

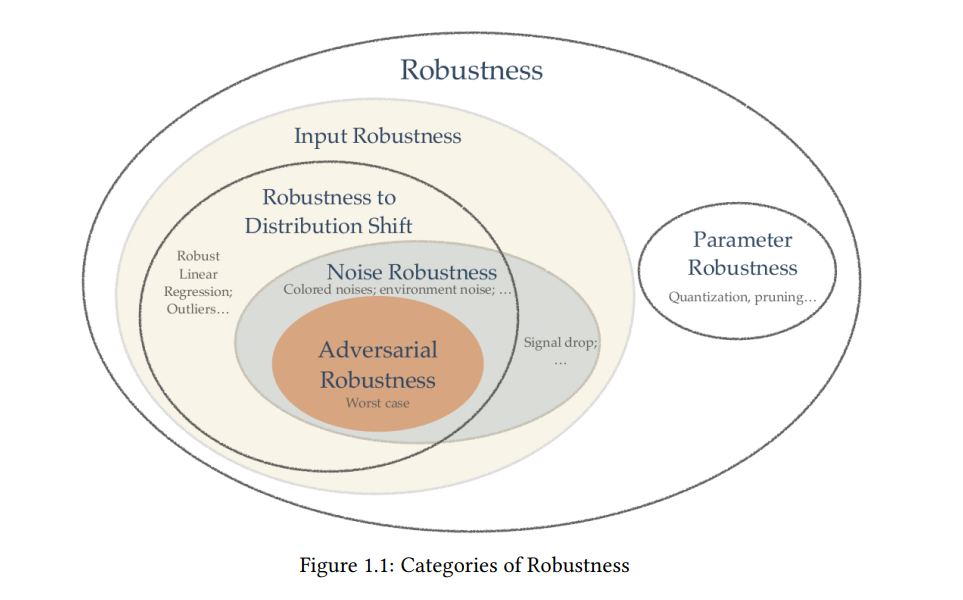
近几年,深度学习的进步极大地推动了音频视觉事件检测的发展。已经有多种模型架构被应用于多模态的这一任务,推动了性能基准的提高,并使得这些模型能够在许多关键任务中得到部署,例如监控和恶意内容过滤。但是,研究社区仍然缺乏:1) 对于与图像或文本对应的音频信号的独特性质,对不同机器学习模型行为的系统理解。2) 用于音频-视觉学习的不同模型的鲁棒性也仍然是一个尚未深入研究的领域。本论文的首要目标是探讨构建一个表现良好的仅音频和音频-视觉学习系统的最佳实践。具体来说,我们分析特征,比较不同的架构,并理解训练技术的差异,以提供全面和深入的理解。我们的调查追踪了从卷积家族到Transformer家族的模型的演变,以及从监督学习到自监督学习的学习范式的转变。(这部分在第2、3、4、5、6、7章中有详细说明)第二个目标是通过衡量每个模型在噪音和对抗性扰动下的行为来研究其鲁棒性。我们首先展示了在视觉和音频领域都存在由对抗性扰动引起的实际威胁。在此之后,我们扩大了对对抗性鲁棒性的分析范围,不仅仅是单一的音频输入,还包括了众多的模态,如音频、视频、图像和文本。(这部分内容在第8、9、10、11章中有详细说明)进一步地,我们扩展了我们的研究范围,包括了对抗性鲁棒性和噪音鲁棒性之间的比较研究(第12章)。为了在音频-视觉学习中实现泛化和鲁棒性的双重承诺,我们提出了我们的音频漫步扩散系统。我们利用扩散模型作为一个有效的数据增强工具,添加语义上多样的样本来提高性能,展示了泛化的潜力。此外,我们利用扩散模型固有的去噪能力,表明它可以轻松增强现有的音频分类系统的鲁棒性。(第13章)
成为VIP会员查看完整内容
相关内容

Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日