

通过人类反馈的强化学习
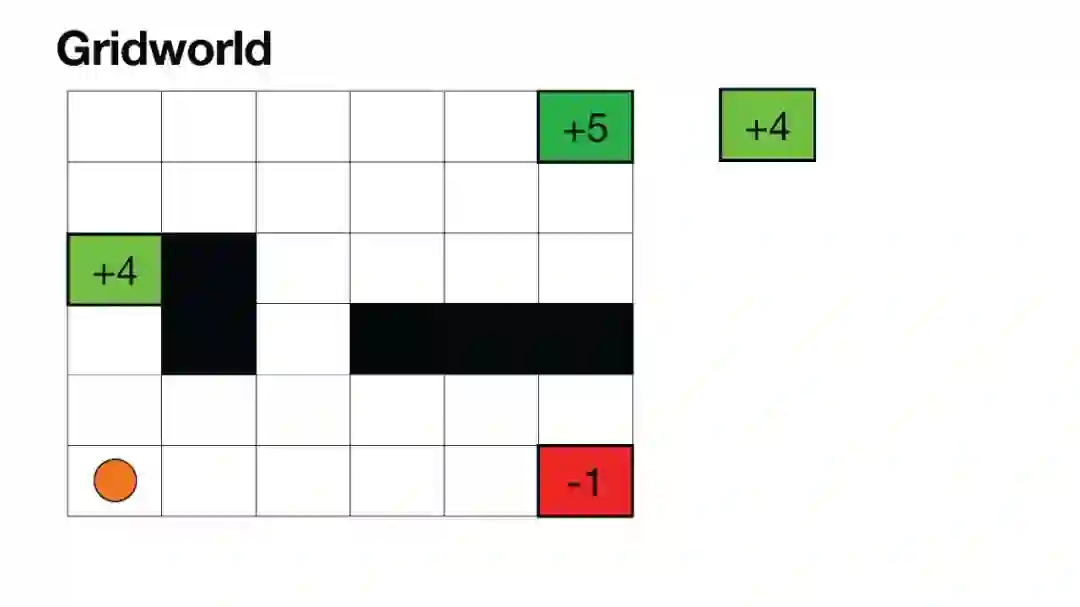
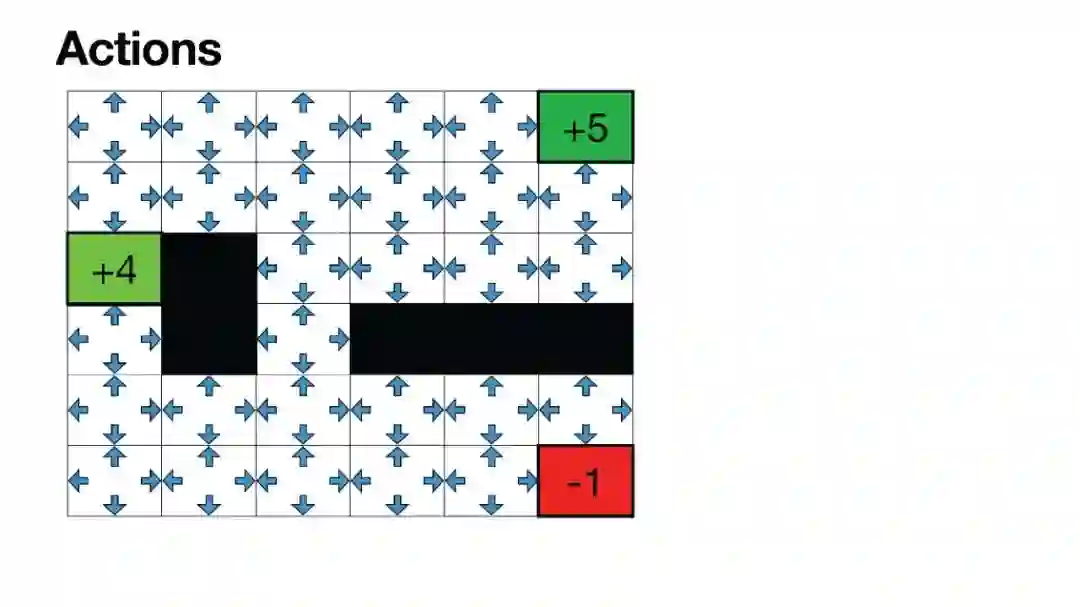
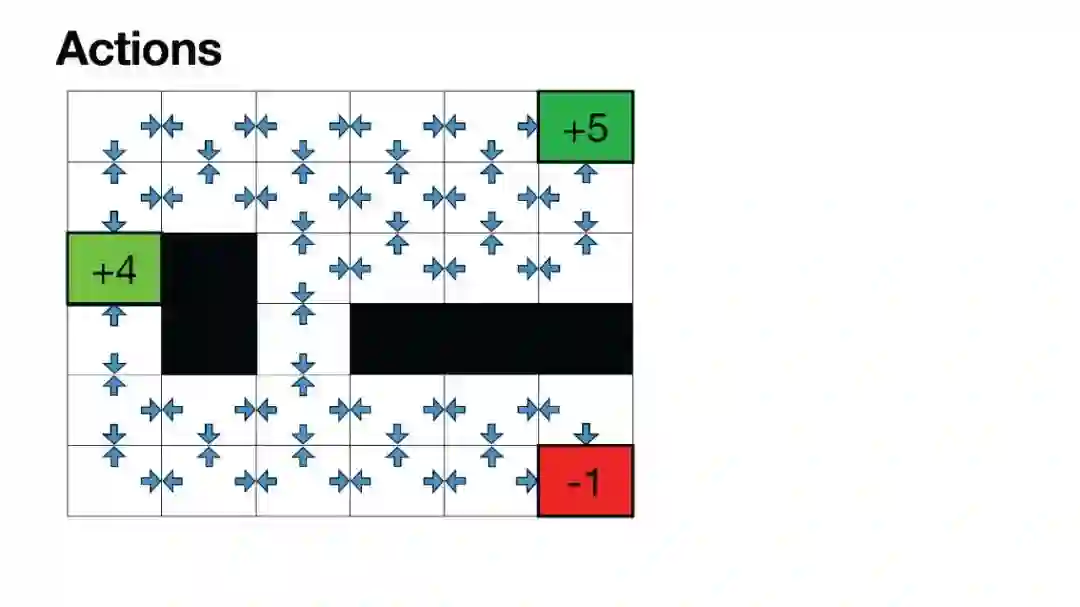
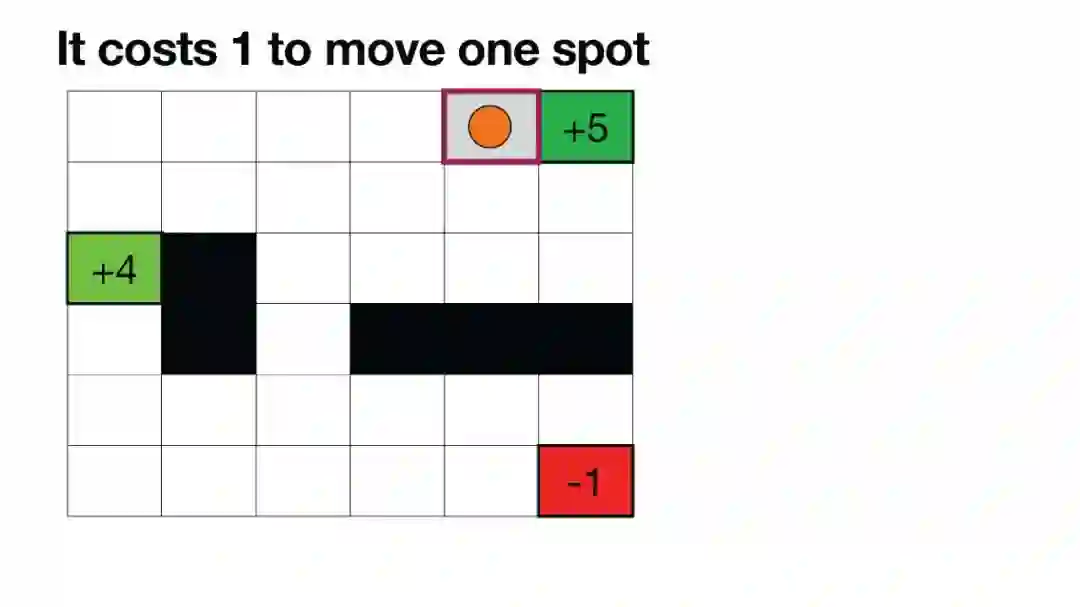
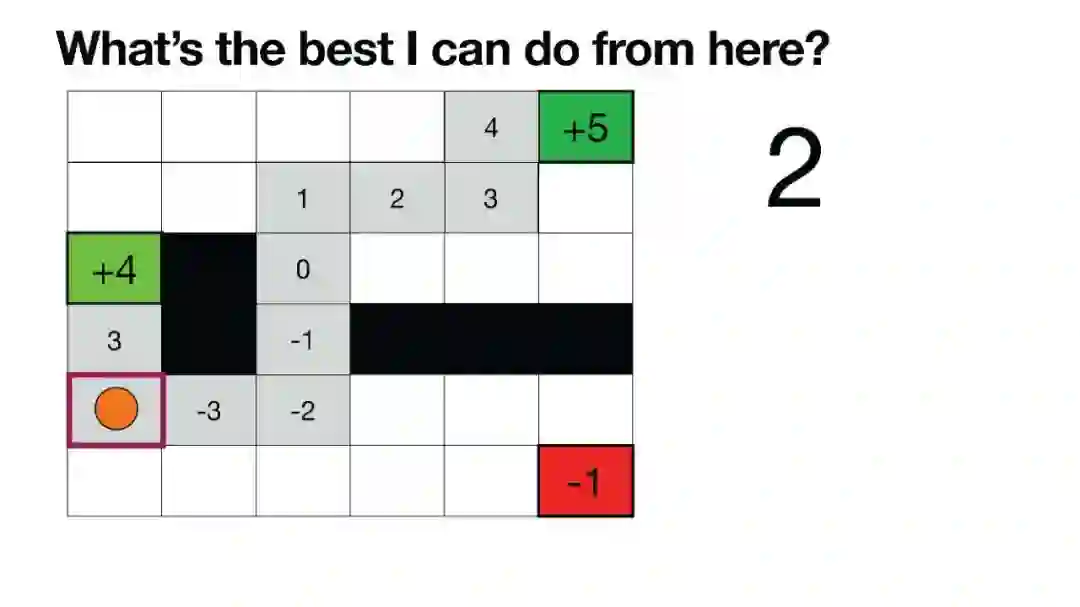
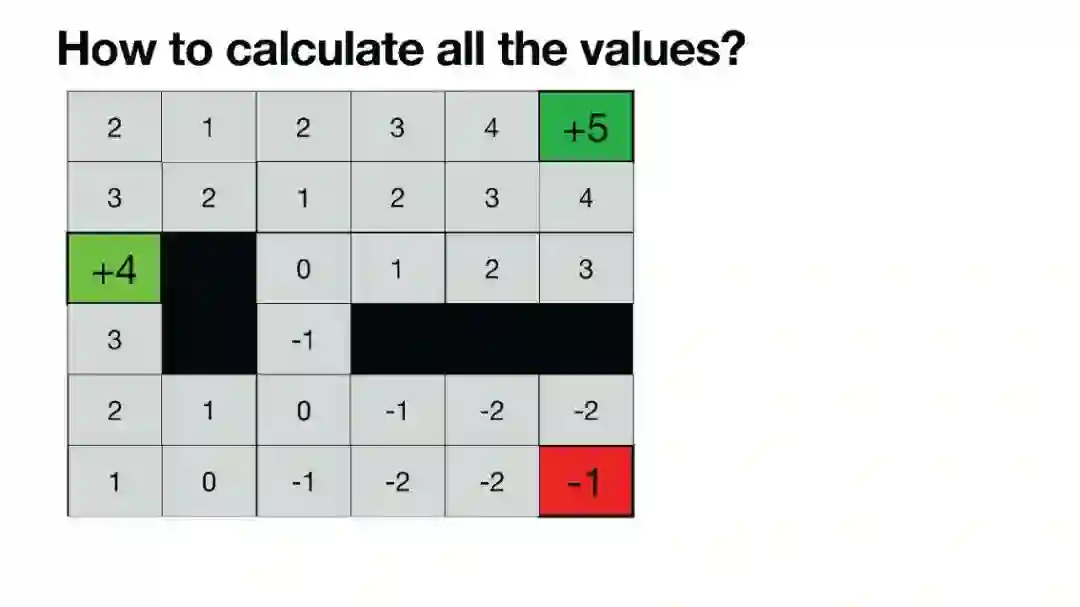
Luis Serrano, PhD | 《Grokking Machine Learning》作者,Serrano Academy创始人 | 幻灯片 虽然大型语言模型(LLMs)在生成文本方面非常成功,但微调模型仍然依赖于人类反馈,通常通过带有人类反馈的强化学习(RLHF)进行。在这些AI幻灯片中,您将探索微调中的一个非常重要的步骤,其中涉及人类对输出结果进行评估。为了通过人类反馈改进模型,RLHF是一种广泛使用的方法。




成为VIP会员查看完整内容
相关内容
相关主题

相关VIP内容
相关资讯
相关论文