
本文探讨使用来自强化学习和搜索的工具来提高大型语言模型(LLM)智能体的能力和对齐性。
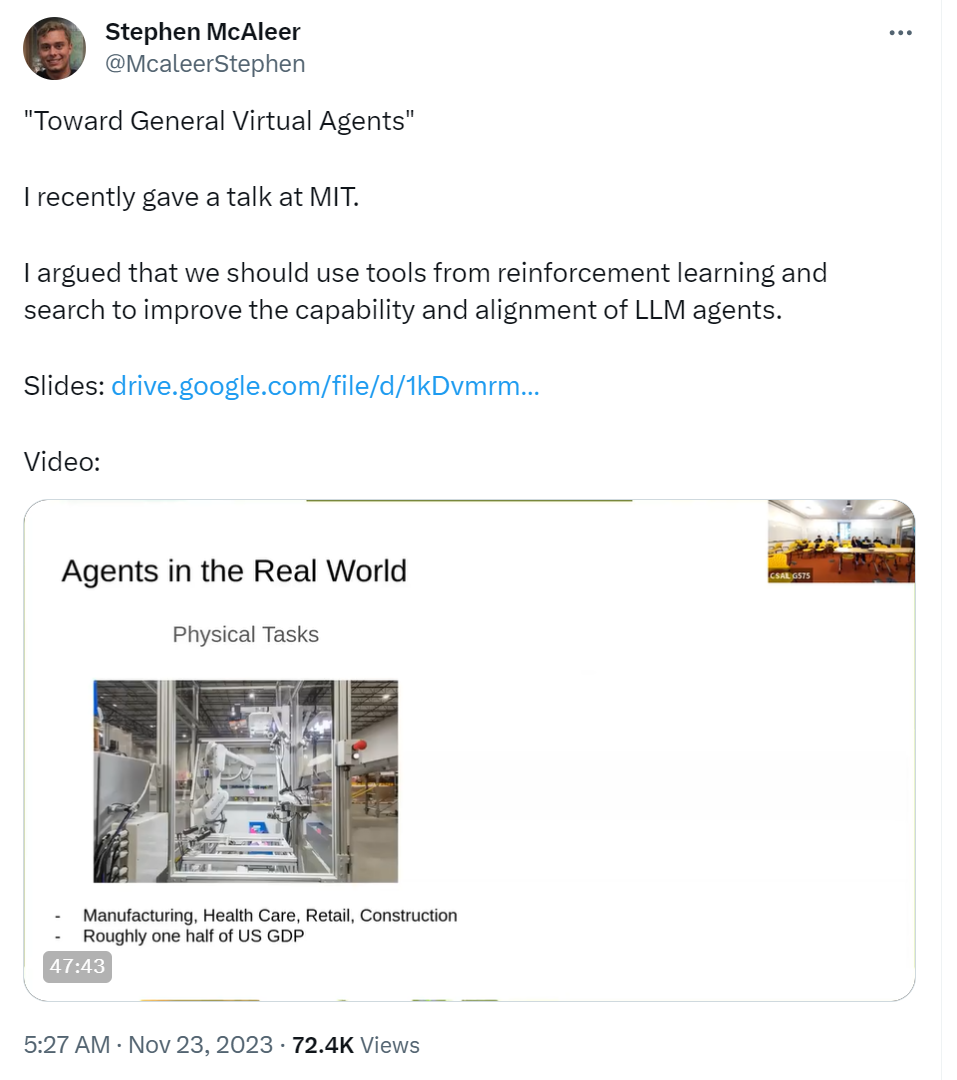
能够在计算机上执行通用任务的智能体能够极大地提高效率和生产力。理想情况下,这些智能体应该能够通过自然语言命令解决呈现给它们的新计算机任务。然而,以前解决这个问题的方法需要大量的专家演示和特定任务的奖励函数,这两者对于新任务来说都是不切实际的。在这次演讲中,我展示了经过预训练的大型语言模型(LLMs)通过递归地批评和改进输出,能够在MiniWoB(一个流行的计算机任务基准测试)上达到最先进的性能。然后,我论证了基于强化学习的人类反馈(RLHF)是提高LLM智能体的一个有前景的方法,并介绍了通过受限制的强化学习来对抗RLHF中过度优化的新工作。
简历:Stephen McAleer是卡内基梅隆大学与Tuomas Sandholm合作的博士后。他的研究导致了第一个解决魔方的强化学习算法以及第一个在斯特拉特战略游戏上达到专家级表现的算法。他的工作已发表在《科学》、《自然机器智能》、ICML、NeurIPS和ICLR等杂志上,并被《华盛顿邮报》、《洛杉矶时报》、《麻省理工科技评论》和《福布斯》等新闻媒体报道。他在加州大学尔湾分校获得了计算机科学博士学位,导师是Pierre Baldi,此前在亚利桑那州立大学获得了数学和经济学学士学位。



成为VIP会员查看完整内容




相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
152+阅读 · 2023年3月29日

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
152+阅读 · 2023年3月29日