

配备先进传感器的无人平台的集成有望提高态势感知能力,缓解军事行动中的 “战争迷雾”。然而,管理这些平台涌入的大量数据给指挥与控制(C2)系统带来了巨大挑战。本研究提出了一种新颖的多智能体学习框架来应对这一挑战。该方法可实现智能体与人类之间自主、安全的通信,进而实时形成可解释的 “共同作战图景”(COP)。每个智能体将其感知和行动编码为紧凑向量,然后通过传输、接收和解码形成包含战场上所有智能体(友方和敌方)当前状态的 COP。利用深度强化学习(DRL),联合训练 COP 模型和智能体的行动选择策略。展示了在全球定位系统失效和通信中断等恶劣条件下的复原能力。在 Starcraft-2 模拟环境中进行了实验验证,以评估 COP 的精度和策略的鲁棒性。报告显示,COP 误差小于 5%,策略可抵御各种对抗条件。总之,贡献包括自主 COP 形成方法、通过分布式预测提高复原力以及联合训练 COP 模型和多智能体 RL 策略。这项研究推动了自适应和弹性 C2 的发展,促进了对异构无人平台的有效控制。
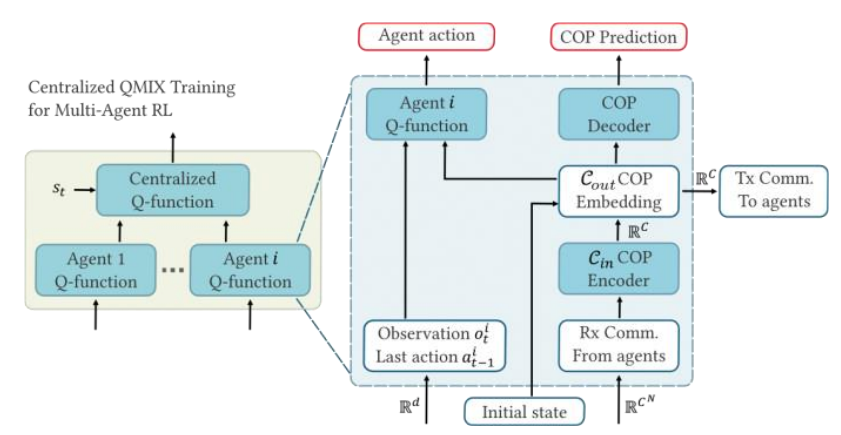
图:从学习到的交流中预测 COP 的框架概览。在决策过程中确定并使用 COP。使用 QMIX作为 COP 集成的 MARL 方法示例。
配备先进传感器的无人平台的集成为减轻 “战争迷雾 ”和提高态势感知能力带来了希望。然而,管理和传播来自此类平台的大量数据对中央指挥与控制(C2)节点的信息处理能力构成了巨大挑战,特别是考虑到随着平台数量的增加,数据量也会呈指数级增长。目前的人工处理方法不适合未来涉及无人平台群的 C2 场景。在本研究中,我们提出了一个利用多智能体学习方法来克服这一障碍的框架。
我们考虑的框架是,智能体以自主方式相互通信(以及与人类通信),并以数据驱动的方式训练这种通信功能。在每个时间步骤中,每个智能体都可以发送/接收一个实值信息向量。该向量是智能体感知或视场(FoV)的学习编码。这些向量不易被对手解读,因此可以实现安全的信息传输。
在接收方,必须对信息进行解码,以恢复发送方的感知和行动。此外,还应将信息整合(随时间汇总)到 “共同作战图像”(COP)中。与编码器一样,解码器也是以数据驱动的方式学习的。在本文中,我们将 COP 的定义简化为战场上每个友方和敌方智能体的当前状态(位置、健康状况、护盾、武器等)。我们认为,COP 对决策智能体至关重要。
近年来,以数据驱动方式进行端到端训练的人工智能/人工智能方法大有可为。在数据驱动型自主 COP 的背景下,一个优势是无需对传感器和执行器中的噪声、对手的动态等做出建模假设。通过充分的训练,我们的数据驱动方法将产生高度精确的 COP。
不过,ML 模型可能对训练数据或训练场景的偏差很敏感。这与陆军 C2 场景中通常假设的 DDIL(拒绝、中断、间歇和有限影响)环境形成了鲜明对比。我们的实验强调评估对雾增加、全球定位系统失效和通信中断(如干扰)的适应能力。
我们使用深度神经网络(DNN)的深度学习实现了编码器和解码器的数据驱动端到端训练。将 DNN 应用于 COP 形成的一个挑战是通信中缺乏人类可解释性。人类可解释性对于人类操作员有效控制蜂群至关重要。例如,通过解释通信,操作员可以理解蜂群用于(自主)决策的特征。我们的方法具有人机互换性,这意味着人类操作员可以解码传入的信息,并将自己的感知编码,与蜂群进行交流。由此产生的 COP 使人类能够指挥蜂群。
在实践中,COP 被大量用于任务执行,例如,确保协调运动。我们假设,将 COP 纳入自主决策智能体将产生弹性多智能体策略(例如,对敌方变化的弹性)。我们在实验中将有 COP 和没有 COP 的多智能体策略学习与多种最先进的方法进行了比较,并验证了这一假设。
接下来,我们总结一下我们的方法。我们首先描述了我们的深度学习方案,其中每个智能体将其感知和行动编码成紧凑向量并进行传输。各智能体共享底层嵌入向量空间,以实现对态势的共同理解。每个智能体都要训练一个编码器-解码器,以生成本地 COP。本地 COP 应与智能体的感知一致,并能预测行动区域内所有单元的状态(包括位置)。
在不同的模拟场景、初始部队配置和对手行动中,使用深度强化学习(DRL)对 COP 和智能体策略进行端到端训练。训练的输出是一个编码器-解码器神经网络(NN)和一个跨智能体共享的策略 NN。可通过多种方式对训练进行配置:最小化带宽、最大化对干扰(如信道噪声、数据包丢失、GPS 干扰等)的恢复能力。该方法可用于协调信息收集任务。
实验在星际争霸-2(SC2)多智能体环境中进行。在 SC2 中模拟的多个蓝方与红方场景中,通过经验观察了方法的有效性。具体来说,在具有挑战性和现实性的 TigerClaw 场景(图 1)中测试和评估了方法,该场景由 DEVCOM 陆军研究实验室(ARL)和陆军主题专家(SMEs)在美国佐治亚州摩尔堡的上尉职业课程中开发。
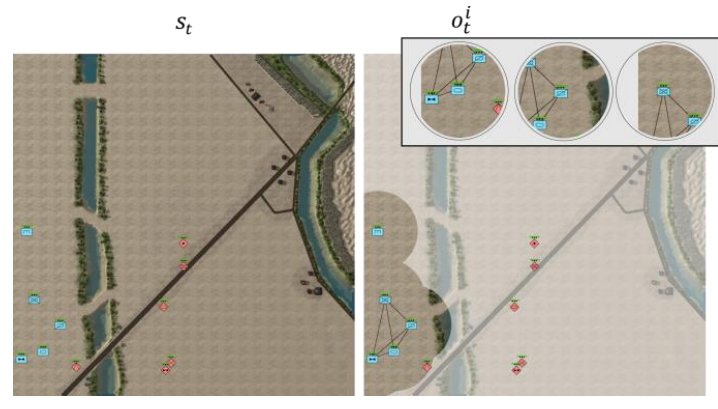
图 1:(左)Tigerclaw场景中的状态示例。(右)每个智能体的感知(本地观察)和它们之间的通信联系。
对 COP 的准确性和幻觉进行评估,以揭示有趣的训练动态。在整个模拟过程中,方法生成的 COP 高度准确,误差小于 5%(与地面实况相比)。为了测试策略的鲁棒性,我们将我们的方法与多种最先进的多智能体 RL 方法和基线进行了比较。结果表明,我们的方法所制定的策略能够抵御视觉范围下降、通信能力下降、GPS 被拒绝以及场景变化等因素的影响。
总之,这项研究通过数据驱动的 COP 形成,实现了人在环内的异构自主平台的指挥和控制,推动了自适应和弹性 C2 领域的发展。其贡献如下:
-
实时自主形成可解释的共同行动图像(COP)的方法,包括预测整个行动区域的敌方位置。
-
由于利用智能体间的通信进行分布式 COP 预测,因此展示了对可视范围和 GPS 拒绝的更强的应变能力。
-
通过联合训练 COP 模型和多智能体 RL 策略,提高整体任务成功率。

