
近日,数据挖掘顶级会议KDD 2020发布论文接收结果,其中Research Track共1279篇论文参与投稿,仅216篇论文入选,接收率约为16.9%; Applied Data Science track共756篇论文投稿,仅121篇论文入选,接收率约为16.0%。百度AI凭借领先的行业技术实力,成功入选论文10篇,成为全球科技企业中入选论文数量最多的公司之一,彰显了百度AI行业领军者的领先地位。

ACM SIGKDD国际数据挖掘与知识发现大会(简称 KDD),由 ACM 于1995年创办,是世界数据挖掘领域的顶级学术会议,有数据挖掘领域“世界杯”之称,是目前AI领域影响力最广、规模最大的国际顶级会议之一。 虽然这次KDD 大会入选论文竞争激烈,百度AI在KDD 2020上依然斩获佳绩,成功入选的论文涵盖智能交通、智能推荐、图神经网络、知识图谱、人机交互、科学防疫等领域,全面展现百度AI深厚的技术底蕴与持续的创新实力。
以下为百度KDD 2020 十篇入选论文的亮点集锦:
论文1:Understanding the Impact of the COVID-19 Pandemic on Transportation-related Behaviors with Human Mobility Data
关键词:COVID-19,公众出行方式,流行病控制,大数据助力科学防疫
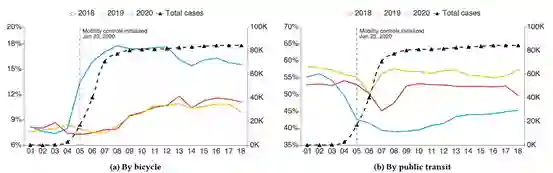
中国对新冠疫情(COVID-19)的成功遏制为有效抗击高度传染性病毒树立了典范。新冠疫情在中国的短时间传播和亚指数级增长,证明所采取的多项防疫措施,例如病例隔离、旅行限制、关闭娱乐场所、禁止大规模聚集等防疫措施都取得了极其显著的效果。这些防疫措施在有效遏制新冠病毒传播的同时,也有可能带来公众出行模式的变化。 为更好了解新冠疫情对公众出行模式的影响,并据此为政府、机构以及个人提供更具针对性的防疫建议,百度地图基于海量出行数据研究了新冠疫情期间公众在交通行为方面的变化。具体地,百度从公众的出行方式、出行目的地类型、到达时间、出行距离以及“出发地-出行方式-目的地”等5个不同的角度对新冠疫情期间的公众交通行为大数据进行了详细分析,并基于统计结果给出了相应的数据解读和防疫建议。鉴于新冠疫情仍在200多个海外国家与地区蔓延并导致全球数百万人受到感染,论文提供的数据解读和防疫建议有可能为抗击新冠疫情提供点滴之力。本文已被Health Day @KDD 2020 - AI for COVID所录用。
论文2:Personalized Prefix Embedding for POI Auto-Completion in the Search Engine of Baidu Maps
关键词:前缀联想式地理位置检索,POI自动补全,POI富内容编码,语义神经网络
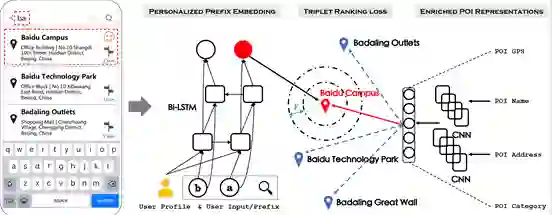
Point of Interest Auto-Completion(简称POI-AC),即前缀联想式地理位置检索,是地图POI搜索引擎中必不可少的功能。当用户在搜索框中键入每个字符时,POI-AC模块会自动根据用户输入的前缀动态地给出一系列POI建议。该功能有助于大幅减少用户搜索时的输入量,在屏幕小且输入较为费力的移动设备上尤其有用。目前的POI-AC模块主要采用宽泛的特征工程并结合Learning to Rank模型进行推荐结果计算。然而,基于宽泛特征和搜索历史很难直接对用户输入习惯进行建模,因此在输入前缀较少的情况下往往无法将用户想要的POI推荐至首位。 为解决上述问题,百度提出一种基于神经网络的端到端POI-AC框架,它已成功部署在百度地图的POI搜索引擎中。为建立用户画像、个人输入习惯以及对应被点击的POI之间的联系,专门设计了包含三个核心组件的POI-AC框架(简称P3AC,如上图所示)。百度团队使用百度地图的大规模真实搜索日志来评估P3AC的算法效果,并通过部署上线后的用户满意度指标对模型的实际产品效果进行了验证。实验结果表明,新方法在算法效果与用户满意度上均取得了显著提升。
论文3:ConSTGAT: Contextual Spatial-Temporal Graph Attention Network for Travel Time Estimation at Baidu Maps 关键词:ETA,通行时间预估,路线耗时预估,时空图网络
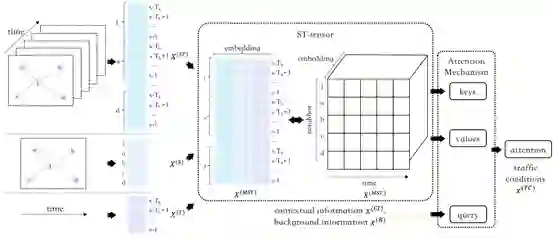
路线耗时预估任务旨在为给定的路线和出发时间估算出对应的通行时间。路线耗时预估任务在智能交通系统(例如导航、路线规划、网约叫车服务等)有着至关重要的作用。该任务面临诸多挑战,尤其是路况预测和道路链接信息。首先,路况预测的准确率和路段的历史路况强相关。现有的工作主要使用时空图神经网络改善路况预测的准确率。然而,这些工作将时间信息和空间信息独立对待,很少考虑时间和空间的关联性。其次,路线的道路链接信息(例如是否拐弯等)也会对用户的驾驶速度带来较大影响。之前的工作主要使用序列化结构去建模路线的道路链接信息。然而,序列化建模方式很难适用于大规模真实服务。 为更有效地解决路况预测和道路链接信息建模问题,百度提出了一个端到端的神经网络框架ConSTGAT。百度研究团队还提出了一个新颖的时空图神经网络,并专门设计了一种能够捕捉时间信息和空间信息之间协同关系的特殊注意力机制。此外,为更高效地利用道路链接信息,设计了一种高效计算模型,该模型基于路线的局部窗口以及卷积结构捕捉道路链接信息,并使用多任务学习同时利用路线和路段信息进行计算。基于上述模型设计,可提前并行预估每个路段的通行时长。在大规模真实数据集上的实验结果表明ConSTGAT的效果显著超过多个强健的基线模型。此外,ConSTGAT已成功部署于百度地图中,为每天数百亿的路线耗时请求提供了稳定的预估服务,这表明ConSTGAT是一个具有高可用性的路线耗时预估工业级解决方案。
论文4:Combo-Attention Network for Baidu Video Advertising 关键字:跨模态,短视频,搜索广告
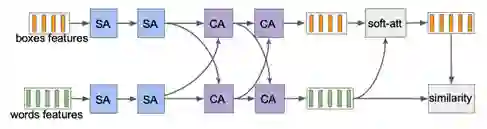
视频广告可以迅速捕捉用户的注意力,相对于传统静态广告,视频广告可以为用户留下更深刻的印象。因此广告主会投入更多的资源去制作视频创意来拉进和用户之间的距离。百度作为最大的中文搜索引擎公司,每天都会收到数十亿的搜索请求。 论文介绍了百度视频广告是如何根据用户搜索来匹配对应的视频广告的。根据用户的文本搜索来匹配视频广告本质上是一个跨模态搜索问题。因为模态间的鸿沟,跨模态搜索比经典的以文搜文和以图搜图都更有挑战性。为此,百度研究团队提出了混合注意力网络(CAN),并在百度动态视频广告平台上线。混合注意力网络不仅融合了模态内的注意力并且嵌入了跨模态的注意力。为了验证CAN的有效性,建立了一个包含70万好看视频的Daily700K 数据集。在Daily700K数据集和VATEX公开数据集上,CAN都取得了领先的搜索效果。在百度的动态视频广告平台上线后,CAN取得了5.47%的CVR提升。
论文5:Intelligent Exploration for User Interface Modules of Mobile App with Collective Learning 论文链接:http://zhoujingbo.github.io/paper/kdd2020_intelligent_zhou.pdf 关键词:智能界面设计,人机交互,协同学习
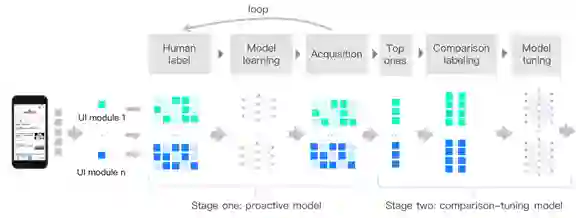
手机移动App的整体界面通常是由若干个界面模块组成的。如何合理的设计每个界面模块是提高移动App用户体验的一个关键步骤。在实际的界面设计过程中,界面模块关键参数的决定往往依赖于设计师的主观判断,而关键参数变动带来的实际影响只有通过线上小流量测试的方式来确定,需要花费很大的时间和人力成本。通常只有很少量的设计方案有机会进行线上实验测试。考虑到每个界面模块都有众多参数排列组合形成的接近无穷多个设计方案,在实际应用几乎不可能通过这种事后验证的方式来找到每个界面模块的最优设计方案。 论文中,百度提出了一个名为FEELER的模型框架。该框架通过协同学习的方式来快速和智能化的探索用户界面模块的最优设计方案。同时FEELER还能够帮助设计师量化的分析不同界面模块设计方案的优劣,从而帮助设计师快速便捷的调整和优化手机App的主要界面模块。作为中国最大的手机移动App之一的百度App,为FEELER提供了测试数据和应用场景来验证FEELER的有用性。
论文6:Polestar: An Intelligent, Efficient and National-Wide Public Transportation Routing Engine 论文链接:https://arxiv.org/abs/2007.07195 关键词:公交,路线规划,情境感知排序,推荐
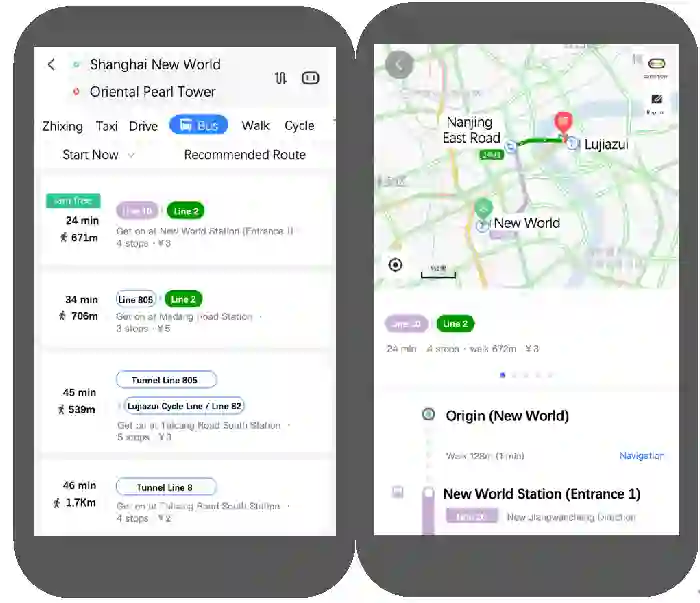
公共交通在居民日常生活中扮演了重要的角色。相较于其他形式的交通,公共交通更加环境友好、高效且具有性价比。但是,面对不断扩展的交通网和日益复杂的出行场景,用户通常很难轻易地确定最合适的出行方案。 为此,论文提出Polestar,一个智能且高效的数据驱动公交路线引擎。特别地,百度首先提出了一个新的公交图来建模公交系统中多种出行开销,如时间或距离。此外,引入高效的站点绑定策略和通用的路线搜索算法来生成候选路线。之后,百度团队还提出一个两轮的排序模块捕捉用户在不同情境下的出行偏好。最后,在两个真实数据集上的实验结果证明了Polestar的有效性。在2019年初,Polestar就已经被部署在了百度地图上。现在,Polestar服务着全国超过330个城市,每天相应数千万路线规划请求,并获得了显著的点击率提升。
论文7:Geodemographic Influence Maximization 论文链接: http://zhoujingbo.github.io/paper/kdd2020_geodemographic_zhang.pdf 关键词:空间用户影响力最大化,子模最优化,神经网络近似算法,户外广告营销算法
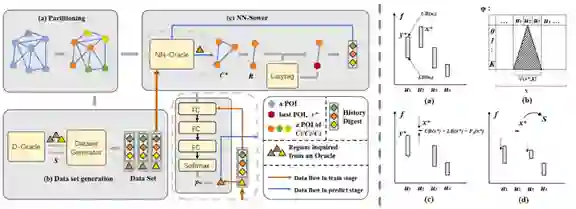
给定城市中一系列的地点,广告主应该在哪些地点投放户外广告,使得在不超过预算的情况下触达尽可能多的人?为了解决这个问题,过去的研究主要基于“用户是否被某广告影响取决于一个预定义的用户轨迹集合”。然而,在大多数的现实应用场景中,预定义的用户轨迹集合是很难被获取的;但是通过统计人群行为数据而计算出来的不同地点之间的人群转移概率图,则通常比较容易获取。本文解决了一个基于下述设定的一个一般性问题:给定人群在地点间的分布和人群在地点与地点间的转移概率图,在预算内选择若干个地点组成的集合,使得人群到达这些地点的期望次数最大化。百度研究团队将这个问题叫做空间用户影响力最大化问题(Geodemographic Influence Maximization,简称GIM)。 论文首先证明GIM是NP-hard的问题,但其目标函数是单调并且子模的,因此存在一个贪心策略的算法可以使效果达到理论最优解的1/2(1-1/e) 比例。然而,这个贪心算法的时间复杂度仍然太高,限制了它在大规模数据上的可用性。论文利用GIM问题的转移图上的空间临近性等特点,提出了一个比贪心算法更加快速有效的确定性算法(称作Lazy-Sower)。同时,本文进一步提出了一个基于机器学习的随机算法(NN-Sower)。NN-Sower在轻微减少效果的条件下可以大幅提高计算速度。在两个城市的真实数据集上的实验证明了新算法比基准算法具有更好的效果和速度。
论文8:Competitive Analysis for Points of Interest 论文链接:http://zhoujingbo.github.io/paper/kdd2020_competitive_li.pdf 关键词:兴趣点竞争分析,空间自适应图神经网络,POI知识图谱,异质信息网络
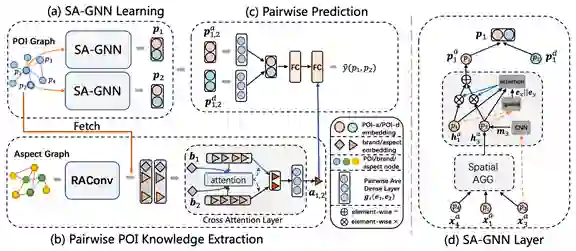
兴趣点(Point of interest, POI)竞争关系可以衡量城市中两个POI(如餐馆、酒店、游乐场等)为了争取足够多的资源(主要是用户)而产生的竞争的强弱。已有的竞争关系分析的研究主要聚焦于从文本数据中挖掘企业或者商品等实体之间的竞争行为,而很少关注POI之间的竞争关系分析。大量关于POI的用户行为数据(如评论数据和地图搜索数据)的出现为POI的竞争关系分析提供了可能。 论文中,百度首先使用POI评论和地图搜索数据构建了一个异构的POI信息网络(HPIN)。同时,百度提出一种基于图神经网络的深度学习框架DeepR。该框架由空间自适应图神经网络(SA-GNN)和POI知识抽取模型(PKE)两个部分组成。SA-GNN具有面向空间的聚合操作和基于空间依赖的注意力机制等特殊结构,可以有效结合POI的空间信息和位置分布对POI的表征进行学习。同时,PKE利用关系图卷积计算和交叉注意力网络提取HPIN中的有关POI的知识特征。在两个真实数据集上的实验结果证明了DeepR的有效性。
论文9:Local Community Detection in Multiple Networks 论文链接:http://personal.psu.edu/dul262/RWM/RWM.pdf GitHub链接:https://github.com/flyingdoog/RWM 关键词:局部社区发现算法,多层图结构,随机游走
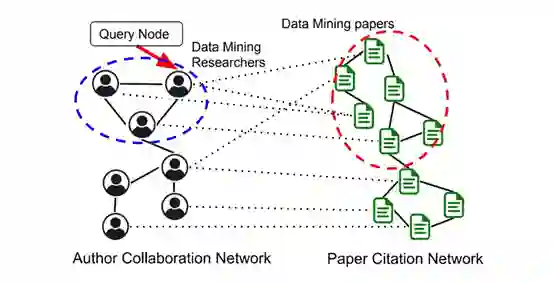
局部社区发现旨在找到一组包含给定查询节点的密集连接节点集(局部社区)。大多数现有的局部社区发现方法都是为单个图结构设计的。但是,单个图可能包含噪声与干扰数据且信息不完整。相比之下,多个相关的图结构在实际应用中能够提供更多的信息。在多个相关的图结构中,有多种类型的节点和多种类型的节点连接关系。来自不同图的补充信息有助于提高局部社区发现的准确性。 论文中,百度提出了一个新的多图中的随机游走模型 (RWM)。给定一个图中的查询节点集,RWM能够查找所有图结构中的相关局部社区。RWM 在每个图结构中都发出一个随机游走者以获得相对于查询节点的相似度度量(即节点访问概率)。具有相似访问概率的游走者会彼此影响。新方法可以将概率传播限制在查询节点的局部范围,以标识每个图结构中的相关子图。与此同时,RWM能够忽略多图中不相关的部分。百度为 RWM提供了严格的理论基础,并开发了两种具有性能保证的加速策略。百度研究团队在合成和真实数据集上进行了全面的实验,验证了RWM的有效性和高效率。
论文10:Dual Channel Hypergraph Collaborative Filtering 关键词:协同过滤,双通道,超图
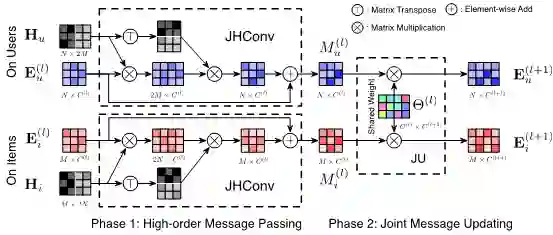
协同过滤是当今众多推荐系统算法中最流行和最重要的推荐方法之一。现有的基于协同过滤的算法,从矩阵分解到最近出现的基于图的方法,虽然已经得到了广泛的应用,但在训练数据有限的情况下性能较低。论文中,百度研究团队首先指出导致性能较差的原因,即:(1)用户和物品建模不灵活;(2)高阶关联建模不足。 在这种情况下,百度提出了一个双通道超图协同过滤框架来解决上述问题。首先,引入了一种整体利用分治思想的双通道学习策略,来学习用户和物品的表示,以使得这两种类型的数据可以优雅地相互连接,同时仍然保持它们的特定属性。其次,使用超图结构来显式建模混合高阶用户和物品的高阶关联。百度研究团队进一步提出了跳跃超图卷积方法来支持超图上显式、高效的嵌入传播。在两个公开数据集和两个新的真实数据集上的综合实验表明,与其他先进的方法相比,百度所提出的双通道超图协同过滤方法可以取得显著且一致的性能提升。


