![]()
导读 自从2012年谷歌在搜索领域提出知识图谱的概念并应用之后,国内外科技公司在知识图谱领域争先布局。随着知识图谱在各个行业应用的逐渐落地,如何实现大规模语义知识的管理成为研究热点。今天和大家分享下蚂蚁知识图谱平台语义知识管理关键技术实现及应用,今天的介绍会主要分为4个部分:
全文目录:
1.蚂蚁知识图谱平台介绍 2.语义知识表示模型 3.语义知识管理关键技术及应用4.展望5.Q&A分享嘉宾|易鹏 蚂蚁集团 高级技术专家 编辑整理|杨科 出品社区|DataFun***
01****蚂蚁金融知识图谱平台介绍首先介绍知识图谱的发展和蚂蚁知识图谱平台的现状。
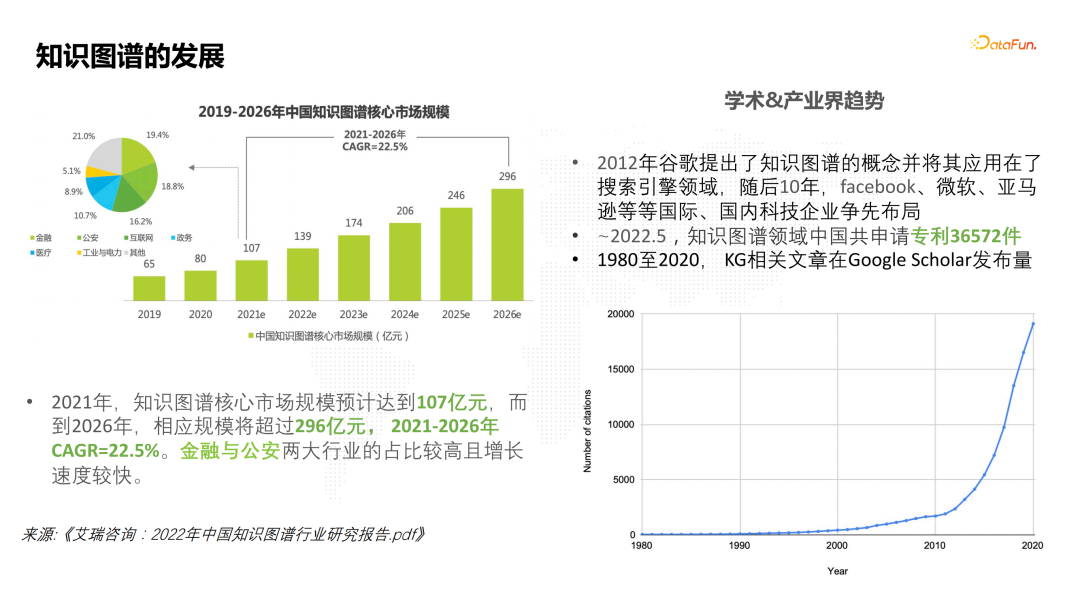
1.知识图谱的发展根据《艾瑞咨询:2022年中国知识图谱行业研究报告》,2021年,知识图谱在国内的核心市场规模预计达到百亿元级别。到2026年,相应规模将超过296亿元,每年复合增长率超过20%。其中金融和公安两大行业的占比较高而且增长的速度更快一些。 ![]() 在学术和产业界,自从2012年谷歌在搜索领域提出了知识图谱的概念并应用之后,随后的10年时间,国内外科技公司在知识图谱包括图数据库和图计算上都争先布局。从谷歌学术发表的知识图谱文章来看,最近5到10年时间,越来越多的技术人员投入到知识图谱领域研发中。
在学术和产业界,自从2012年谷歌在搜索领域提出了知识图谱的概念并应用之后,随后的10年时间,国内外科技公司在知识图谱包括图数据库和图计算上都争先布局。从谷歌学术发表的知识图谱文章来看,最近5到10年时间,越来越多的技术人员投入到知识图谱领域研发中。
2. 蚂蚁知识图谱平台目标
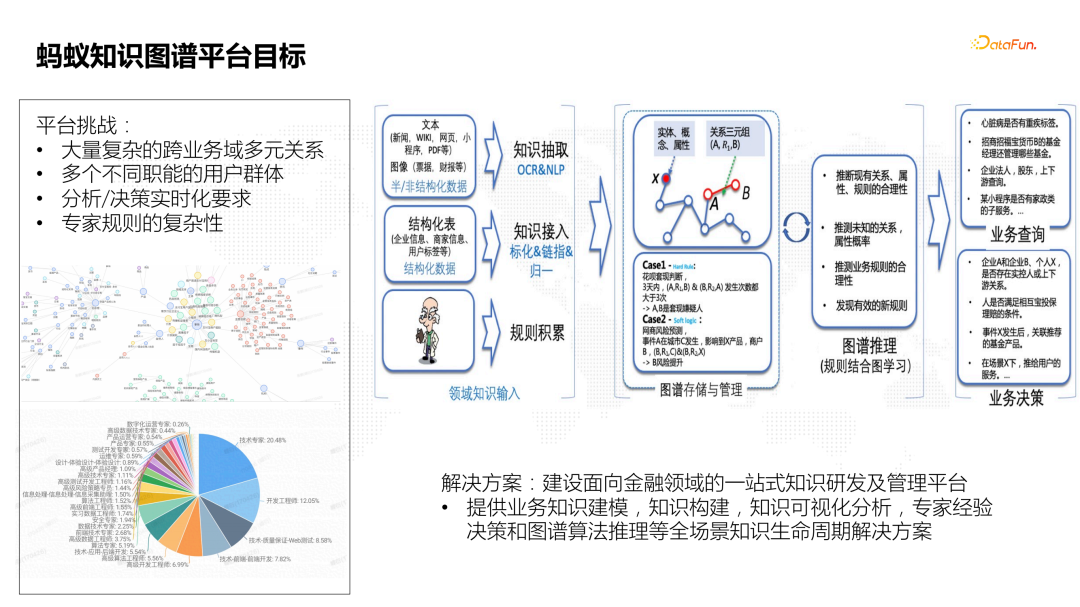
![]() 蚂蚁知识图谱平台建设初期遇到了几个挑战:
蚂蚁知识图谱平台建设初期遇到了几个挑战:
- 大量复杂的跨业务域多元关系。在金融领域,面临的业务场景是多元化的,如支付、安全、保险、财富等。
- 多个不同职能的用户群体。面向不同职能的用户群体比较多,比如算法、运营、数据等。
- 分析/决策实时化要求。图谱的分析或者决策的实时性要求比较高。比如面向C端的保险理赔这些场景。
- 专家规则的复杂性。比如安全风控领域的专家规则就十分复杂。 蚂蚁知识图谱平台的目标就是建设面向金融领域的一站式知识研发和管理平台,提供面向业务的知识建模、知识构建、可视化分析、专家经验决策和图谱算法推理等全场景知识生命周期解决方案。
3. 蚂蚁金融知识图谱建设现状
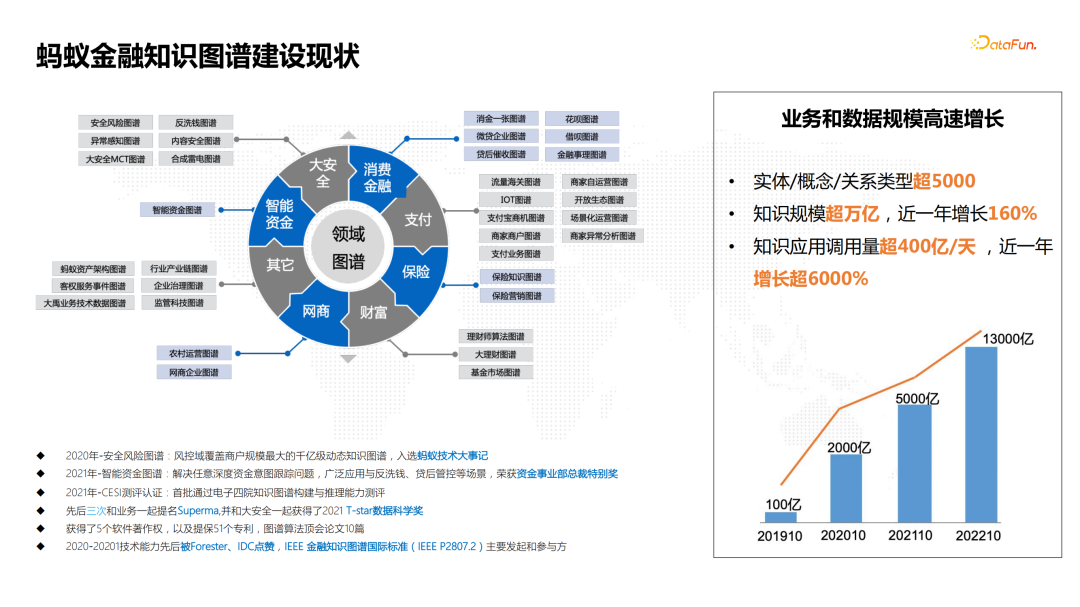
![]() 经过4-5年时间的建设,蚂蚁金融知识图谱已经覆盖了整个金融领域的安全、消费金融、支付、保险、财富、网商、智能资金等很多场景,实体、概念、关系类型超过了5000,知识规模从最初的亿级别快速增长到万亿级别,知识应用调用量也已经超过了每天千亿级别。这也说明金融领域业务对知识图谱的应用需求越来越多。
经过4-5年时间的建设,蚂蚁金融知识图谱已经覆盖了整个金融领域的安全、消费金融、支付、保险、财富、网商、智能资金等很多场景,实体、概念、关系类型超过了5000,知识规模从最初的亿级别快速增长到万亿级别,知识应用调用量也已经超过了每天千亿级别。这也说明金融领域业务对知识图谱的应用需求越来越多。
02
语义知识表示模型知识图谱作为一种语义网络,是大数据时代知识表示的重要方式之一。接下来我们首先介绍语义化的作用、知识的定义和分类以及语义知识表示等基本概念,并引出蚂蚁语义知识表示模型。
1.语义化的作用
![]() 语义化的概念,源于语义网络(Semantic Network),这个概念由奎林(J. R. Quillian)于1968年提出,是一种以网络格式表达人类知识构造的形式,使用语义和语义的关系表示知识的网络结构。语义网络图中,包含两种类型的知识。一种是人们总结的常识类知识。比如从猫到哺乳动物再到动物,它是一种概念的分类体系。另外一种是面向事实类的知识,比如不同猫的个体和人的个体之间的被饲养(has)的关系。语义化的作用主要是两点,一是让数据表示标准化,实现数据的复用。二是不同领域的数据可交互,促进数据编织(Data Fabric)。例如一所医院和一个自然人,他们都有地理位置的信息,有可能是简称,也有可能是全称。要通过地理位置建立医院和自然人之间的联系,就要实现地址位置信息的表示标准化,之后才能实现其之间的关联。
语义化的概念,源于语义网络(Semantic Network),这个概念由奎林(J. R. Quillian)于1968年提出,是一种以网络格式表达人类知识构造的形式,使用语义和语义的关系表示知识的网络结构。语义网络图中,包含两种类型的知识。一种是人们总结的常识类知识。比如从猫到哺乳动物再到动物,它是一种概念的分类体系。另外一种是面向事实类的知识,比如不同猫的个体和人的个体之间的被饲养(has)的关系。语义化的作用主要是两点,一是让数据表示标准化,实现数据的复用。二是不同领域的数据可交互,促进数据编织(Data Fabric)。例如一所医院和一个自然人,他们都有地理位置的信息,有可能是简称,也有可能是全称。要通过地理位置建立医院和自然人之间的联系,就要实现地址位置信息的表示标准化,之后才能实现其之间的关联。
2. 知识分类和定义
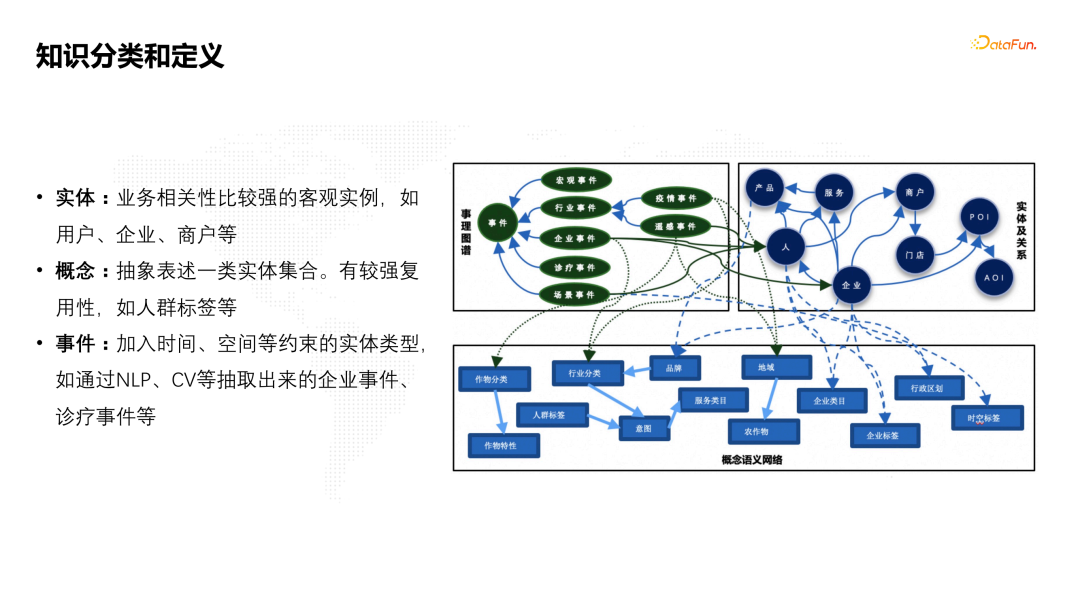
![]() 结合业务场景,我们把知识分成三种类型。
结合业务场景,我们把知识分成三种类型。
- 实体。比如用户、企业、商户等这些业务相关性比较强的客观存在的实例,它是一些个体。
- 概念。概念是对一类实体的抽象概述。比如人的个体,可以分成喜欢运动的,喜欢旅游的,等等,给一类人群贴上标签,就成为人群的概念。
- 事件。第三类是会动态发生变化的事件,它对实体类型加入了时间、空间等约束,比如企业的事件、诊疗的事件,或者交易的事件。 事件、实体及关系、概念构成的语义网络,相互之间会发生连接,整体构成了知识图谱的分类能力。
3. 语义知识表示- SPG(Semantic enhanced Property Graph)
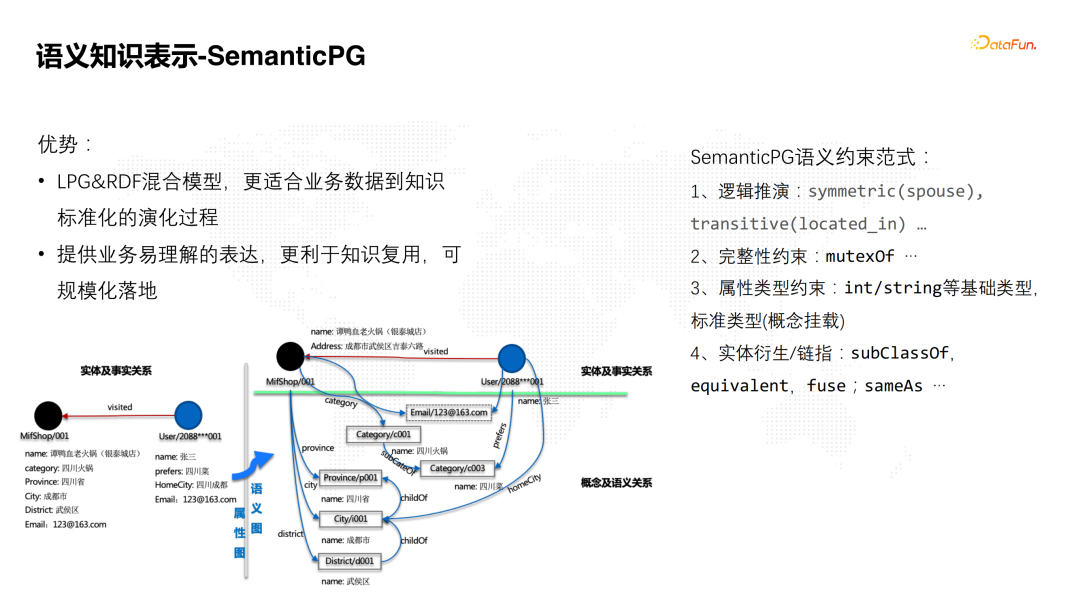
![]() 语义知识表示,即知识建模,业界主要分为标记属性图(Labeled Property Graph)和资源描述框架(Resource Description Framework,RDF)两种主流的模型。两种模型各有优势。LPG基于点边属性实现知识表示,这种建模方式更贴近于图的数据结构表示,相对来说更清晰、更简单,建模成本更低。RDF采用三元组的表示方式,实体之间通过属性建立了丰富的连接,但RDF在工业界的落地相对差一些。在知识图谱构建过程中,面临从业务数据到知识标准化的演化过程。因为在业务建设初期,很多属性的类型都是文本类型。随着概念网络的完善,这些文本类型需要不断地演化到标准类型,从而实现知识的复用,以及与更多其他领域的数据进行连接。因此,我们提出了一种语义增强的属性图模型,它是结合了LPG和RDF优势的混合模型,更适合业务数据到知识标准化的演化过程。它提供业务易理解的表达,更利于知识复用,可规模化落地。这种语义增强的属性图模型,有一些语义约束的范式。我们参考了OWL的表达方式,大概分成如下几类:
语义知识表示,即知识建模,业界主要分为标记属性图(Labeled Property Graph)和资源描述框架(Resource Description Framework,RDF)两种主流的模型。两种模型各有优势。LPG基于点边属性实现知识表示,这种建模方式更贴近于图的数据结构表示,相对来说更清晰、更简单,建模成本更低。RDF采用三元组的表示方式,实体之间通过属性建立了丰富的连接,但RDF在工业界的落地相对差一些。在知识图谱构建过程中,面临从业务数据到知识标准化的演化过程。因为在业务建设初期,很多属性的类型都是文本类型。随着概念网络的完善,这些文本类型需要不断地演化到标准类型,从而实现知识的复用,以及与更多其他领域的数据进行连接。因此,我们提出了一种语义增强的属性图模型,它是结合了LPG和RDF优势的混合模型,更适合业务数据到知识标准化的演化过程。它提供业务易理解的表达,更利于知识复用,可规模化落地。这种语义增强的属性图模型,有一些语义约束的范式。我们参考了OWL的表达方式,大概分成如下几类:
- 逻辑推演。包括symmetric(spouse),transitive(located_in)等。以可传递性为例,比如说某个人位于成都市,那他一定位于四川省。
- 数据完整性约束。包括mutexOf等。以互斥类型为例,如果两个人是兄弟关系,就一定不是父子关系。
- 属性类型约束。语义增强的属性图模型,它支持int、string这些基础属性类型,也支持City等标准类型。区别于String类型,标准类型可枚举,支持实体间可传播计算,基础类型演化到标准类型,即可实现属性图到语义图内置转换。
- 实体衍生/链指。包括subClassOf、equivalent、fuse等,主要是知识复用的约束范式。
03
语义知识管理关键技术及应用接下来重点介绍语义知识管理的底层关键技术和在业务上的应用。
1.语义知识管理核心能力
![]() 语义知识管理的核心能力分成以下几个部分:
语义知识管理的核心能力分成以下几个部分:
- 语义增强。主要是结合语义知识的表示,提供语义增强的能力。
- 知识演化。是实现业务数据到知识标准化的过程,包括图谱Schema及其绑定算子的增、删、改,比如把属性类型从string等基础类型变更为Brand等可枚举标准语义类型。
- 跨域融合。在金融业务场景通常会面临多领域的图谱构建,领域和领域之间的数据要互通,实现业务价值增益。
- 推理预构图。是在应用端通过分布式推理实现计算的加速。整个知识的管理,底层以语义图layout方式表示,上层对接图计算引擎提高推理的效率。
- 多场景构建。对于事件、概念、实体及关系,不同场景有不同更新频率,需要支持多种场景下实时和批量知识更新的需求。
2. 基于DFS的知识管理架构
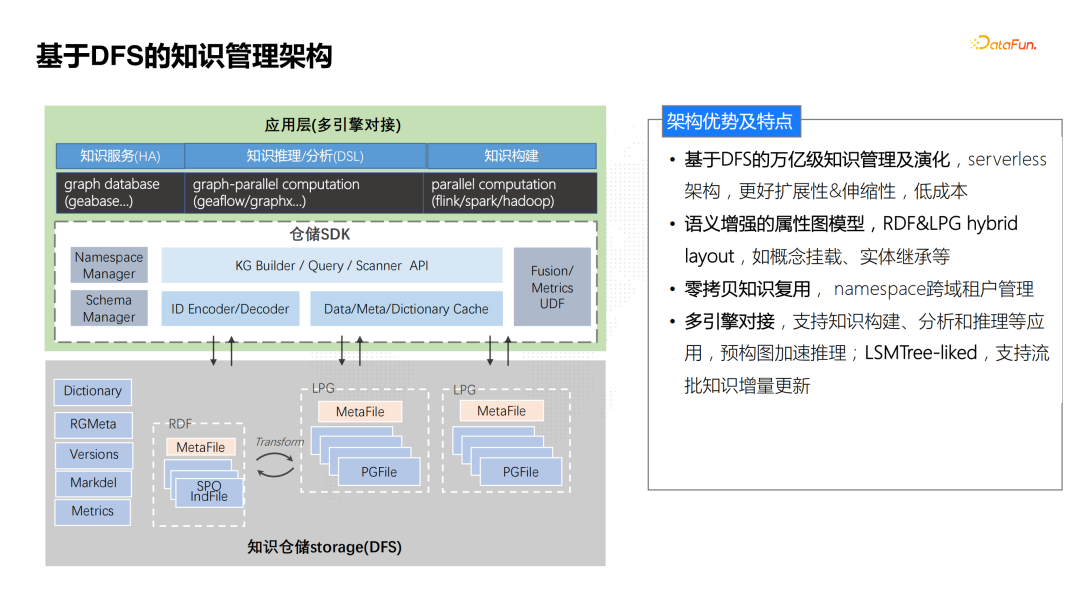
![]() 我们整个知识图谱的知识管理架构分成两层,下层为存储层,基于DFS(分布式文件系统)实现全量知识的管理。上层为应用层,通过SDK对接到图数据库、图计算等引擎,支持知识服务、知识推理分析以及知识构建等应用。这种架构的优势和特点为:
我们整个知识图谱的知识管理架构分成两层,下层为存储层,基于DFS(分布式文件系统)实现全量知识的管理。上层为应用层,通过SDK对接到图数据库、图计算等引擎,支持知识服务、知识推理分析以及知识构建等应用。这种架构的优势和特点为:
- 基于DFS的万亿级知识管理及演化。采用存算分离架构具有更好的扩展性和伸缩性,知识演化效率高,成本也比较低。
- 语义增强的属性图模型。底层支持RDF和属性图混合模型,实现了概念挂载、实体继承等语义图能力扩展。
- 零拷贝知识复用。底层根据不同的领域数据按照name space管理,实现了多租户数据的隔离管理,以及零拷贝的知识复用。
- 多引擎对接。上层通过多引擎对接,支持知识构建、分析和推理等不同的应用;通过预构图加速推理;支持流批知识增量更新等。
3. 语义知识生产及算子演化
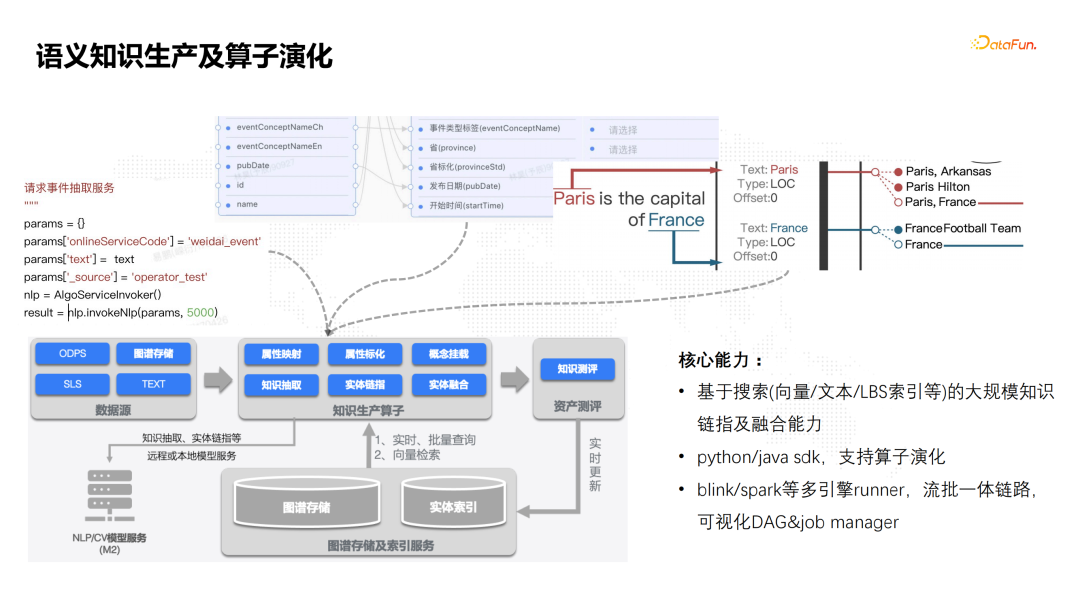
![]() 下面介绍知识生产的过程。一般的,知识图谱的知识生产过程包括知识抽取、属性标准化、实体链指及融合等几个关键部分。语义知识生产链路提供的核心能力包括:
下面介绍知识生产的过程。一般的,知识图谱的知识生产过程包括知识抽取、属性标准化、实体链指及融合等几个关键部分。语义知识生产链路提供的核心能力包括:
- 基于搜索(向量/文本/LBS索引等)实现大规模的实体链指和融合能力。这里面会用到向量、文本或者LBS的索引能力。举一个例子,线下支付场景一般存在一个商户有多个店铺、一店多码这种情况,识别商户同店,就需要用到向量或者LBS索引。
- 知识生产过程支持用户通过Python/Java SDK自助研发pipeline,并支持算子版本演化。比如事件抽取服务是通过Python SDK去调用NLP服务实现知识的抽取。
- 知识生产链路可适配到blink、spark等通用流批计算引擎,来支持多云部署。目前完成在蚂蚁内部blink适配,以及中信spark等私有云环境适配。 接下来以事理图谱构建为例,介绍语义知识生产过程。
4. 案例:事理图谱构建
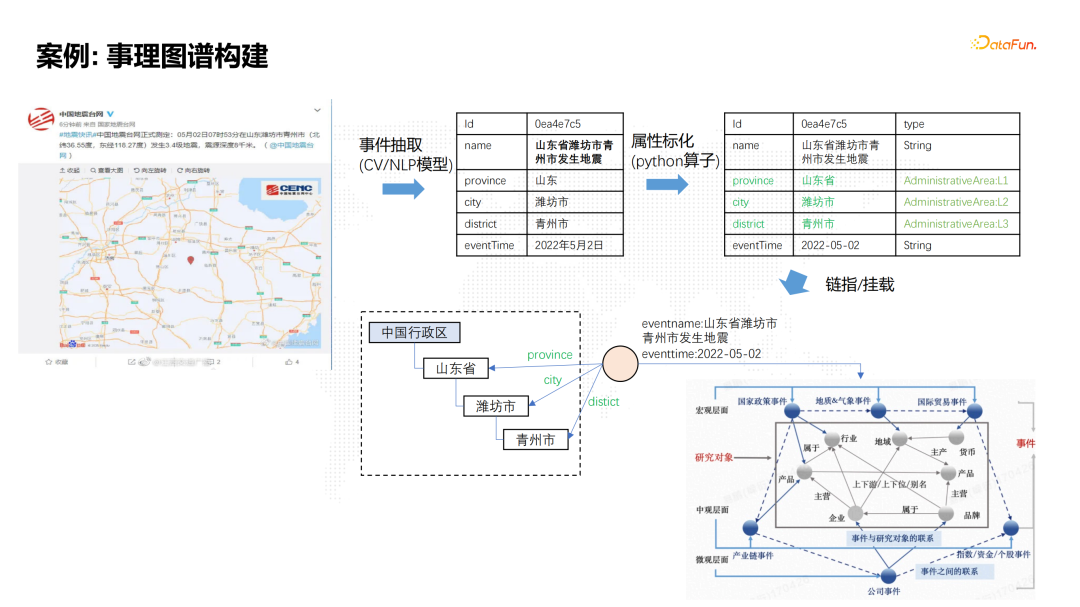
![]() 首先我们从中国地震台网发布的一则地震新闻信息,通过NLP模型进行事件抽取,抽取得到地震事件发生的地理位置和时间等关键要素。通过属性的标准化,可以把地震事件的地理位置标准化,归属到相应的省市区,然后和中国行政区的标准概念网络进行关联。同时,这个事件也会归属到事件分类的概念网络里面,比如它属于这个地域的事件,或者是气象的事件。这样的好处就是通过这个地震事件,关联到周边的一些房地产企业,地震事件对它们的经营产生影响,从而有利于支撑我们对这些企业进行风险评估。
首先我们从中国地震台网发布的一则地震新闻信息,通过NLP模型进行事件抽取,抽取得到地震事件发生的地理位置和时间等关键要素。通过属性的标准化,可以把地震事件的地理位置标准化,归属到相应的省市区,然后和中国行政区的标准概念网络进行关联。同时,这个事件也会归属到事件分类的概念网络里面,比如它属于这个地域的事件,或者是气象的事件。这样的好处就是通过这个地震事件,关联到周边的一些房地产企业,地震事件对它们的经营产生影响,从而有利于支撑我们对这些企业进行风险评估。
5. 语义增强模型实现
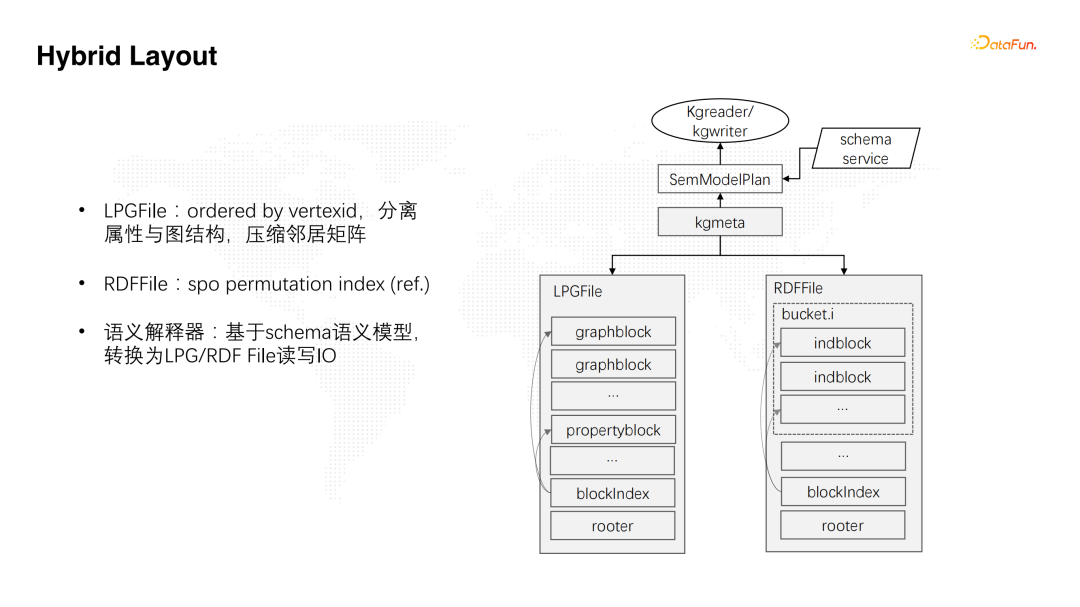
![]() 下面介绍如何基于hybrid layout实现语义增强模型。首先,底层有两种类型的layout,一种就是LPG,通过属性和图结构的表示方式实现。另一种是RDF,主要通过SPO三元组索引实现,这也是典型RDF存储的实现方案。其次,上层通过语义解释器和schema语义模型联动,把对图谱的读写流程转化为底层针对两种不同layout的读写IO。
下面介绍如何基于hybrid layout实现语义增强模型。首先,底层有两种类型的layout,一种就是LPG,通过属性和图结构的表示方式实现。另一种是RDF,主要通过SPO三元组索引实现,这也是典型RDF存储的实现方案。其次,上层通过语义解释器和schema语义模型联动,把对图谱的读写流程转化为底层针对两种不同layout的读写IO。
6. 概念模型实现
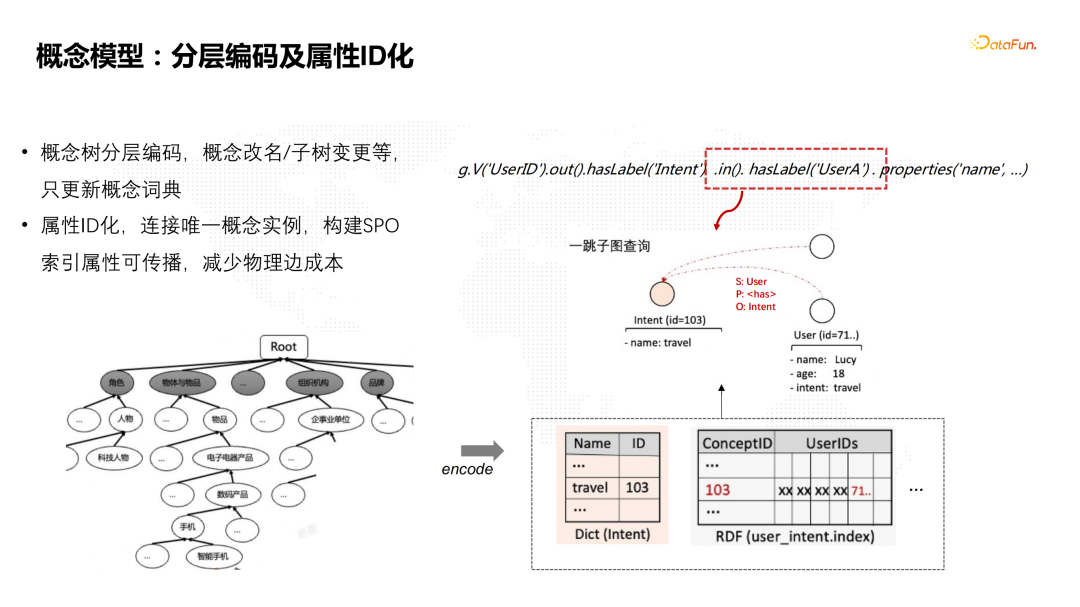
![]() 概念模型是一个树状的分类分层体系,我们对概念树进行分层编码,形成概念词典。这样的好处是在概念改名时,只需要更新概念词典信息,而不需要更新索引或者关系的数据。因为和一般的概念关联的实体非常多,概念一变就涉及整个树的变更,变更量非常大,用概念词典就能很好的解决这个问题。另外,属性的ID化能够让实体的属性连接到唯一的概念实例,通过构建RDF的SPO索引实现属性到实体到概念的正反向传播。这样的好处是减少了大量的概念到实体之间的物理边的维护成本。
概念模型是一个树状的分类分层体系,我们对概念树进行分层编码,形成概念词典。这样的好处是在概念改名时,只需要更新概念词典信息,而不需要更新索引或者关系的数据。因为和一般的概念关联的实体非常多,概念一变就涉及整个树的变更,变更量非常大,用概念词典就能很好的解决这个问题。另外,属性的ID化能够让实体的属性连接到唯一的概念实例,通过构建RDF的SPO索引实现属性到实体到概念的正反向传播。这样的好处是减少了大量的概念到实体之间的物理边的维护成本。
7. 事件模型实现
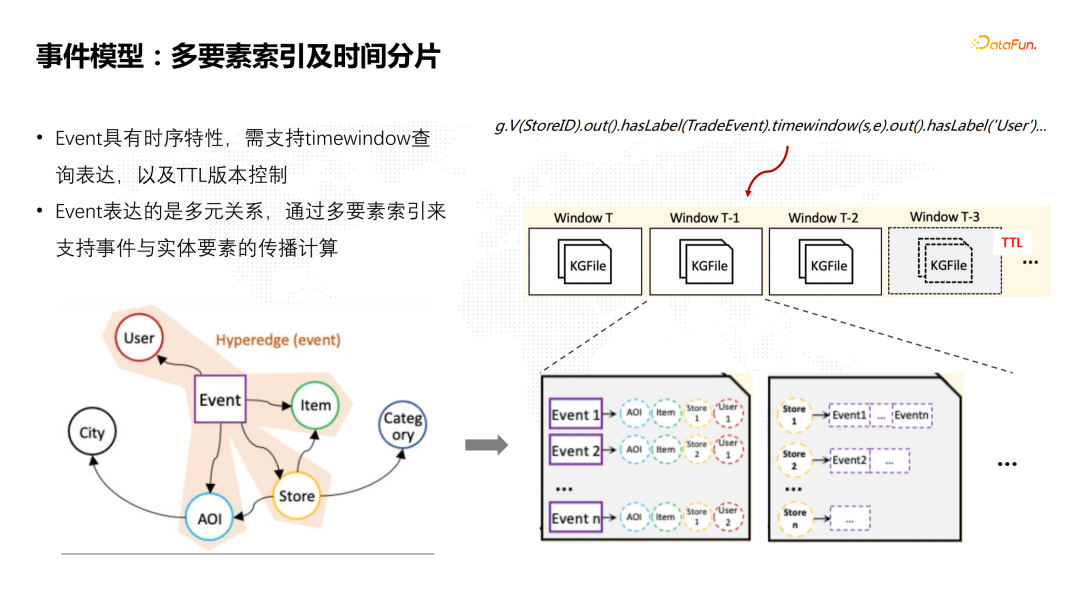
![]() 事件模型的实现有两个比较关键的要求:一是事件具有时序特性,一般需要支持时间窗口查询表达,以及TTL版本控制能力。比如通过时间的分片,把所有数据按时间切割成不同的分片,从而提升构建或者推理的效率。二是事件表达的是多元的关系,需要通过多要素索引支持事件与实体要素的传播计算。比如线下购买事件,通常会关联到一个用户、一个商品,也会关联到一个商店和它的地理位置信息。这和传统的pairwise二元关系还是有区别的。为了实现事件到实体要素之间的传播,我们需要构建它的多维索引,包括事件关联的实体要素索引,以及实体要素到事件的索引。
事件模型的实现有两个比较关键的要求:一是事件具有时序特性,一般需要支持时间窗口查询表达,以及TTL版本控制能力。比如通过时间的分片,把所有数据按时间切割成不同的分片,从而提升构建或者推理的效率。二是事件表达的是多元的关系,需要通过多要素索引支持事件与实体要素的传播计算。比如线下购买事件,通常会关联到一个用户、一个商品,也会关联到一个商店和它的地理位置信息。这和传统的pairwise二元关系还是有区别的。为了实现事件到实体要素之间的传播,我们需要构建它的多维索引,包括事件关联的实体要素索引,以及实体要素到事件的索引。
8. 基于事件模型构建资金图谱案例
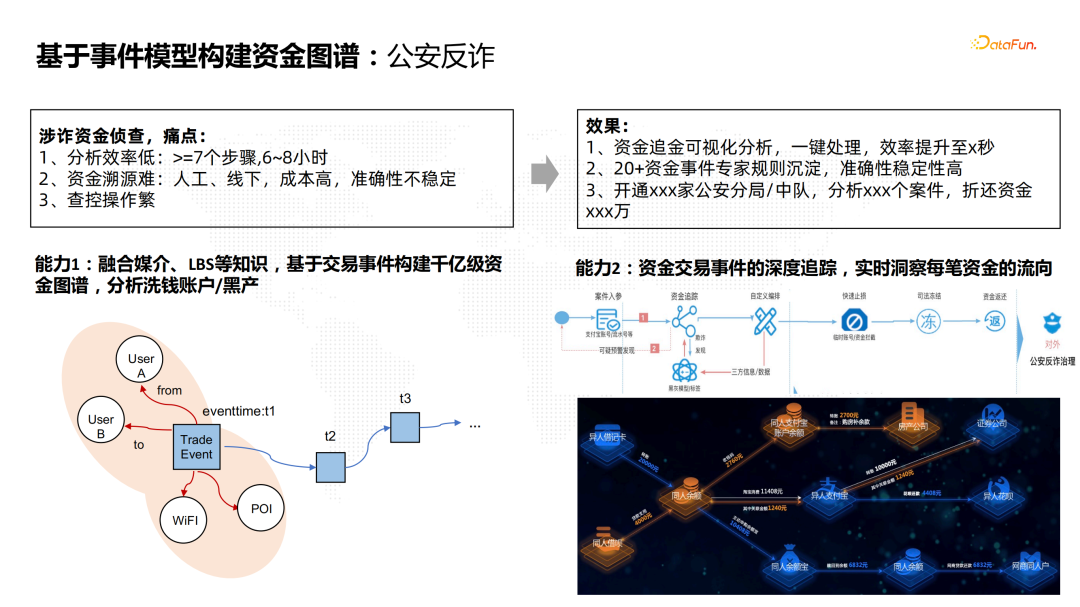
![]() 接下来我们通过蚂蚁资金图谱的一个例子介绍如何通过事件模型构建图谱。蚂蚁资金图谱构建的背景是公安反诈。公安部门接到一笔资金报案之后,需要查看资金的流向,判断资金流向涉及的个人信息。资金溯源的过程牵扯到很多人工线下操作,查控操作繁琐,通常要耗费好几个小时,分析成本很高。我们提供了两个能力来解决这个问题。一是通过事件模型把千亿级的资金交易事件,与交易发生的WIFI和地理位置等信息融合,来构建蚂蚁资金图谱,把交易事件、设备和时空的信息关联起来,更便于分析洗钱的账户及黑产信息,辅助公安部门侦查。二是基于大规模资金交易事件进行资金的深度追踪,结合沉淀的大量资金事件专家规则,能够实时洞察每一笔资金的流向,提升案件侦查的效率。资金图谱支持资金追踪的可视化分析、一键处理,大幅提升了侦查效率,目前在多个省市的几十家公安部门中试用,冻结折还的资金已经达到了数百万。
接下来我们通过蚂蚁资金图谱的一个例子介绍如何通过事件模型构建图谱。蚂蚁资金图谱构建的背景是公安反诈。公安部门接到一笔资金报案之后,需要查看资金的流向,判断资金流向涉及的个人信息。资金溯源的过程牵扯到很多人工线下操作,查控操作繁琐,通常要耗费好几个小时,分析成本很高。我们提供了两个能力来解决这个问题。一是通过事件模型把千亿级的资金交易事件,与交易发生的WIFI和地理位置等信息融合,来构建蚂蚁资金图谱,把交易事件、设备和时空的信息关联起来,更便于分析洗钱的账户及黑产信息,辅助公安部门侦查。二是基于大规模资金交易事件进行资金的深度追踪,结合沉淀的大量资金事件专家规则,能够实时洞察每一笔资金的流向,提升案件侦查的效率。资金图谱支持资金追踪的可视化分析、一键处理,大幅提升了侦查效率,目前在多个省市的几十家公安部门中试用,冻结折还的资金已经达到了数百万。
9. 分布式推理构图实现
![]() 分布式知识推理过程基于图计算引擎实现,整个推理的流程包括构图和图迭代两个部分。我们采用图表示的存储模型,能更高效对接GeaFlow等图计算引擎,实现无shuffle构图,提升推理效率。测试表明,我们现在的这种知识管理方案,比以前直接基于table的关系模型,实现了构图效率的大幅提升。后续我们也会和TuGraph团队合作,更好地实现引擎衔接,做到无序列化推理构图。另外我们也在探索局部性友好的知识编码,提升图迭代效率。
分布式知识推理过程基于图计算引擎实现,整个推理的流程包括构图和图迭代两个部分。我们采用图表示的存储模型,能更高效对接GeaFlow等图计算引擎,实现无shuffle构图,提升推理效率。测试表明,我们现在的这种知识管理方案,比以前直接基于table的关系模型,实现了构图效率的大幅提升。后续我们也会和TuGraph团队合作,更好地实现引擎衔接,做到无序列化推理构图。另外我们也在探索局部性友好的知识编码,提升图迭代效率。
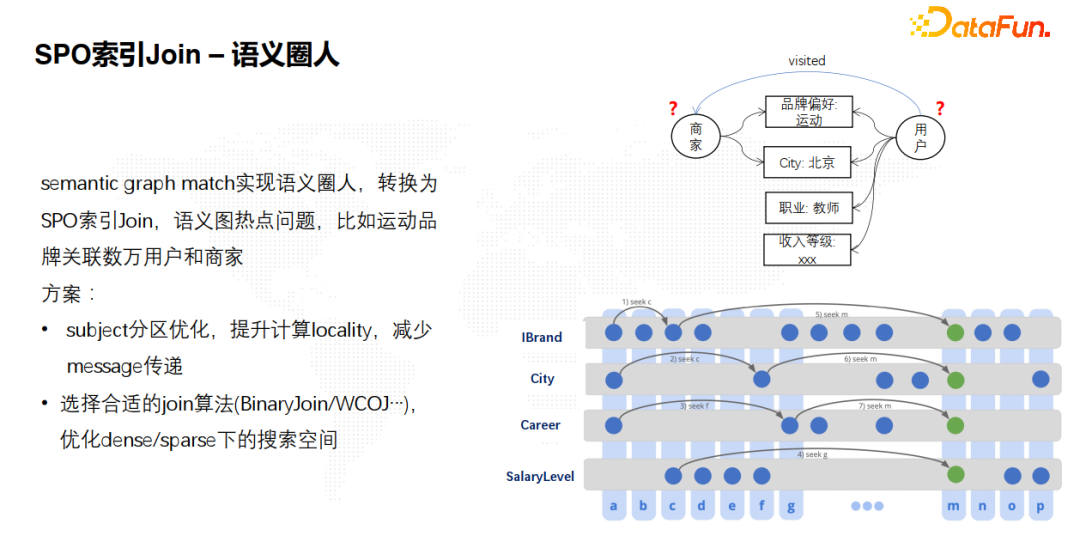
10. SPO索引:语义圈人
![]() 语义图推理一个比较重要的场景是语义圈人,特别是营销推荐。语义图推理本质上是一个子图匹配的过程,如图所示。比如我们圈选一些商家,通过品牌偏好、城市、职业和收入等级去圈选需要投放的营销用户群体。这可以转化为RDF SPO索引的join问题。面临的技术难点是,这个语意图热点问题非常突出。比如一个运动的品牌或者一个城市,它关联的用户和商家非常多。我们提出了两个解决方案。一是在分布式的计算场景上实现subject分区优化,提升计算的局部性,减少消息的传递。二是在多条件情况下选择合适的join算法(如BinaryJoin、WCOJ等),优化dense/sparse下的搜索空间。
语义图推理一个比较重要的场景是语义圈人,特别是营销推荐。语义图推理本质上是一个子图匹配的过程,如图所示。比如我们圈选一些商家,通过品牌偏好、城市、职业和收入等级去圈选需要投放的营销用户群体。这可以转化为RDF SPO索引的join问题。面临的技术难点是,这个语意图热点问题非常突出。比如一个运动的品牌或者一个城市,它关联的用户和商家非常多。我们提出了两个解决方案。一是在分布式的计算场景上实现subject分区优化,提升计算的局部性,减少消息的传递。二是在多条件情况下选择合适的join算法(如BinaryJoin、WCOJ等),优化dense/sparse下的搜索空间。
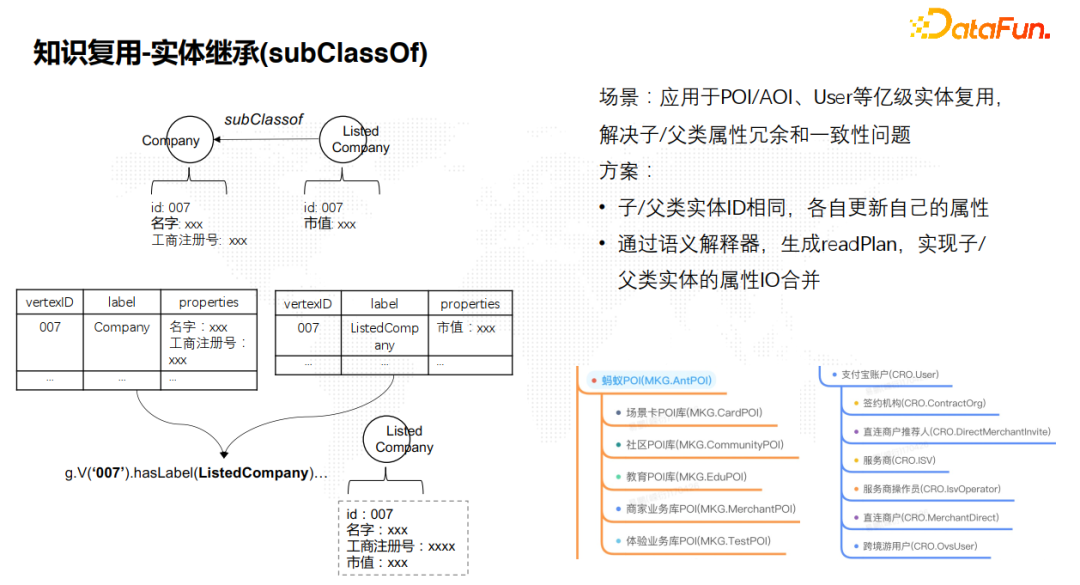
11. 知识复用-实体继承
![]() 实体继承是语义知识复用的一个非常典型的场景。在蚂蚁的内部场景中,我们的POI/AOI,支付宝用户等亿级别的实体复用,已经用到了实体继承。实体继承类似面向对象的继承概念,比如一个公司实体,它有一些通用属性。而在这个公司上面还有上市公司,上市公司会有市值等特有属性信息。实体继承就是要解决子父类属性的冗余和一致性问题,即通过一种方案,使得查询或者推理在获取子类属性的时候,能够动态拼接父类的属性。我们的解决方案首先是子类和父类实体的ID相同,各自属性保持独立更新和互为索引。然后在读取端通过语义解释器,生成readPlan,实现子父类实体的属性动态IO合并。
实体继承是语义知识复用的一个非常典型的场景。在蚂蚁的内部场景中,我们的POI/AOI,支付宝用户等亿级别的实体复用,已经用到了实体继承。实体继承类似面向对象的继承概念,比如一个公司实体,它有一些通用属性。而在这个公司上面还有上市公司,上市公司会有市值等特有属性信息。实体继承就是要解决子父类属性的冗余和一致性问题,即通过一种方案,使得查询或者推理在获取子类属性的时候,能够动态拼接父类的属性。我们的解决方案首先是子类和父类实体的ID相同,各自属性保持独立更新和互为索引。然后在读取端通过语义解释器,生成readPlan,实现子父类实体的属性动态IO合并。
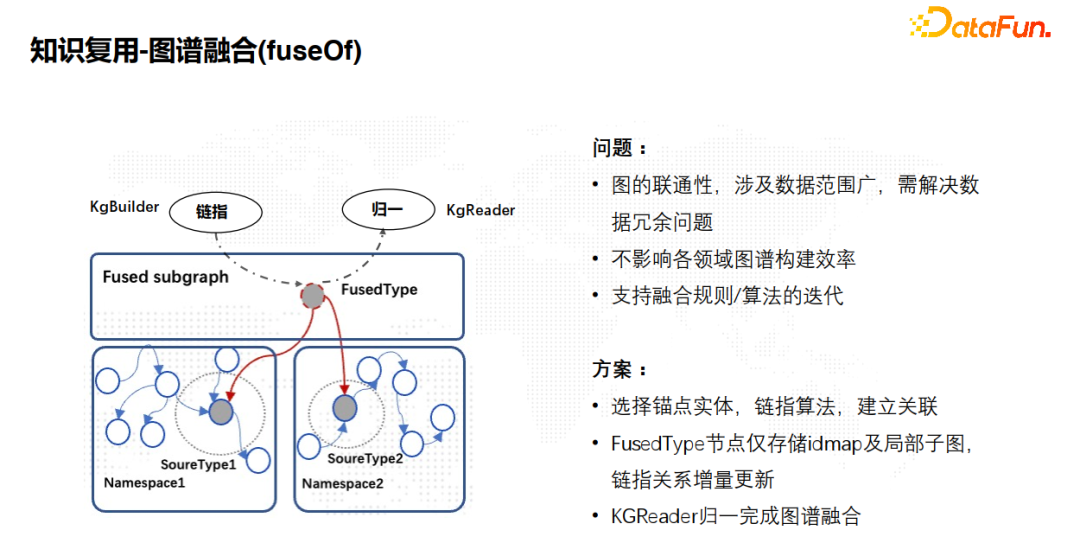
12. 知识复用-图谱融合
![]() 图谱融合是知识管理的一个难点,也是非常重要的业务场景。图谱融合简单来说就是把两个领域的图谱通过某种方式融合到一起,实现两个领域的图谱互通,解决数据孤岛问题。由于图本身的连通性,实现两个图谱融合,涉及的数据范围非常广,所以首先要解决数据冗余的问题。我们把图谱融合分成两个阶段,第一个阶段叫做链指,第二个阶段叫做归一。链指是指在两个不同的领域图谱里面选择一个锚点实体,通过链指算法建立这个锚点实体的关联。归一是指对这个锚点实体对应的子图信息进行合并的过程。如果把归一的过程放在构建端,每一次锚点实体的更新,都会触发图数据的归并,这个成本非常高。因为一个点关联的周边关系或者一度子图,可能是非常庞大的。所以我们在构建融合实体的时候,都是把它作为一个虚拟的实体存在,仅存储链指的idmap和它的局部子图信息。更重要是融合算法或者规则发生更新的时候,链指关系的变化只会触发增量更新,更好地适应算法的迭代。
图谱融合是知识管理的一个难点,也是非常重要的业务场景。图谱融合简单来说就是把两个领域的图谱通过某种方式融合到一起,实现两个领域的图谱互通,解决数据孤岛问题。由于图本身的连通性,实现两个图谱融合,涉及的数据范围非常广,所以首先要解决数据冗余的问题。我们把图谱融合分成两个阶段,第一个阶段叫做链指,第二个阶段叫做归一。链指是指在两个不同的领域图谱里面选择一个锚点实体,通过链指算法建立这个锚点实体的关联。归一是指对这个锚点实体对应的子图信息进行合并的过程。如果把归一的过程放在构建端,每一次锚点实体的更新,都会触发图数据的归并,这个成本非常高。因为一个点关联的周边关系或者一度子图,可能是非常庞大的。所以我们在构建融合实体的时候,都是把它作为一个虚拟的实体存在,仅存储链指的idmap和它的局部子图信息。更重要是融合算法或者规则发生更新的时候,链指关系的变化只会触发增量更新,更好地适应算法的迭代。
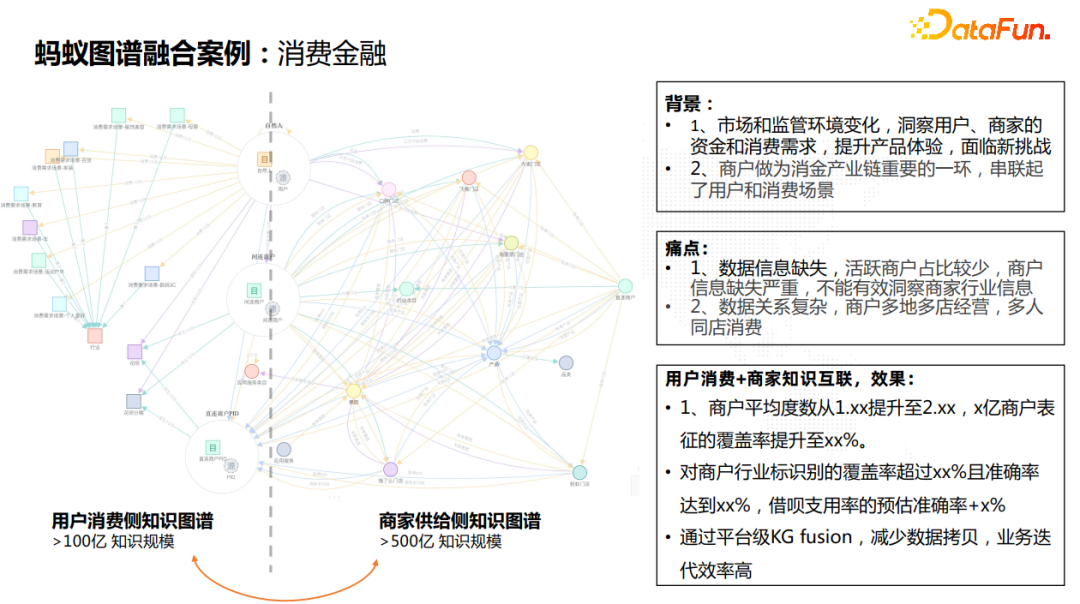
13. 蚂蚁图谱融合案例:金融消费
![]() 我们举一个金融消费的例子解释蚂蚁知识图谱的融合场景。在这个例子里,我们有两个不同领域的图谱,一个是用户消费侧的知识图谱,另一个是商家供给侧的知识图谱,两个都是数百亿的知识图谱。消费侧知识图谱关注消费的场景信息,供给侧知识图谱关注的是商家的品牌、类目、门店以及地理位置等信息。通过把用户或者商户作为锚点实体就可以建立两个图谱之间的零拷贝关联。商户作为消费金融产业链重要的一环,串联起了用户和消费场景。通过关联,这样围绕商户的关系就更加丰富,表征能力更强,提升了商户的画像刻画能力。
我们举一个金融消费的例子解释蚂蚁知识图谱的融合场景。在这个例子里,我们有两个不同领域的图谱,一个是用户消费侧的知识图谱,另一个是商家供给侧的知识图谱,两个都是数百亿的知识图谱。消费侧知识图谱关注消费的场景信息,供给侧知识图谱关注的是商家的品牌、类目、门店以及地理位置等信息。通过把用户或者商户作为锚点实体就可以建立两个图谱之间的零拷贝关联。商户作为消费金融产业链重要的一环,串联起了用户和消费场景。通过关联,这样围绕商户的关系就更加丰富,表征能力更强,提升了商户的画像刻画能力。
04
展望我们对大规模语义知识管理的未来展望,一个是面向DataFabric的企业级知识管理平台,另一个是跨领域知识共享与应用。
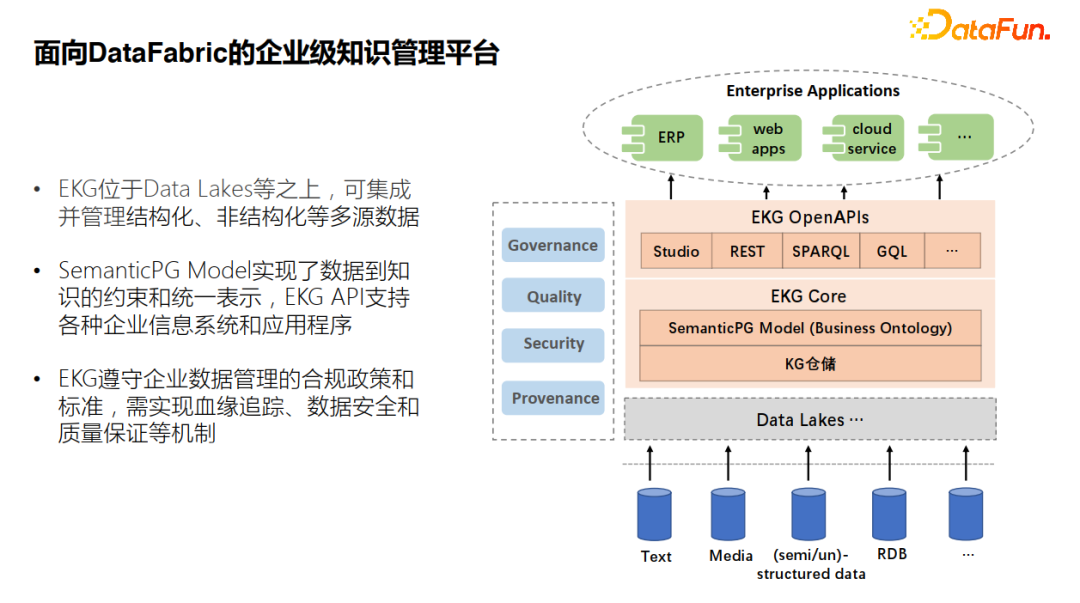
1.面向DataFabric的企业级知识管理平台我们的目标是建设面向DataFabric的企业级知识管理平台,主要方向包括: ![]()
- 知识图谱的数据管理平台,位于数据湖或者数据仓储之上,它可以集成并管理结构化、非结构化等多源数据。
- 通过语义增强模型实现数据到知识的约束和统一表示。同时,通过开放的API,支持不同的企业应用场景。
- 在知识管理过程中,需要遵循企业数据管理标准,实现血缘追踪、数据安全和质量保证等机制。
2. 跨领域知识共享与应用
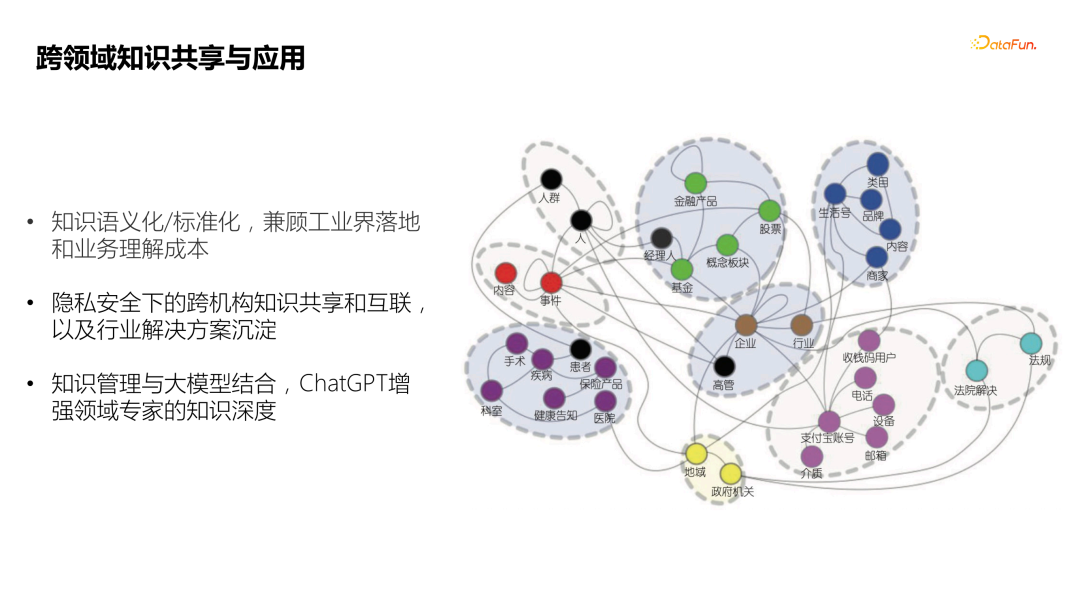
![]() 我们的最终目标是实现跨领域的知识共享和应用,主要方向包括:
我们的最终目标是实现跨领域的知识共享和应用,主要方向包括:
- 推进知识语义化、标准化,兼顾工业界落地和业务的理解成本。
- 在实现跨机构、跨主体的知识互联的时候,需要更多的考虑隐私计算。另外就是沉淀行业解决方案,辅助更多的机构应用知识图谱。
- 知识管理和大模型结合,例如利用高质量知识图谱,提升大模型在推理上准确率和专业性,增强大模型的在金融等特定领域的知识深度。 05
Q&A
**Q1:知识管理平台底层有属性图和RDF图,两者是相对独立的存储,那他们是怎么融合的?在查询引擎上是用哪种方式融合的?**A:我们知识管理平台提供语义增强的图谱schema和底层仓储SDK,包括build、query、scan等构建和读取图谱的API或tool。这些API里面植入了一些语义和我们的语义模型去联动,通过语义解释器实现底层的RDF或者是LPG文件的读取IO。上层和GeaFlow图计算引擎衔接,它调用query或scan等SDK实现对图谱语义数据的加载,这些SDK的输出会转换成图计算引擎能识别的属性图。 **Q2:归一的结果是将不同领域的同一实体在融合图中形成了同一个主键吗?**A:归一是将两个实体的图结构合并为一个实体图结构的过程,包括属性和关系的合并和冲突解决。两个图结构分别维护不同领域的数据,最后在应用的时候,用户看到的是一个新的实体类型,我们把它叫做融合实体,融合实体在读取时按需做图结构合并,解决了存储冗余的问题。 **Q3:知识管理平台融合了很多的引擎,比如GeaFlow、GeaBase、Flink等,现在有没有一种语言能把它们都包装起来,实际使用的时候的入口是同一个?**A:现在整个应用端分成两部分,一个叫做构建侧或者叫生产侧,另一个叫做推理侧或者服务侧。在服务侧,现在正在推进的就是通过接口统一去表达。在生产侧,因为知识的构建是一个并行计算场景,不一定是图计算场景,它通过一个流水线SDK去表示。这个流水线SDK会植入一些算子或者组件,比如我们刚才提到的实体链指组件,然后通过执行计划的翻译,适配运行在Flink或spark等不同计算引擎上。 今天的分享就到这里,谢谢大家。
![]()
![]()
分享嘉宾 INTRODUCTION ![]()
易鹏![]()
蚂蚁集团![]()
高级技术专家
![]()
11年毕业于西安交通大学,计算机硕士,现任蚂蚁集团高级技术专家,负责蚂蚁知识图谱的构建引擎团队。之前在百度担任搜索资深研发工程师,经历了搜索数据架构的规模化和实时化演进,18年加入蚂蚁,从0到1构建了万亿级金融知识图谱的数据管理平台。