

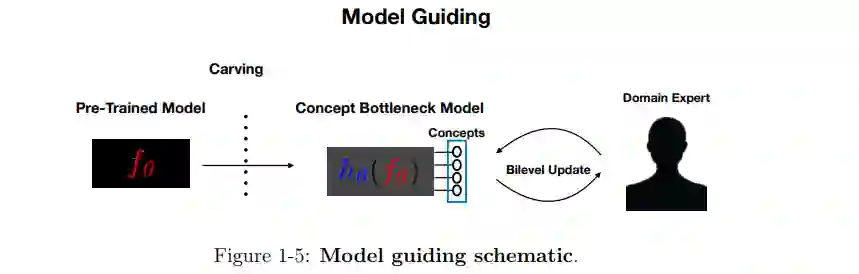
本文解决了检测和修复机器学习(ML)模型-模型调试中的错误的挑战。当前的机器学习模型,特别是在众包数据上训练的过参数化深度神经网络(DNN),很容易锁定虚假信号,在小群体中表现不佳,并可能因训练标签中的错误而偏离正轨。因此,在部署之前检测和修复模型错误的能力是至关重要的。可解释的机器学习方法,特别是事后解释,已经成为事实上的ML模型调试工具。目前存在大量的方法,但不清楚这些方法是否有效。在本文的第一部分中,我们介绍了一个框架,对标准监督学习流程中可能出现的模型错误进行分类。在分类的基础上,评估了几种事后模型解释方法对检测和修复框架中提出的缺陷类别是否有效。目前的方法很难检测模型对虚假信号的依赖,无法识别具有错误标签的训练输入,也没有提供直接的方法来修复模型错误。此外,实践者在实践中很难使用这些工具来调试ML模型。针对现有方法的局限性,在论文的第二部分,我们提出了新的模型调试工具。本文提出一种称为模型指导的方法,用一个审计集(一个由任务专家仔细注释的小型数据集)来更新预训练机器学习模型的参数。将更新表述为一个双层优化问题,要求更新的模型匹配专家在审计集上的预测和特征注释。模型引导可用于识别和纠正错误标记的示例。同样,该方法还可以消除模型对虚假训练信号的依赖。本文介绍的第二个调试工具使用估计器的影响函数来帮助识别训练点,其标签对ML模型的视差度量有很高的影响,如组校准。总之,本文在为机器学习模型提供更好的调试工具方面取得了进展。


成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2023年5月18日
Arxiv
20+阅读 · 2023年3月21日

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年5月18日
Arxiv
20+阅读 · 2023年3月21日