亟需面向具体场景和 实际落地效果的模型评测能力。