【CMU博士论文】视频多模态学习:探索模型和任务复杂性,152页pdf

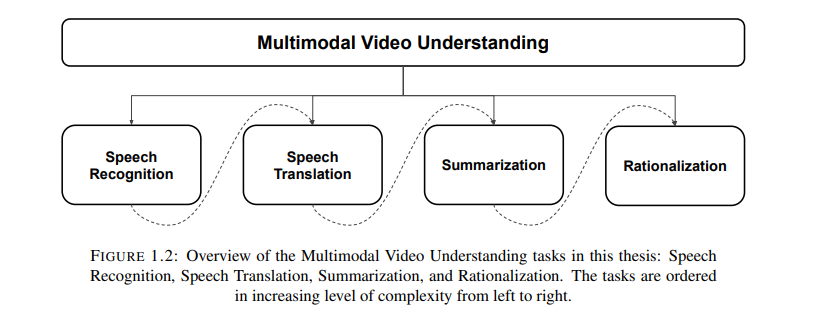
人类学习本质上是多模态的。我们通过观察、倾听、阅读和交流来学习和理解我们周围的环境。机器学习领域已经取得了一些与人类活动相关的进展,如语音识别或计算机视觉,这使得对这种类人固有的多模态学习进行计算建模成为可能。多模态视频理解作为一种机器学习任务,与这种学习形式很接近。本文提出将这个复杂的视频理解任务分解为一系列相对简单的任务,并增加复杂性。本文从语音识别的单调任务出发,介绍了一个端到端视听语音识别模型。语音翻译是一个更为复杂的任务,除了语音识别外,还需要处理重新排序的输出序列,这也是本文的第二个任务。对于语音翻译,我们引入了一个多模态融合模型,该模型学习以半监督的方式利用多视图多模态数据。此外,我们还将继续进行多模态视频摘要和问题回答的任务,以解决抽象层次的理解任务,进一步涉及信息压缩和重构。最后,我们将这项工作扩展到多模态自我理性化,不仅执行抽象层次的学习,而且还提供了对所获得的视频理解的解释。针对这四个主要任务,我们根据任务的性质和复杂性,提出了一系列多模态融合模型,并在常用的视频和语言理解数据集上对模型进行了比较和对比。
https://lti.cs.cmu.edu/sites/default/files/palaskar%2C%20shruti%20-%20Thesis.pdf

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“M152” 就可以获取《【CMU博士论文】视频多模态学习:探索模型和任务复杂性,152页pdf》专知下载链接



登录查看更多
相关内容
Arxiv
0+阅读 · 2022年11月21日
Arxiv
0+阅读 · 2022年11月19日
Arxiv
21+阅读 · 2021年5月25日




相关VIP内容
相关资讯