

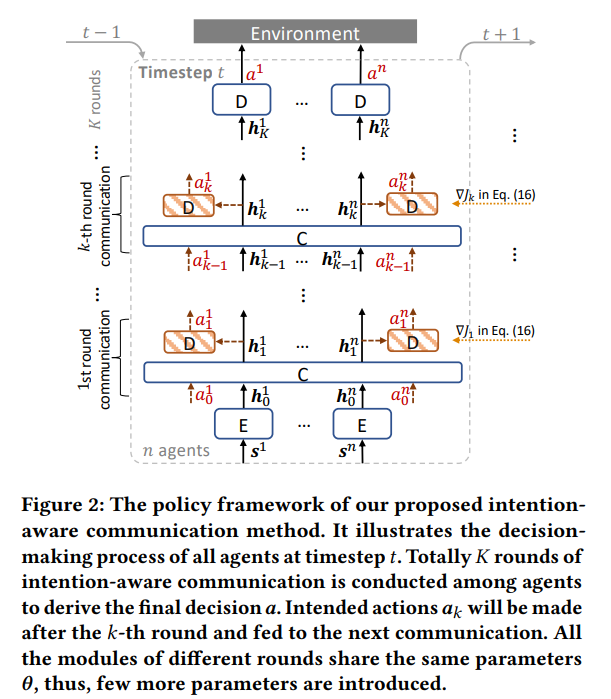
订单执行是量化金融中的一项基本任务,其目标是完成对特定资产的交易订单的购买或清算。近期在模型无关强化学习(RL)方面的进步为订单执行问题提供了一种数据驱动的解决方案。然而,现有的作品总是优化个体订单的执行,忽视了同时执行多个订单的实践,从而导致了次优和偏见。在本文中,我们首先提出了一种考虑实际限制的多订单执行的多智能体RL(MARL)方法。具体来说,我们将每个智能体视为一个独立的运营者去交易一个特定的订单,同时与彼此保持交流并合作以最大化总体利润。然而,现有的MARL算法通常通过交换其部分观察结果的信息来进行智能体之间的交流,这在复杂的金融市场中效率不高。为了改善协作,我们接着提出了一种可学习的多轮通信协议,供智能体们相互通报预定的行动并据此进行精细化处理。这通过一个新颖的动作价值归因方法来进行优化,该方法与原始学习目标一致且更有效。对两个真实市场的数据进行的实验已经表明,我们的方法实现了显著更好的协作效果,并展现了卓越的性能。
成为VIP会员查看完整内容

相关内容
Arxiv
224+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日