

Segment Anything模型(SAM)是图像分割任务中的一个基础模型,以其在多种应用中的强大泛化能力而闻名。然而,其出色的性能伴随着较高的计算和资源需求,因此在移动设备等资源受限的环境中部署具有一定挑战性。为了解决这一问题,研究人员提出了多种SAM变体,旨在提高效率的同时保持准确性不变。本综述首次全面回顾了这些高效的SAM变体。我们首先探讨了推动该研究的动机,然后介绍了SAM的核心技术及模型加速方法。接着,我们对不同加速策略进行了深入分析,并根据方法对其进行分类。最后,我们对这些方法进行了统一且详尽的评估,在代表性基准测试上评估其效率和准确性,并清晰地比较了其整体性能。
1. 引言
基础模型的出现【8】彻底革新了人工智能(AI)领域。基础模型是基于大规模数据预训练的神经网络,具有强大的表示能力和广泛的泛化能力,能够执行各种任务。在自然语言处理(NLP)领域,当前的研究趋势集中于大型语言模型(LLMs)【116, 160】,其中包括OpenAI的GPT系列【1, 9】、谷歌的PaLM系列【3, 21】和Meta的LLaMA系列【111, 112】,这些模型均取得了显著的发展。同时,ViT(Vision Transformer)【29】的成功标志着视觉基础模型(VFMs)新时代的开启。ViT首次将Transformer【115】架构引入计算机视觉(CV)领域,开创了视觉-语言基础模型如CLIP【89】、LLaVA【67】和Video-ChatGPT【79】等的发展,这些模型在大量下游视觉任务中展示了出色的表现【34, 58, 110, 167】。
最近,Meta提出了一种新的通用图像分割基础模型,即Segment Anything模型(SAM)【55】。该模型在其提出的SA-1B数据集上进行了全面训练,该数据集包含十亿多个掩码和一千一百万张图像,能够在给定任意提示(如点、框、掩码和文本)的情况下实现有效分割。SAM具有广泛的下游任务泛化能力,如边缘检测、目标提议和实例分割等【14, 15, 78】。SAM的推出迅速引起了研究界的广泛关注,导致了大量研究工作探索其在各种场景中的泛化能力【2, 57, 95, 130】,包括不同的图像分割任务【42, 76, 137, 154】、视频分析任务【28, 100, 134】以及3D视觉任务【70, 99, 113, 135, 140】。随着SAM的巨大成功,升级版的Segment Anything Model 2(SAM 2)【93】进一步被提出,旨在提高图像和视频分割的效率。SAM 2引入了流式内存机制以扩展其在视频中的应用能力,并在SA-1B数据集和新收集的视频分割数据集SA-V上进行了训练,因此在处理分割任务时具备了强大的泛化能力并超越了SAM。
尽管在广泛的应用中取得了成功,原版SAM,尤其是SAM-H,因运行时间较慢和计算成本高而面临显著的局限性。这些挑战在资源受限或实时环境(如边缘设备和移动应用)中更加明显。随着在资源受限的实际场景中部署机器学习模型的需求不断增长,SAM当前的设计对广泛应用来说并不高效。这使得在保持其强大分割能力的同时,研发更轻量高效的变体以应对这些限制成为迫切需要。随着对实时应用、移动平台和嵌入式系统的关注不断增加,这一优化SAM的效率的挑战也在加剧【18, 77, 103, 114, 118, 147, 161, 164】。因此,全面理解如何使SAM更高效的最新进展是至关重要的。鉴于与SAM相关的研究日益增多,已有几项综述从不同角度对其进行了概述【149–152, 155, 157】。然而,这些综述主要关注于SAM的下游应用,并存在以下不足:1)没有专门探讨如何提升SAM的效率,这一领域正在获得显著关注并且对于实际应用至关重要。2)除了【151】,这些综述缺乏清晰的分类结构,难以为读者提供明晰的组织和参考。3)多数综述侧重于收集和描述基于SAM的方法,缺少对这些方法的系统评估和比较。为弥补这些不足,我们开展了本次综述,既全面回顾了高效SAM的最新进展,又对其进行公平的评估与比较。
本文主要贡献
-
我们系统性地回顾了为加速分割任务而设计的高效SAM变体,并提出了一个结构良好的分类体系,将这些方法按其加速策略进行归类。据我们所知,这是首个专门针对该领域的综述。
-
我们提供了这些变体在效率和准确性方面的全面评估和比较,旨在帮助研究人员选择最符合其性能和应用需求的模型。
-
我们提出了若干未来研究方向,为读者提供见解,激励更多人对该领域的持续进步做出贡献。 本文其余部分的结构如下:第二节中,我们首先介绍原始SAM的背景,随后回顾用于视觉表示的高效骨干网络以及提升SAM效率的模型压缩技术。在第三节中,我们基于目标和技术对现有方法进行了分类,详细回顾了各个类别的方法,并讨论了加速SAM的潜在研究方向。第四节中,我们对这些模型在效率、准确性及其权衡关系方面进行了公平的评估。最后,在第五节中,我们对本综述进行了简要总结。
2. 预备知识
在本节中,我们将首先介绍Segment Anything模型(SAM)的细节及其应用(2.1节)。接下来,回顾可以替换SAM图像编码器的高效主干网络(2.2节),以及可能应用于SAM的模型压缩技术(2.3节)。对于高效主干网络和模型压缩方法的更全面理解,建议参考综述文献【86, 132】。
**2.1 Segment Anything模型
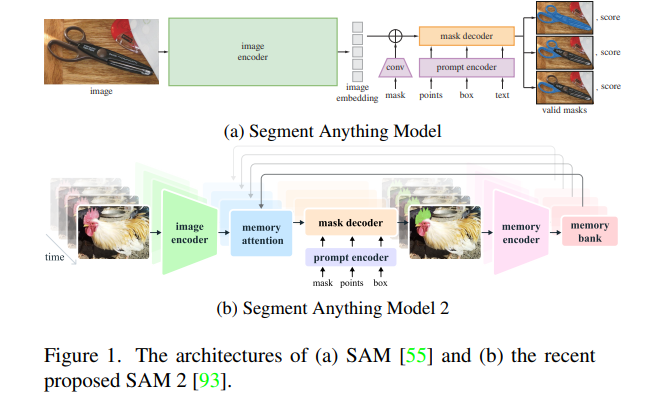
Segment Anything模型(SAM)【55】是图像分割领域的一个强大基础模型。该模型的特点在于能够通过提示工程(prompt engineering)实现可提示分割任务,从而统一大多数图像分割任务。SAM模型的另一个重要贡献是SA-1B数据集,其中包含超过10亿个掩码和1100万张已获授权并保护隐私的图像。通过这样庞大的高质量数据进行训练,SAM具备了强大的鲁棒性和泛化能力。SAM的巨大潜力迅速引起了研究人员的兴趣,推动他们在多个实际应用中探索SAM的能力,并改进其架构以实现更高效或更精确的分割。最近,Segment Anything Model 2(SAM 2)【93】作为其继任者被提出,旨在提高图像和视频的高效可提示视觉分割(PVS)能力。为了使SAM 2能够在视频中实现分割,研究人员将流式记忆机制引入SAM的原始架构。SAM 2通过两个阶段从头开始训练:1)在SA-1B数据集上进行图像的可提示分割任务预训练;2)在混合数据上进行图像和视频的可提示分割任务训练。研究人员还构建了一个数据引擎,生成一个大规模的视频分割数据集,命名为SA-V数据集。该数据集最终收集了50.9K个视频中的642.6K个掩码片段。在本综述中,SAM 2被视为一种高效SAM变体,并纳入评估和比较。
**2.1.1 模型结构
SAM由三个组件组成:图像编码器、提示解码器和掩码解码器,如图1(a)所示。图像编码器是一个经过MAE【44】预训练的视觉Transformer(ViT),经过少量修改。它接收预处理后的图像作为输入,并为每个图像输出一个图像嵌入。提示解码器用于嵌入提示信息,如点、框、掩码和文本。然后,这两个嵌入输入到轻量级掩码解码器中,该解码器基于两个经过修改的Transformer解码器块【115】和一些预测头,生成有效掩码。基于SAM的架构,SAM 2额外引入了流式记忆机制,包括一个记忆编码器、记忆库和记忆注意力模块。SAM 2的结构如图1(b)所示。通过记忆机制,SAM 2可以逐帧处理视频。
**2.1.2 任务类型
可提示分割任务被提出为SAM的基础任务,其目标是在给定任何提示(例如点、框、掩码、文本)的情况下返回有效掩码。这不仅是SAM训练过程中的目标,也是使SAM能够解决各种下游任务的基础。另一个重要任务是全掩码生成,它通过网格化的点提示,生成图像中的所有对象的掩码。这两个任务总结了SAM的分割能力,并引导了提高SAM效率的两个研究方向。在本综述中,我们将沿用这两个定义,探索基于SAM的高效变体在SegAny和SegEvery任务中的性能。
**2.1.3 应用领域
SAM及其后继者SAM 2在许多零样本下游任务中展示了强大的泛化能力【55, 93】。其中一个主要应用领域是医学图像分割。根据文献【157】,在这一领域的工作可以分为两类:一类旨在测试SAM在CT图像【46, 95】、MRI图像【82】、病理图像【25】等方面的分割性能;另一类则专注于通过微调【64, 78】、自动提示【48, 98】或框架修改【156】来改进SAM对这些任务的适应性。此外,像【35, 57】这样的工作试图提高医学SAM方法的效率。SAM还应用于包括裂缝检测【2】、坑洞检测【36】、农作物疾病和害虫检测【63】、异常检测【11】以及遥感【85, 119】等多种现实场景中的目标检测任务。
2.2 高效主干网络
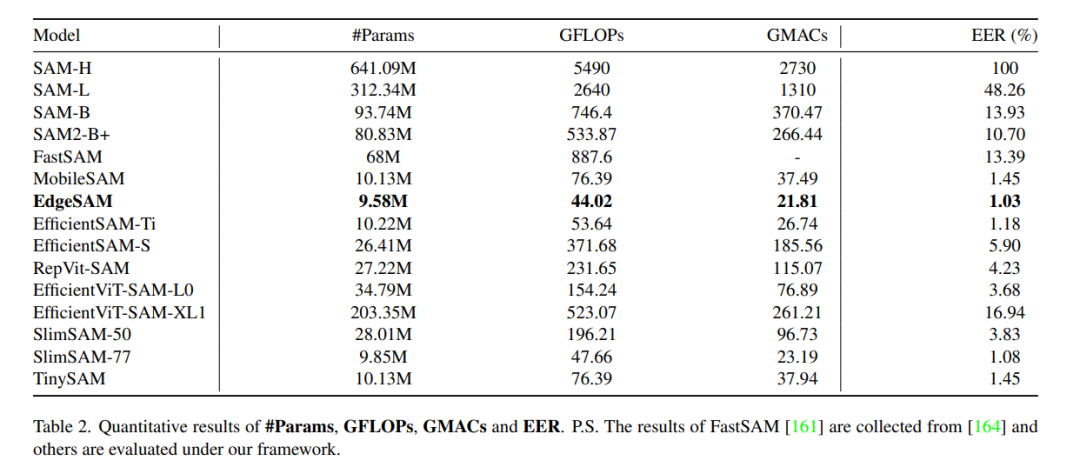
Segment Anything模型(SAM)效率低下的主要原因在于其庞大的图像编码器。表1详细列出了SAM的图像编码器大小,SAM整体参数量将在4.1节进一步估算。以SAM-H为例,其ViT-H图像编码器包含约632M个参数,占据模型总参数量的大部分。即使在最小的变体SAM-B中,图像编码器仍然占总参数量的90%以上。因此,加速SAM的一个直接有效的方法是使用更高效的主干网络替换大规模的图像编码器。这些高效主干网络包括纯卷积神经网络(CNN)如【43, 94, 117】,高效视觉Transformer架构如【10, 61, 127】,以及最近的一些替代Transformer的模型如【87】。
**2.2.1 高效视觉Transformer
改进视觉Transformer(ViT)效率的方法主要可以分为两类:1)设计更高效的结构;2)重构注意力机制。从结构角度降低计算成本的一个早期尝试是MobileViT【80】,它创新性地将CNN块(MobileNetV2块【97】)和Transformer块融合在一起,形成一个混合模型。之后的研究如【10, 62, 127】基本上沿用了这一思路,构建了具有混合结构的高效ViTs,并被广泛用于替代SAM的重型图像编码器。例如,TinyViT【127】被用作【103, 161】的高效主干,而EfficientFormerV2【62】和EfficientViT【10】则分别在【162】和【159】中取代了SAM的原始图像编码器。MetaFormer【142】是另一种具有影响力的ViT设计,它将注意力机制抽象为“token mixer”,并使用更简单的池化操作作为token mixer,形成了一个轻量级的基础架构,用于开发Lite-SAM【33】的图像编码器。在优化注意力机制方面,研究人员也取得了显著进展。注意力机制中的softmax操作对整体计算成本影响较大。在EfficientViT【10】中,提出了一种ReLU线性注意力机制,能够在硬件友好的情况下实现全局感受野。这种高效主干网络还被应用于【159】来加速SAM。此外,在硬件级别的改进如FlashAttention【23】中,通过操作融合、内核重计算等技术,显著降低了计算成本,并在【101, 104】等工作中用于减少内存需求并提升计算效率。
**2.2.2 Transformer替代模型
尽管Transformer在视觉和语言领域都占据主导地位,一些新提出的模型在效率和性能方面显示出超越它们的潜力。Receptance Weighted Key Value(RWKV)模型【87】结合了循环神经网络(RNN)和Transformer的优势,实现了线性时间复杂度。RWKV适合处理长序列挑战,通过引入WKV操作和输出门机制替代传统的二次复杂度的注意力机制。RWKV还被扩展到视觉任务中,Vision-RWKV(VRWKV)模型【30】在视觉任务中表现出与ViT相当的性能但效率更高。为了将RWKV从1D序列适配到2D图像,使用了Q-shift tokens来融合邻域信息。在【145】中,RWKV-SAM利用这种高效主干网络,使用MobileNetV2和VRWKV块的混合结构,显著提高了SAM的效率。综上所述,为了减小模型规模并提高计算效率,可以考虑使用这些高效视觉Transformer和替代模型来替换SAM的图像编码器。通过这些优化,SAM的整体性能可以在不显著牺牲准确性的前提下得到提升。
2.3 模型压缩
模型压缩是一系列旨在减少模型大小和计算复杂度的技术,这对于在计算资源有限的实际应用中部署大型模型至关重要。模型压缩和加速的四种主要方法是知识蒸馏、量化、剪枝和低秩分解。
**2.3.1 知识蒸馏
知识蒸馏(Knowledge Distillation,KD)【45】最初被引入用于在资源受限的环境中部署大型复杂的神经网络。其核心概念是将大规模、经过充分训练的教师模型(teacher model)的知识和表示能力传递给更小、更高效的学生模型(student model)。在加速SAM方面,知识蒸馏的目标是从原始的大规模SAM中提取知识,并将其传递给更高效的SAM变体模型。考虑到SAM的编码器-解码器结构,知识蒸馏大致可以分为两种方法:仅蒸馏图像编码器,或对整个模型进行蒸馏。大多数研究【84, 103, 117, 147, 159】集中在仅蒸馏高效主干网络,而保留SAM的原始提示解码器和掩码解码器。然而,一些方法如【162, 164】则旨在通过对编码器和解码器的输出进行监督,从而对整个模型进行蒸馏。
**2.3.2 量化
量化是将模型的高精度权重和激活值(例如32位浮点数)转换为低精度格式(例如16位浮点数或8位整数)的过程。常用的量化方法之一是对称均匀量化,公式如下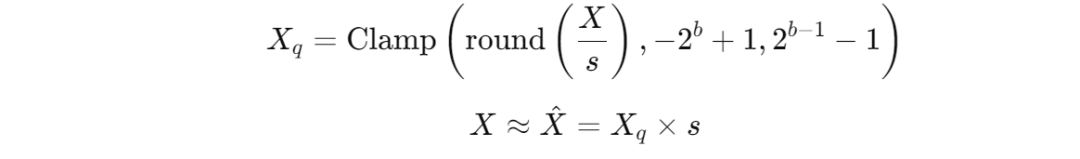
**2.3.3 剪枝
剪枝通过移除冗余权重或连接来减小模型的规模和复杂性,同时尽可能保持精度。剪枝方法通常分为两类:结构化剪枝和非结构化剪枝。结构化剪枝【4, 123】基于特定准则成组地移除参数,系统性地针对通道、层或块等子结构进行操作。而非结构化剪枝【16, 56】则更侧重于单个权重,导致网络稀疏且片段化。虽然非结构化剪枝可能不会有效加速通用硬件,但由于其灵活性,常用于定制化硬件加速。在【18】中,结构化剪枝用于轻量化SAM,通过移除大量冗余权重显著减少了模型规模,同时保留了SAM的大部分功能。
**2.3.4 低秩分解
低秩分解是一种将高维矩阵分解为低维矩阵的技术,旨在减少模型的参数以占用更少的空间并提高计算效率。常用的低秩分解方法是奇异值分解(SVD),它将复杂矩阵A∈Rm×nA \in \mathbb{R}^{m \times n}A∈Rm×n 分解为三个矩阵,其计算公式为:

3. 高效SAM变体
**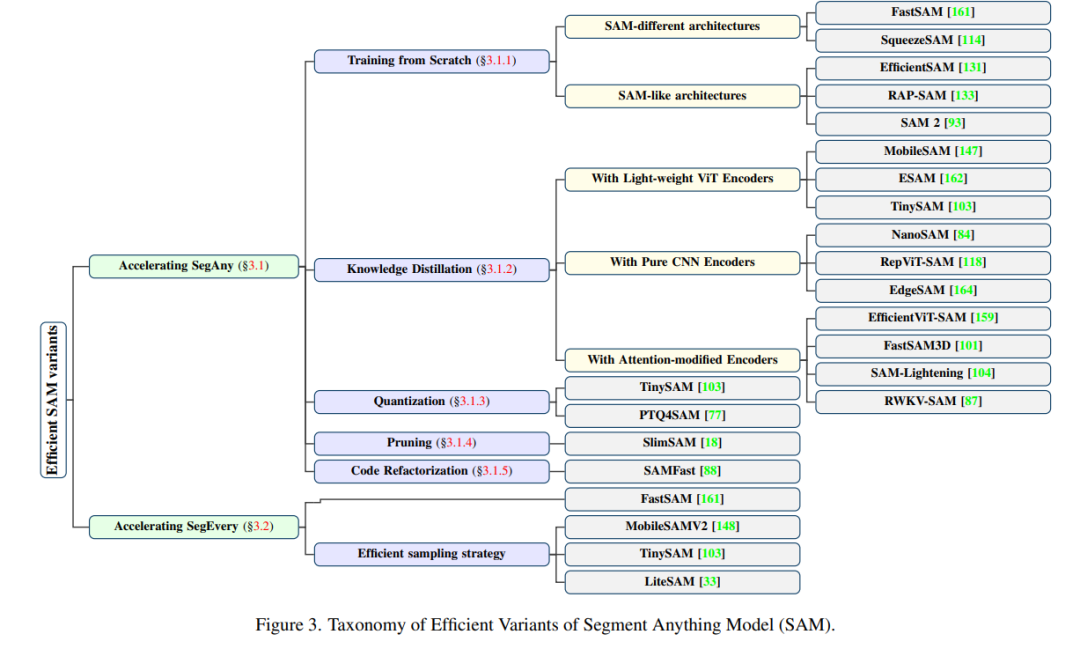
**3.1 SegAny任务的加速
SegAny任务的主要效率瓶颈在于SAM的重型架构。一个直接的解决方案是用更高效的主干网络替换编码器。此外,保留相同分割能力的不同架构也是一种可行方法。这些策略下的研究包括完全从头训练的轻量化模型(见3.1.1节)或采用合适监督方式的知识蒸馏方法训练模型(见3.1.2节)。另外,一些研究探索了量化、剪枝或局部优化等方法,以直接压缩SAM,而无需更换编码器或构建新架构。这些努力将分别在3.1.3节、3.1.4节和3.1.5节中回顾。3.1.1 从头训练该部分重点介绍完全从头训练的SAM变体模型。根据架构的不同,这些模型可以分为SAM不同架构和SAM类架构两种类型。我们将根据这一分类逐一探讨每种类型。例如,FastSAM【161】不依赖于SAM的原始编码器-解码器架构,而是将SegAny任务分为全实例分割和提示引导选择两个子任务。由于CNN方法在实例分割方面已经表现出色,因此FastSAM通过使用YOLOv8-Seg【53】模型实现更高效的分割。尽管FastSAM在某些方面仍有改进空间,例如在小物体分割和边界平滑方面,其在引入CNN架构后标志着该领域的重要进展。3.1.2 基于知识蒸馏的方法图3中展示的分类表明,许多方法利用了知识蒸馏,因为与完整模型训练相比,知识蒸馏通常需要更少的时间和资源。在这一节中,我们回顾了那些在图像编码器中采用高效主干网络并利用知识蒸馏进行训练的SAM变体模型。我们根据编码器类型将这些模型分为三类:采用轻量化ViT编码器的模型、纯CNN编码器的模型,以及注意力修改编码器的模型。例如,MobileSAM【147】通过将SAM的ViT-H替换为TinyViT【127】,显著提高了效率。此外,ESAM【162】则利用EfficientFormerV2【62】作为编码器,并引入整体知识蒸馏策略,将专业模型的知识传递给ESAM。3.1.3 基于量化的方法例如,TinySAM【103】在硬挖掘全阶段知识蒸馏后,对编码器进行后训练量化,从而进一步缩小模型规模并提高效率。研究人员使用后训练量化技术直接量化了SAM,以减小存储需求并提升计算速度。3.1.4 基于剪枝的方法SlimSAM【18】是首个通过有效剪枝策略减少SAM模型规模和复杂性的模型。该方法利用结构化剪枝系统地移除不必要的参数,并在不显著影响性能的前提下提高了效率。3.1.5 代码重构PyTorch团队开发的Segment Anything Fast模型(SAMfast)【88】是SAM的重写版本,采用了PyTorch的原生优化策略,使其速度提高了8倍且几乎不损失精度。代码重构通过引入半结构化稀疏性和低精度计算等方式有效减少了计算量。
**3.2 SegEvery任务的加速
对于SegEvery任务,Zhang等人【148】提出了一种基于对象感知的提示采样策略,从而提高采样效率。MobileSAMv2通过使用YOLOv8模型来识别潜在对象,从而减少了密集采样策略所需的计算量。这种方法提高了效率且保留了良好的分割效果。此外,Shu等人【103】提出了分层采样策略,通过两轮采样逐步选择掩码生成的最优点,显著减少了计算成本。该策略在细化分割时保持了时间效率和分辨率。
**3.3 未来研究方向
本综述回顾了加速SAM的当前进展,但仍有进一步研究的空间。未来的研究可以探索先进架构、稀疏性和加速技术、硬件特定优化以及高效视频和多模态数据分割,以进一步提升SAM的效率和适用性。
4. 评估
在本节中,我们系统地比较了前面描述的SAM变体的效率和精度。参考这些工作的实验,我们选择了大多数研究所涉及的任务,并在常用的数据集上使用相应的指标对其进行评估。所有评估均在单块24GB的RTX 3090 GPU和14核的Intel Xeon Gold 6330处理器(主频2.00GHz)上进行。以下小节提供了更多详细信息:4.1节介绍了用于评估的数据集和指标;随后的节中将展示各变体的效率和精度对比。
**4.1 数据集和指标
我们选择了COCO 2017【65】和LVIS v1【40】作为评估的数据集。COCO数据集是一个大规模数据集,设计用于目标检测、分割和图像标注任务,包含了33万张图像和150万个对象实例,涵盖80个对象类别。LVIS数据集专为大词汇量实例分割任务设计,包含了超过200万个高质量分割掩码,覆盖1200多个类别,共有16.4万张图像。 在评估中,我们使用了COCO和LVIS的验证集:COCO验证集包括5000张图像中的36,781个实例,LVIS验证集包括19,809张图像中的244,707个实例。为评估效率,我们首先测试了一些软指标,如参数数量、浮点运算量(FLOPs)、乘加运算量(MACs)和内存使用量。此外,我们还计算了效率误差率(Efficient Error Rate, EER),这是一个更为综合的评估指标【86】。EER定义如下: EER=1N∑i=1N(MiRi)\text{EER} = \frac{1}{N} \sum_{i=1}^{N} \left(\frac{M_i}{R_i}\right)EER=N1i=1∑N(RiMi) 其中,NNN 为指标数量,MiM_iMi 和RiR_iRi 分别表示被测模型和基准模型在第iii 个指标上的数值。在我们的评估中,将SAM-H作为基准模型。除了这些指标外,我们还报告了各模型的运行时间和吞吐量。 在精度评估方面,我们使用平均交并比(mIoU)评估SegAny任务,使用平均精度(AP)评估实例分割任务。
**4.2 效率对比
我们首先报告了SAM及其变体的效率对比结果。效率的各项指标——包括FLOPs、MACs、内存使用量和运行时间等——均在同样的硬件平台上进行,以确保测试条件的一致性。大多数轻量化变体模型都显示出了显著的效率提升,例如在COCO数据集上的测试表明,TinySAM的运行速度比原始SAM提升了30倍,且基本不损失精度。NanoSAM在Jetson Orin平台上的表现也比MobileSAM快5倍左右,而几乎没有显著的精度损失。
**4.3 精度对比
在精度方面,各变体在不同任务上都表现出一定的差异。MobileSAM和EfficientSAM等变体在SegAny任务上维持了较高的mIoU值,表现出与原始SAM相近的分割效果。而在SegEvery任务上,采用优化采样策略的MobileSAMv2与LiteSAM均实现了较好的AP值。尽管LiteSAM采用了轻量化的CNN-Transformer混合架构,但其多尺度池化模块和自动提示生成网络使其能够在效率提升的同时保持较高的分割准确性。
结论
在本次综述中,我们主要讨论并评估了针对降低资源消耗和延迟的高效SegAny和SegEvery任务的代表性工作。对于高效的SegAny任务,大多数研究采用替换图像编码器或整个架构为轻量化替代方案的方法,随后通过从头训练或知识蒸馏进行模型优化。其他工作则致力于利用量化、剪枝或局部优化等技术来压缩原始模型。对于高效的SegEvery任务,采用高效的采样策略来生成提示是至关重要的。在详细回顾这些方法之后,我们还概述了四个未来可能推动该领域新趋势的研究方向。
此外,我们在一致的环境下评估了这些模型的效率、精度及其对应的权衡,提供了一个公平且有价值的对比。分析结果表明,一些变体在特定场景中已超越了原始SAM,我们相信它们的成功将激励该领域的进一步探索与创新。